AOS - 02 - HARDWARE INSIGHTS II
Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 2/7
Argomenti:
Gestione conflitti pipeline
Storia di x86
Out of Order Execution (OoOE)
Imprecise exceptions
Algoritmo di Tomasulo
Architettura OoOE
Hyper-threading
1 Pipeline Conflicts
Come avevamo introdotto nella precedente lezione, le pipelines devono garantire la causalità delle istruzioni del program flow. Per fare questo devono quindi gestire le seguenti situazioni di conflitto:
Nelle istruzioni di salto (conditional branches), si conosce la prossima istruzione da inserire nella pipeline solamente durante l'execution stage.
Un conflitto di dati può rallentare l'attività di alcune istruzioni nella pipeline, in quanto se una istruzione \(A\) nella pipeline richiede un dato prodotto da un'altra istruzione \(B\) sempre nella pipeline, l'istruzione \(A\) dovrà necessariamente aspettare l'esecuzione dell'istruzione \(B\).
Al fine di risolvere i conflitti abbiamo vari approcci, descritti a seguire:
Hardware propagation: La propagazione è una tecnica hardware che permette di rendere disponibili alcuni dati prodotti nelle pipeline prima dello stage di WriteBack alle istruzioni successive. Alla fine dell'execution stage, il dato che poi si andrà a scrivere in un registro o nella memoria è già disponibile agli altri stages della pipeline. La propagazione consiste quindi nel "propagare in avanti" questo dato ad altre istruzioni che si trovano nella pipeline e che quindi potrebbero aspettare quel particolare dato.
Software stalls: Si basa sul fermare l'esecuzione delle istruzioni nella pipeline fino a quando i dati sono pronti andando ad aggiungere delle istruzioni NOP in mezzo.
Software re-sequencing: Si basa sull'utilizzo di un compilatore che verifica se si possono allontanare all'interno dell'execution flow istruzioni dipendenti tra loro. Il re-sequencing è una procedura molto vincolata, in quanto non può rompere la logica del program flow iniziale. Inoltre, il software re-sequencing non va ad ottimizzare le risorse hardware, ma cerca solo di minimizzare i conflitti di dati tra le varie istruzioni.
Out-of-order Execution: Nelle pipeline OOO l'ordine in cui le istruzioni vengono eseguite e portate avanti non rappresenta più l'ordine in cui sono collocate nel program flow, ma rappresenta invece un ordine scelto dalla micro-architettura per massimizzare le risorse hardware disponibili.
L'approccio moderno per gestire i conflitti nella pipeline si basa sulla Out-of-order execution (OOO-Execution). I processori moderni hanno delle pipeline che sono quasi esclusivamente di tipo OOO.
2 x86 History
L'architettura x86 definisce una famiglia di ISA (Instruction Set Architecture). La storia dell'architettura x86 può essere approssimata descrivendo tre particular chipsets: l'8086, l'i486 e il Pentium Pro.
2.1 Intel 8086 (iAPX 86)
La famiglia di architettura x86 è stata introdotta con il chipset
Intel 8086 , sviluppato tra il 1976 e il 1978. L'intel 8086 aveva
14 registri (AX, BX, ...), e al posto di utilizzare una pipeline
processava le istruzioni tramite un ciclo a quattro fasi
\[ [\text{FETCH}, \text{ DECODE}, \text{ EXECUTE}, \text{ RETIRE}] \]
L'istruzione \(\text{RETIRE}\) in particolare veniva utilizzata per effettuare il commit the instruction, ovvero per rendere visibili tutti i side effects causati dell'istruzioni all'insieme delle risorse esposte all'ISA.
2.2 Intel 80486 (i486)
Nel 1989 è stato poi introdotto il nuovo processore, l'intel 80486,
detto anche i486 . Questa volta era presente una pipeline a \(5\)
stages.

Notiamo che i due stages di decode derivano dal fatto che l'x86 ha un sistema molto complesso di indirizzamento della memoria.
Successivamente all'introduzione di questa pipeline i programmatori hanno notato come la pipeline introdotta nel i486 non era molto performante quando c'era una forte dipendenza dei dati nel program flow. Un noto esempio di forte dipendenza dei dati capita quando vogliamo scambiare il valore di due registri. Infatti, se non si vuole utilizzare un terzo registro (e nella programmazione di sistema tutti i registri sono fondamentali, quindi è cosa buona e giusta risparmiare un registro), e se non si vuole avere un accesso alla memoria (che renderebbe il program flow memory-bound, e conseguentemente più lento), l'unico modo per ottenere questo swap è utilizzando la seguente sequenza di operazioni
\[ \text{XOR}(a,b), \text{XOR}(b,a), \text{XOR}(a,b) \]
2.3 Intel Pentium Pro (1995)
Con il Pentium Pro la intel introduce il concetto di superscalarità di una pipeline. Una pipeline superscalare è una pipeline in cui è possibile eseguire più istruzioni che fanno la stessa operazione in modo parallelo utilizzando risorse hardware duplicate. L'idea alla base di una pipeline superscalare è quella di eseguire gli stages di Execute (EX) di più istruzioni in modo parallelo, andando ad introdurre una ridondanza a livello hardware.
Con questo modello di pipeline si introduce il concetto di OOO Execution, e quindi l'ordine in cui le istruzioni vengono esegutie a livello hardware nella pipeline non rispetta più l'ordine in cui le istruzioni appaiono nel program flow. In un modello OOO una istruzione va avanti finché le risorse hardware e i dati di cui l'istruzione ha bisogno sono disponibili.
L'architettura hardware della pipeline che permetteva la OOO
execution utilizzata nel Pentium Pro era basata su un algoritmo
trovato da Robert Tomasulo e già implementatoo dalla macchina IBM
360/91 nel 1966. Nell'implementazione dell'IBM il concetto di OOO
execution era perà limitato solo ad una determinata classe di
istruzioni, mentre nell'implementazione della intel tutte le
istruzioni possono potenzialmente essere eseguite OOO.
Anche se l'esecuzione delle istruzioni non avviene in ordine, il commit finale (\(\text{RETIRE}\)) delle istruzioni deve comunque avvenire nell'ordine definito dal programma. Dunque, volendo sintentizzare, la out-of-order execution si basa sui due seguenti principi:
Il commit delle istruzioni viene effettuato rispettando l'ordine delle istruzioni come definito dal program flow.
Le istruzioni indipendenti (sia nei dati che nelle risorse), vengono processate il prima possibile.
3 OoOE Concepts
L'idea dietro all'out-of-order execution è quella di processare istruzioni indipendenti (nei dati e nelle risorse hardware) il prima possibile, e poi di committarle in ordine rispetto al program flow iniziale. Nel contesto della ooo execution sono importanti i seguenti due processi:
Emission: L'emissione è il processo di immettere istruzioni all'interno della pipeline.
Retire: Il ritiro è l'azione di commit delle istruzioni, e rende i loro side effects "visibili" alle risorse hardware esposte all'ISA.
3.1 Imprecise Exceptions
In uno scenario OoOE dobbiamo essere in grado di preservare le eccezioni che possono essere sollevate durante l'esecuzione del program flow.
Il fatto che durante la OoOE vengono generate delle eccezioni non implica automaticamente che queste eccezioni appartengono effettivamente al program flow che si sta eseguendo, in quanto l'istruzione che ha generato l'eccezione, diciamo l'istruzione \(A\), potrebbe aver sorpassato un'altra istruzione, diciamo l'istruzione \(B\), che nel program flow la precedeva, e che a sua volta, se eseguita, avrebbe generato una eccezione. Ma allora tutte le istruzioni che seguivano \(B\) non dovevano essere presenti nel program flow, e quindi il program flow non avrebbe dovuto generare l'eccezione derivante dall'esecuzione dell'istruzione \(A\). Queste eccezioni che non appartengono al program flow ma che vengono generate per via della OoOE prendono il nome di phantom execptions.
Il fatto che l'istruzione \(A\) è stata eseguita in modo speculativo prima dell'istruzione \(B\), anche se non ha effetti sulle risorse hardware esposte dall'ISA, implica comunque degli effetti micro-architetturali per il sistema. Recentemente si è scoperto che osservare in modo indiretto questi effetti micro-architetturali può permette di inferire informazioni confidenziali sul sistema. Le vulnerabilità più famose di questa categoria prendono il nome di Spectre e Meltdown, e verranno attentamente studiate nel proseguire del corso.
4 Tomasulo's algorithm
L'algoritmo di tomasulo è stato utilizzato per implementare le prime pipeline che eseguivano out-of-order. Per descrivere l'algoritmo procediamo prima descrivendo il tipo di conflitti che deve gestire, e poi descriviamo quali sono le idee fondamentali su cui si basa.
4.1 Conflicts to manage
Supponiamo di avere due istruzioni \(A\) e \(B\) in ordine \(A \to B\). Andiamo a vedere i possibili conflitti tra le due istruzioni
RAW (Read After Write): Se nel program flow l'istruzione \(A\) scrive su una locazione di memoria su cui poi legge l'istruzione \(B\), andando ad invertire \(A\) e \(B\) l'istruzione \(B\) leggerà un valore "stale".
WAW (Write After Write): Se nel program flow l'istruzione \(A\) scrive su una locazione di memoria e su cui poi ci scrive \(B\), andando ad invertire l'ordine tra \(A\) e \(B\) ottengo che il risultato finale nella memoria è quello scritto da \(A\), e non quello scritto da \(B\), come dovrebbe essere.
WAR (Write After Read): Se nel program flow \(A\) legge da una locazione di memoria su cui poi ci scrive \(B\), andando ad invertire l'ordine tra \(A\) e \(B\) ottengo che \(A\) legge un valore nel futuro della sua esecuzione, che non avrebbe dovuto leggere.
4.2 Algorithmic ideas
Alla base dell'algoritmo di Tomasulo ci sono le seguenti idee algoritmiche:
Per gestire il conflitto di tipo RAW tengo traccia di quando i dati richiesti in input dalle istruzioni sono pronti, e appena sono pronti propago le informazioni a tutte le istruzioni che necessitano di questi dati.
Per gestire i conflitti WAR e WAW utilizzo il concetto del register renaming.
4.2.1 Register Renaming
Il register renaming consiste nell'avere, per ogni registro logico esposto all'ISA, \(N\) registri fisici. Il valore del registro logico espsoto all'ISA è quindi scelto tra uno degli \(N\) registri fisici.
Ciascun registro fisico è formato dal nome del registro logico + un tag che identifica il particolare registro fisico. Così facendo possiamo avere \(N\) versioni del registro, di cui solo una è la versione effettiva (committed), e le altre sono solo versioni speculative che vengono utilizzate durante il processamento OOO.
Le operazioni di read e write vengono poi gestiste come segue:
Durante l'operazione di write generiamo un nuovo standing tag e scriviamo su quel particolare registro fisico.
Durante l'operazione di lettura leggiamo il valore dell'ultima standing tag, che può eventualmente coincidere con il valore effettivo del registro se l'ultima operazione di scritta è andata in commit.
Tramite il register renaming siamo quindi in grado di implementare nella nostra architettura hardware il concetto di speculatività.
4.2.2 Reservation Stations
Le reservation stations vengono utilizzate per bufferizzare le istruzioni da eseguire. Una reservation station contiene:
L'op-code dell'istruzione da eseguire.
I valori da utilizzare in input dall'istruzione, \(V_j, V_k\); oppure le altre reservation stations da cui ci aspettiamo l'input per l'operazione, \(Q_j, Q_k\).
5 OoOE Architecture
Una tipica architettura OOO può essere schematizzata come segue
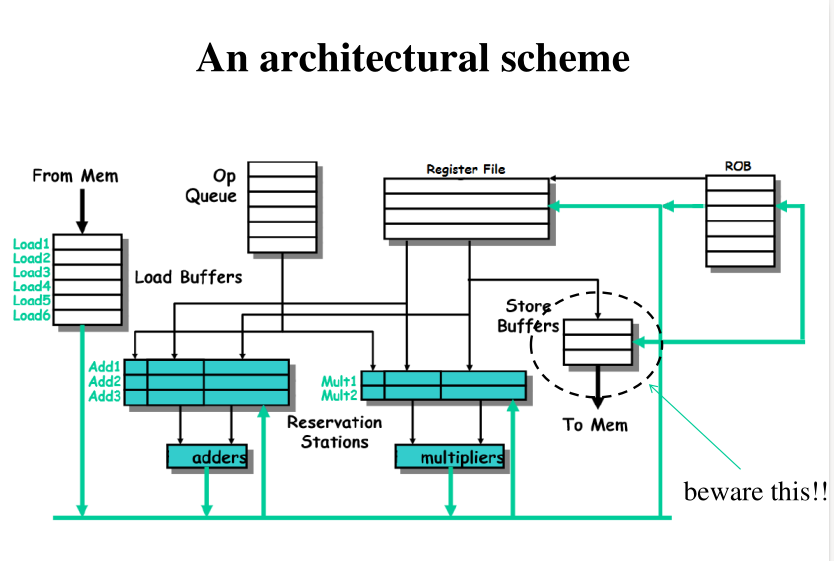
Volendo descrivere con maggiore dettaglio i vari componenti troviamo:
OP Queue: Coda in cui vengono caricate le istruzioni da inserire nella PIPELINE.
Reservation stations: Buffers per l'esecuzione delle varie istruzioni.
Risorse hardware: Utilizzate per eseguire le operazioni sui dati come somma e moltiplicazione.
Reorder Buffer (ROB): Utilizzato per implementare il register renaming e dunque il concetto di speculatività. Contiene anche ciò che deve essere mandato in memoria.
Register File: Contenuto effettivo dei registri esposti all'ISA.
Store Buffers: Utilizzati per contenere i valori da scrivere nella memoria. Vengono flushati in memoria secondo una logica particolare che l'hardware adotta per ottimizzare l'interazione con la memoria. Possiamo quindi avere una inversione delle interazioni con la memoria. Nell'ISA sono presenti dei controlli che ci permettono di gestire questa risorsa.
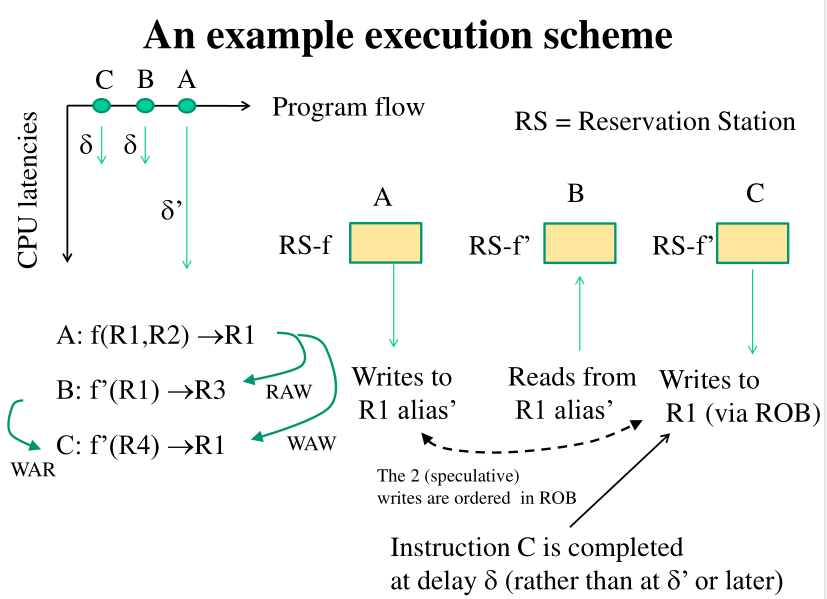
6 OoOE Example
La seguene immagine mostra un esempio di esecuzione utilizzando la OoOE.
7 Hyper-Threading
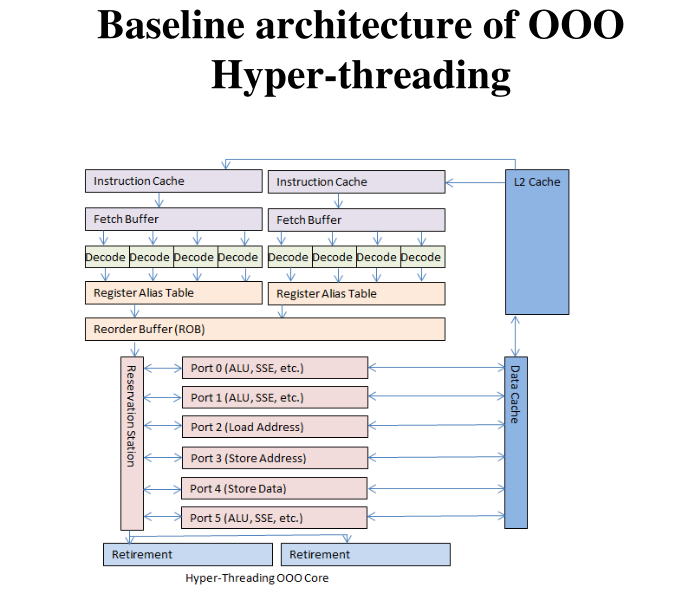
Con una architettura che supporta la OoOE i processori sono in grado di eseguire almeno una istruzione per ciclo di clock. Questa estrema efficienza nell'esecuzione delle istruzioni però crea un problema forse inaspettato: per funzionare in modo performante, i processi OoO devono tenere piena la pipeline continuando a ricevere istruzioni. Al fine di risolvere questo problema si è introdotto il concetto di Hyper-threading.
L'hyper-threading consente di eseguire più program flow contemporaneamente nello stesso CPU-core, utilizzando la stessa pipeline che implementa la OoOE. In una architettura hyper-threading le risorse esposte all'ISA sono raddoppiate, anche se il processore è comunque lo stesso.
8 Misc
A seguire qualche nota e concetto generale che sono stati esposti durante la lezione è che bisogna tenere a mente.
8.1 Microarchitecture
Quando una istruzione viene processata dalla pipeline, l'hardware cambia il suo stato interno al fine di processare l'istruzione. Lo stato dell'architettura esposto all'ISA invece cambia solamente dopo aver effettuato l'operazione di RETIRE. Questo vuol dire che tutti i cambiamenti dell'hardware necessari per eseguire una determinata istruzione ma che avvengono prima del RETIRE non sono visibili dalle risorse offerte dall'ISA (registri, memoria e operazioni per interfacciarsi con registri e memoria). Si parla quindi di micro-architettura di sistema per intendere tutte le risorse hardware, anche quelle non esposte all'ISA, che servono per eseguire le istruzioni che compongono i vari program flow che vogliamo eseguire.
8.2 CPUID
L'istruzione CPUID viene utilizata per ottenere l'identificativo numerico del processore su cui stiamo lavorando. Questa istruzione però, come side effect, va a svuotare la pipepline (flush of the pipeline).
Nella programamzione di sistema moderna è possibile ottenere tale informazione senza l'utilizzo di questa istruzione.