AOS - 01 - HARDWARE INSIGHTS I
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 1/7
Table of Contents:
Appunti lezione ripresi da registrazione di Claudio dello stesso corso ma tenuto nell'anno scolastico 2018/2019.
In questo running example, disponibile qui, abbiamo discusso una possibile implementazione del Lamport's Bakery algorithm. L'algoritmo di Lamport viene utilizzato per sincronizzare l'accesso ad una risorsa condivisa da vari threads. A seguire ripotiamo la parte principale del codice
void* child_thread(void*p){ int me = (long)p; long max, i, got, num; while(1){ max = 0; // The thread starts to choose // his own ticket number. choosing[me] = 1; // To do this, it finds the highest // ticket-number choosen so far. for(i = 0; i < SPAWNS; i++){ if(max < numbers[i]) max = numbers[i]; } // and it picks the highest // ticket-number choosen so far + 1 num = numbers[me] = max + 1; choosing[me] = 0; for(i=0; i<SPAWNS; i++){ // wait for other threads // to choose their ticket number. while(choosing[i]) {}; // wait untill thread's ticket is highest one among all the // threads that still have to be served. while((numbers[i] != 0) && ((numbers[i] < numbers[me]) || ((numbers[i] == numbers[me]) && (i < me)))) {}; } // ------------ Start critical section ------------ got = tokens_to_distribute++; AUDIT printf("I'm child %d - number %d - done critical region with got set to %d\n", me, num, got); printf("%ld\n", got); //this output is requested for the overall test numbers[me] = 0; // ------------ End critical section ------------ if(end) pthread_exit(NULL); } }
Per funzionare correttamente, ogni ticket deve essere stampato una sola volta. In questo caso infatti avremmo che ogni thread prende un ticket diverso, ovvero non ci sono mai due thread che agiscono nello stesso momento nella sezione critica del codice.
Notiamo però che se eseguiamo questo codice, il comportamento appena descritto non succede. Infatti, se andiamo a compilare il codice ed eseguiamo i seguenti comando
./bakery > err sort -g err > err1 ./check < err1
possiamo notare che, andando a stampare i risultati in un file, e
andandoli poi a riordinare, la sequenza di ticket ad un certo punto
si rompe, e due thread stampano lo stesso ticket_id.
Questo comportamento, non conforme alle nostre aspettative, non deriva da come è stato scritto il software, ma da come il software viene eseguito dall'hardware. Nasce quindi il problema di studiare le architettura hardware che eseguono il nostro codice per capire l'effettivo comportamento del software nella macchina.
A seguire alcune osservazioni
Anche se il semaforo ci permette di gestire una risorsa in mutua esclusione, tale costrutto non è scalabile all'aumentare del numero di thread in esecuzione di un sistema, specialmente se la regione critica è una porzione di codice significativa. Sono dunque necessari altri meccanismi di sincronizzazione più efficienti.
L'architettura
x86, come molte altre architetture moderne, non offre una visione consistente della memoria quando abbiamo più thread che effettuano operazioni parallele sulla memoria. In particolare non c'è una garanzia a priori di consistenza globale rispetto alle operazioni che i threads effettuano nella shared memory. In inglese si diceno globally consistent update of memory operations
Questo significa che ogni thread ha una vista parziale rispetto alla memoria. È proprio questa visione parziale della memoria che spiega il perché l'algoritmo, implementato su questa architettura hardware, non funziona come dovrebbe.
La prima architettura astratta per un calcolatore a cui veniamo introdotti è il modello di Von Neumann. Questo modello è caratterizzato da:
Single CPU abstraction.
Single memory abstraction.
Single control flow abstraction: fetch-execute-store.
Time separated transitions in the hardware.
Defined memory image at the startup of any instruction.
Attualmente i modelli di architettura hardware utilizzati nelle principali macchine non presentano quasi nessuna di queste caratteristiche.
Al posto di basare l'architetture del sistema rispetto al flusso di istruzioni come riportate in un dato programma, l'idea alla base delle moderne architetture hardware è quella di utilizzare il concetto di scheduling, che si basa sullo schedulare una serie di micro-attività affinché il risultato finale di tutte queste micro-attività sia equivalente all'esecuzione sequenziale del program flow.
Il concetto di scheduling nello studio dei sistemi digitali moderni è applicato in vari contesti.
Schedulare nell'hardware significa:
Eseguire istruzioni all'interno di un singolo program flow.
Eseguire istruzioni in paralleli (speculativi) program flows.
Propagazione di valori all'interno della memoria (il più delle volte harware) del sistema.
Schedulare nel software significa:
Definire i time-frame per l'esecuzione di uno specifico thread.
Definire i time-frame per l'esecuzione di determinate attività, come ad esempio l'interrupt handler.
Supporti software per sincronizzare attività del software.
Osservazione: Per attività in un sistema moderno intendiamo quelle porzioni di codice che non riguardano direttamente i processi, come ad esempio l'interrupt handler. L'interrupt handler infatti non riguarda l'esercizio di un processo, ma viene usato dal sistema operativo per gestire gli interrupts.
Nelle moderne architetture uno dei concetti più importanti da capire è il concetto di speculazione. La speculazione introduce un cambiamento fondamentale rispetto al modo in cui tipicamente pensiamo a come il calcolatore esegue il codice dei nostri programmi.
Quando impariamo per la prima volta il funzionamento di un calcolatore siamo portati a pensare che quando lanciamo un programma il computer si mette ad eseguire le istruzioni del programma una alla volta rispetto a come è definito il program flow. Con l'introduzione della speculazione e dello scheduling delle istruzioni tutto questo non è più vero.
Con la speculazione infatti l'architettura hardware "sceglie" di eseguire una serie di istruzioni perché "pensa" che queste saranno poi eseguite dall'effettivo program flow, senza però esserne completamente sicura. Queste istruzioni, che vengono eseguite prima di capire se effettivamente fanno parte del program flow, sono dette "speculative", e vengono eseguite in modo, appunto "speculativo".
Questa scelta viene effettuata per aumentare le performance di esecuzione, in quanto controllare se una istruzione può essere eseguita o meno ha un relativo costo, e quando eseguiamo speculativamente questo costo non viene pagato. Non sempre però l'hardware capisce quali sono le istruzioni giuste da eseguire, e questo, come vedremo nella prima parte del corso, può portare a serie problematiche di sicurezza.
In altre parole, con l'introduzione della speculazione l'hardware potrebbe eseguire delle istruzioni che non fanno parte del program flow originale.
Per sincronizzare l'esecuzione di vari program flow, dobbiamo schedulare correttamente, sia a livello software sia a livello hardware.
Nelle architetture hardware moderne troviamo due principali tipologie di parallelismo. Queste sono:
ILP (Instruction Level Parallelism): parellelismo a livello hardware, descrive il fatto che la CPU è in grado di processare due o più istruzioni dello stesso program flow durante lo stesso ciclo di clock.
TLP (Thread Level Parallelism): parallelismo a livello software, descrive la possibilità di pensare all'esecuzione di un programma come la combinazione di più flussi di esecuzione (threads).
Generalmente si utilizzano i Gigahertz (GHz) di un processore per stabilire la sua velocità. Bisogna però fare attenzione, in quanto specialmente nelle architetture moderne, i Ghz sono solo una parte della soluzione, in quanto tipicamente i CPU-core interagiscono molto spesso con altri componenti hardware, e inoltre ci possono essere delle asimmetrie nei patterns di accesso ai dati. Quindi può succedere che determinate istruzioni possano richiedere più CPU-cycles.
Un tempo i program flow erano caratterizzati in base alle seguenti nozioni
CPU bound, un processo è detto CPU-bound se esegue tante operazioni macchina, e quindi se il suo tempo di esecuzione è principalmente ottenuto in funzione della velocità e dell'utilizzo del processore.
I-O bound, un processo è detto I-O bound se ha una significativa interazione con l'utente o comunque con dispositivi esterni al processore.
Nei sistemi moderni però è molto importante anche la seguente nozione
Memory bound, un processo è detto Memory bound se utilizza molto di più la memoria (RAM) rispetto ai componenti di memoria interni alla CPU (registri, cache).
La pipeline è una tecnica hardware che permette di schedulare e rendere parallela l'esecuzione delle istruzioni di un program flow. Utilizando una pipeline otteniamo un parallelismo nell'esecuzione delle istruzioni, e inoltre le istruzioni non vengono necessariamente eseguite nello stesso ordine in cui appaiono nel program flow.
In ogni caso, anche se utilizzando una pipeline possiamo effettuare più cose in parallelo, il concetto di causalità del program flow deve comunque essere rispettato. La causalità definisce il corretto ordine dell'interazione tra le varie istruzioni nel program flow. Una pipeline deve quindi implementare un data flow model in grado di garantire che ogni istruzione veda i dati corretti rispetto alla specifica del program flow orginario.
Ricapitolando, una pipeline ci permette di
Ottenere uno scheduling delle istruzioni, in quanto grazie alla pipeline l'ordine in cui andiamo ad eseguire le istruzioni non segue necessariamente l'ordine in cui queste appaiono nel program flow. La pipeline ci permette quindi di scegliere in quale ordine eseguire le istruzioni.
Esegure le istruzioni in modo parallelo, in quanto utilizzando una pipeline le finestre di tempo delle esecuzioni delle varie istruzioni non sono più separate in modo netto, ma possono eventualmente intersecarsi.
All'interno di una pipeline l'esecuzione di una singola istruzione del program flow viene spezzata in 5 stages principali, che sono
IF: Instruction Fetch.
ID: Instruction Decode.
LO: Load Operands.
EX: Execute.
WB: Write Back.
Questi 5 stages dovrebbero, idealmente, utilizzare risorse hardware diverse, in modo da poter essere eseguiti in parallelo nello stesso ciclo di clock, come riportato dalla seguente figura
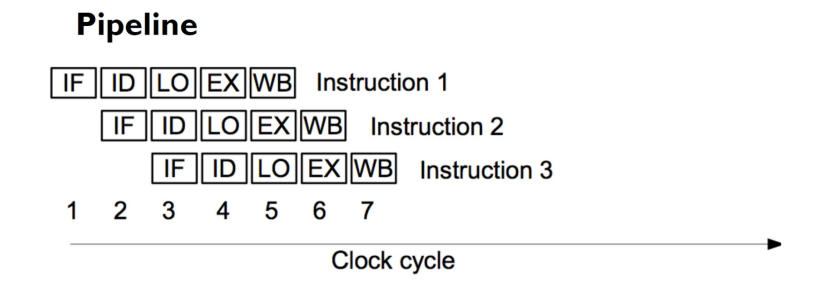
Se guardiamo solamente l'hardware, e quindi se escludiamo il vincolo di mantanere la causalità delle istruzioni che vengono eseguite, l'introduzione di una pipeline ci permette sempre di migliorare le performance.
Supponiamo infatti di indicare con \(N\) il numero di istruzioni da processare, con \(L\) il numero di stages per il processamento di ogni singola istruzione, e con \(T\) il numero di cicli di clock per eseguire ciascun stage di processamento.
Senza pipeline abbiamo un delay di \(N \cdot L \cdot T\) al fine di eseguire tutte le istruzioni. Con la pipeline invece abbiamo un delay di \((N + L - 1) \cdot T\). Infatti dobbiamo prima pagare un tempo di \(L \cdot T\) per riempire la pipeline ed eseguire la prima istruzione, e poi successivamente finalizziamo l'esecuzione di ogni istruzione in un solo ciclo di clock, andando a pagare in totale
\[ L \cdot T + (N - 1) \cdot T = (N + L - 1) \cdot T\]
Otteniamo quindi un fattore di speedup, definito come il rapporto tra il tempo di esecuzione senza pipeline e il tempo di esecuzione con la pipeline, pari a
\[ \text{speedup } = \frac{\text{time without pipeline}}{\text{time with pipeline}} = \frac{N \cdot L \cdot T}{(N + L - 1) \cdot T} = \frac{N \cdot L}{N + L - 1}\]
che è approssimabile ad \(L\) per valori di \(N\) grandi.
Almeno idealmente sembra quindi che più grande è il valore \(L\), ovvero più grande è la nostra pipeline, e più alto sarà il fattore di speedup. Nel mondo reale questo però non è vero, ed è dimostrato dal fatto che le pipeline che vengono effettivamente utilizzate hanno al massimo 4 o 5 stages di processamento.
Questa differenza può essere facilmente spiegata considerando il fatto che la nostra analisi non ha preso in considerazione l'effetto che eventuali conflitti possono avere sulle performance. La pipeline infatti si deve preoccupare di mantanere la causalità delle varie istruzioni, e per fare questo deve inevitabilmente rallentare l'esecuzione delle istruzioni.
Certe volte il progresso di una istruzione all'interno della pipeline viene interrotto momentaneamente da quelli che vengono chiamati breaks delle pipelines.
I breaks all'interno delle pipeline vengono utilizzati principalmente per gestire eventuali conflitti tra le varie istruzioni al fine di garantire la causalità delle istruzioni. In particolare i breaks derivano dalle seguenti ragioni:
Data dependencies: Se ho una istruzione che scrive in un registro, e poi subito dopo ho una istruzione che legge dallo stesso registro, non posso continuare l'esecuzione della seconda istruzione prima di aver completato il WriteBack della prima, ovvero prima di aver reso il risultato della prima istruzione disponibile alla seconda istruzione.
Control dependencies: Succede quando ho un salto condizionale. Infatti in questi casi la sucecssiva istruzione da inserire nella pipeline la saprò solamente quando la condizione è stata evalutata.
Il RE HARDWARE-INSIGHTS/PIPELINE_TEST contiene un singolo file
sorgente chiamato backward-propagation.c, e fa vedere l'esecuzione
di due operazioni che, a primo occhio, potrebbero sembrare
equivalenti da un punto di vista di complessità di esecuzione. Le
istruzioni sono le seguenti
// Increase the pointer and de-reference the pointer. c = *++buff; // first alternative // De-reference the pointer and then increase it. c = *buff++; // second alternative
Notiamo come nel primo metodo, prima di accedere alla memoria devo
incrementare il valore del puntatore buff di 1, e poi posso
utilizzare l'operatore * per accedere alla memoria puntata da
quell'indirizzo. Questo crea una dipendenza tra le due operazioni:
l'accesso alla memoria dipende dall'incremento del puntatore.
Nel secondo caso invece posso subito accedere alla memoria e poi
aggiornare il valore del puntatore. Tramite la backward
propagation poi, l'incremento sulla variabile buff può
avvenire anche prima che l'accesso alla memoria sia stato
completato, in quanto il valore del puntatore può essere propagato
direttamente all'istruzione successiva nella pipeline.
Eseguendo il codice sulla mia macchina che ha le seguenti specs
CPU: Intel i7-2600K (8) @ 3.800GHz GPU: NVIDIA GeForce GTX 970 Memory: 1855MiB / 7931MiB
e settando la variables CYCLES a \(100000\), abbiamo che con il primo
tipo di accesso otteniamo
-- per c = *++buff; real 0m4,461s user 0m4,449s sys 0m0,000s
mentre con il secondo tipo di accesso otteniamo
-- per c = *buff++; real 0m3,698s user 0m3,696s sys 0m0,000s
Questa differenza deriva dal fatto che, nel primo caso, l'operazione di INCREMENT deve aspettare che lo stage Execute dell'operazione di LOAD sia terminato, mentre nel secondo caso posso eseguire le due operazioni, quella di INCREMENT e quella di LOAD, senza aspettare, in parallelo.