AOS - 03 - HARDWARE INSIGHTS III
Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 3/7
Argomenti
Interrupt in OOO architectures
Exceptions in OOO architectures
Meltdown
Dettagli su x86
Codice & Fix Meltdown
Branch prediction
1 Interrupts and OoOE
Nelle moderne architetture OOO gli interrupt vengono controllati dopo il commit di ogni istruzione.
Tipicamente quindi, ad ogni ciclo di clock, o anche meno, nel caso in cui vengono commitate due istruzioni per ciclo di clock, si verifica se ci sono delle linee standing associate agli interrupts per poterli gestire. In caso positivo, si effettua immediatamente il flush della pipeline al fine di cambiare il contesto di esecuzione per poter gestire l'interrupt tramite l'esecuzione dell'interrupt handler. Gli interrupts sono quindi molto dannosi per le prestazioni di un sistema basato su una architettura con pipeline. Detto questo, il flush della pipeline è inevitabile, in quanto l'hardware moderno non permette di salvare lo stato micro-architetturale del sistema.
Andando a flushare la pipeline non bisogna preoccuparsi di eventuali problemi a livello software rispetto a come assegnare la priorità tra le eccezioni e gli interrupt: gli interrupts hanno sempre la priorità massima.
Anche se flusho la pipeline però, l'effetto delle precendi istruzioni che erano entrate nella pipeline e che avevano generato ed eseguito del micro-code, andando dunque a cambiare lo stato micro-architetturale del sistema, rimane comunque invariato. Inoltre il micro-codice non cambia solamente lo stato della CPU, ma anche lo stato di altre risorse hardware, come ad esempio la cache. Dato che la cache non è una risorsa esposta all'ISA, andando ad eseguire una istruzione che speculativamente carica un dato in memoria, siamo in grado di modificare lo stato della cache del sistema in modo trasparente. Questo può avere gravi conseguenze di sicurezza, che sono mostrato principalmente da vulnerabilità come meltdown e spectre.
2 Exceptions and OoOE
Andiamo adesso a trattare a grandi linee il modo in cui vengono gestite le eccezioni in una architettura basata su OoOE. Ricordiamo a tale fine la differenza la exceptions e interrupts: le exceptions sono eventi sincroni, generati dal software e gestiti dal software; gli interrupts invece sono eventi asincroni, tipicamente generati da dispositivi esterni alla CPU o alle CPU del sistema, che vengono sempre gestiti dal software.
2.1 Exceptions Types
Supponiamo di avere una classica pipeline a 5 stages. A seguire riportiamo una breve overview delle possibili tipologie di exceptions che possono essere generate nelle varie fasi della pipeline.
Instruction Fetch + Memory stages: In questi stages possiamo avere delle eccezioni relative all'accesso in memoria. In particolare abbiamo tre tipologie di eccezioni diverse:
Page fault: viene generata quando proviamo ad accedere ad una pagina virtuale mappata che ancora non è ancora stata materializzata nella memoria fisica (RAM), oppure quando proviamo ad accedere ad una pagina virtuale che non è mappata (segmentation fault).
Misaligned memory access: viene generata quando non alliniamo corretamente in memoria gli operandi per una istruzione.
Memory-protection violation: viene generata quando proviamo a fare qualcosa nella memoria che non è lecito. A differenza di un segmentation fault, in questo caso la memoria che sto andando a toccare è effettivamente materializzata, ma potrei non avere l'autorizzazione per leggere e/o scrivere in quella pagina.
Instruction Decode stage: In questo stage possiamo avere delle eccezioni relative ad un indefinito o illegale opcode.
Execution stage: In questo stage possiamo avere delle eccezioni di tipo aritemtico, che vengono cioè generate da computazioni aritmetiche, come ad esempio dividere per \(0\).
Write-Back stage: In questo stage non ci sono eccezzioni che possono essere generate. La possibilità dell'istruzione di eseguire il write-back correttamente viene dunque controllata prima di questa fase.
2.2 Exception Handling
Se una istruzione ad un certo punto della sua esecuzione genera una eccezione, non possiamo immediatamente gestire l'eccezione generata, in quanto l'istruzione che ha lanciato l'eccezione potrebbe aver superato altre istruzione che avrebbero a loro volta lanciato delle eccezioni. In altre parole, l'eccezione potrebbe essere stata generata in modo speculativo.
Dunque, per preservare l'ordine corretto e non lanciare "phantom exceptions", l'unica cosa che possiamo fare è marcare ogni istruzione che genera una eccezzione come "istruzione offending", tramite l'utilizzo di un bit.
Durante la fase di commit poi, quando una istruzione viene ritirata, si verifica se l'istruzione è offending oppure no, e in caso l'istruzione sia offending, viene lanciata e gestita la particolare eccezione.
Il fatto che le eccezioni generate nella pipeline non vengono immediatamente gestite pone dei seri problemi di sicurezza, in quanto il loro effetto micro-architetturale rimane invariato anche dopo aver effettuato lo squashing della pipeline.
3 x86 Details
Attualmente la versione più moderna dell'architettura x86 è a 64 bit e prende il nome di x86-64. L'architettura x86-64 offre 16 registri general purpose a 64 bit, tra cui troviamo:
\[\text{EAX }, \text{EBX }, \text{ECX }, \text{EDX }, \text{ESP }, \text{EBP }, \text{ESI }, \text{ESI }, \text{R8 }, \text{R9 }, ..., \text{R15}\]
Per poter essere retro-compatibile con le vecchie versioni dell'architettura x86, I primi otto registri sono formati estendendo i registri delle vecchie versioni dell'architettura. Ad esempio il registro RAX può essere visto nei seguenti modi
Graficamente,

L'x86-64 offre poi 16 registri a 128 bit che vengono utilizzati per operazioni vettoriali concorrenti.
Infine, abbiamo i registri per le operazioni matematiche e il registro \(\text{RIP}\) che viene utilizzato per puntare alla prossima istruzione da eseguire. Del registro a 64 bit \(\text{RIP}\) esiste anche la versione a 32 bit, che viene si chiama \(\text{EIP}\).
3.1 Data Transfer
L'istruzione fondamentale per muovere i dati è l'istruzione mov. Utilizzando la sintassi AT&T per trasferire dei dati da una sorgente (source) ad una destinazione (dest) scriviamo la seguente cosa
mov source, dest
La mov può poi essere utilizzata specificando anche la taglia di cosa sto spostando. In particolare abbiamo le seguenti versioni dell'istruzioni mov
movb $0x4a, %al ;; sposta 8-bit di '0x4a' nel registro al movw $5, %ax ;; sposta 16-bit di '5' nel registro ax movl $7, %eax ;; sposta 32-bit di '7' nel registro eax mov $30, %rax ;; sposta 64-bit di '30' nel registro rax
Per gestire la stack di esecuzione invece abbiamo le seguenti istruzioni.
push %rbx ;; metti in cima alla stack il contenuto (64-bit) del registro ebx pushl %ebx ;; metti in cima alla stack il contenuto (32-bit) del registro ebx pushw %bx ;; metti in cima alla stack il contenuto (16-bit) del registro bx pop %rbx ;; togli il valore a 64-bit in cima alla stack e mettilo nel registro rbx popl %ebx ;; togli il valore a 32-bit in cima alla stack e mettilo nel registro ebx
3.2 Linear Addressing
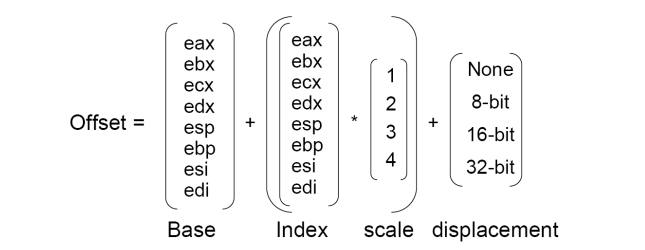
All'interno dell'ISA gli indirizzi sono visti come degli offset in uno spazio di indirizzamento lineare, che specificano qual'è il punto particolare dell'address space che ci interessa. Al fine di specificare l'offset a cui siamo interessati possiamo utilizzare il seguente schema
\[ \text{Offset } = \text{base} + (\text{index } \cdot \text{ scale}) + \text{displacement} \]
Dove,
La base può essere specificata tramite il valore di uno degli 8 registri base \(\text{EAX }, \text{EBX }, ..., \text{EDI}\).
Il displacement può essere espresso tramite un valore 8-bit, 16-bit o 32-bit.
L'indice può essere specificato dal valore di uno degli 8 registri base eventualmente moltiplocato per una scala, che può essere un valore preso dall'insieme \(\{1, 2, 3, 4\}\).
Graficamente quindi troviamo il seguente schema
A seguire qualche esempio di accesso alla memoria
; Utilizzo solo il displacement, cablato nel valore di foo, per ; andare a prendere il valore da caricare nel registro EAX. movl foo, %eax ; Utilizzo solo la base, contenuta nel registro EAX. movl (%eax), %ebx ; Utilizzo displacement + base. movl foo(%eax), %ebx ; Utilizzo Base + displacement + (index*scale) movl foo(%ecx, %eax, 4), %ebx
4 Meltdown
Andiamo adesso a trattare meltdown, che è una vulnerabilità scoperta qualche anno fa e collegata in modo intimo al concetto di OoOE.
Ogni processo che viene eseguito da un sistema operativo moderno ha una propria memoria virtuala divisa in pagine. Ogni pagina ha varie caratteristiche, e può essere una pagina dello user-space oppure una pagina del kernel-space. Una applicazione che gira in user-space non dovrebbe essere in grado di leggere da una pagina del kernel.
L'attacco meltdown permette ad un processo user-space di leggere in modo indiretto delle informazioni da pagina del kernel. Meltdown, per funzionare, sfrutta il fatto che le moderne architetture implementano una OoOE.
4.1 How it works?
L'attacco meltdown può essere schematizzato nel seguente modo:
Si esegue il flush della cache.
Si cerca di leggere un byte \(B\) da una pagina del kernel.
Si utilizza il byte \(B\) letto come offset per leggere una zona della memoria a cui possiamo accedere normalmente, come ad esempio un array, tipicamente chiamato probe array (array sonda).
Si accede in sequenza alle varie sezioni del probe array si misura la latenza di accesso alla memoria per ciascuna sezione dell'array. Se la latenza è abbastanza bassa, si conclude che la zona di memoria dell'array presa in considerazione è presente in cache, e questo ci permette di inferire in modo implicito il valore del byte letto \(B\).
Questo attacco è reso possibile dalle seguenti osservazioni:
Per quanto riguarda il primo punto, effettuare il flush della cache è una operazione offerta dall'ISA a livello user-space. Andando a flushare la cache, qualsiasi accesso successivo alla memoria successivo sarà un cache-miss. Dunque anche quando proveremo ad accedere al nostro probe array, ci sarà inizialmente un cache-miss, e poi la pagina a cui acceddiamo verrà caricata in cache.
Anche se la lettura di un byte \(B\) da una pagina del kernel è una istruzione illegale che genera una exception di tipo Memory-protection violation, tramite l'esecuzione speculativa possiamo comunque eseguire la terza istruzione prima che la seconda istruzione vadi in commit e quindi generi l'eccezione. È proprio per questa ragione che si dice che meltdown sfrutta la speculatività dell'hardware.
Quando l'attacco riesce in modo corretto quindi, l'istruzione di accesso alla memoria aspetta la lettura del byte \(B\) del kernel e poi viene subito eseguita. Questo ci permette di utilizzare il byte \(B\) per accedere ad una particolare zona di memoria. Ad un certo punto poi l'istruzione che ha il letto il byte \(B\) dalla pagina del kernel va in commit, e dato che è una istruzione offeding, viene generata una eccezzione. Dopo l'esecuzione di gestione della exception però, è possibile misurare il tempo richiesto per ottenere le varie pagine del nostro probe array: la pagina che verrà caricata più velocemente, molto probabilmente, sarà anche quella che era stata caricata nella cache dalle istruzioni precedenti. Dato che il byte \(B\) identifica la particolare pagina caricata nella cache, una volta che sappiamo quale pagina è stata caricata, sappiamo anche qual'è il valore del byte \(B\).
4.2 Why it works?
Abbiamo descritto il funzionamento di meltdown. Andiamo adesso a capire esattamente il perché riesce a funzionare in quel modo.
Essenzialmente l'attacco meltdown riesce a funzionare perché esiste una sola page table che mappa le pagine virtuale dei vari processi alle pagine fisiche caricate in memoria. Avendo una sola page table, qualsiasi accesso ad una pagina del kernel genera una eccezione di tipo memory-protection-violation, e non genera un page fault. Dato che la pagina è disponibile quindi, il micro-codice va a leggere il contenuto dell'indirizzo contenuto della pagina, lo carica nella cache, e lo utilizza come offset nella successiva operazioni di lettura sul probe array.
4.3 PoC
Riportiamo a seguire una Proof-Of-Concept (POC) che fa vedere la vulnerabilità metldown, scritto nella sintassi Intel. Osserviamo che nella notazione intel le sorgenti sono a destra e le destinazioni a sinistra.
Per la nostra spiegazione assumiamo che il registro \(\text{rcx}\) contiene un indirizzo di una pagina del kernel, mentre il registro \(\text{rbx}\) contiene l'indirizzo del nostro probe array, ovvero l'array che viene successivamente utilizzato per capire il byte letto.
Il codice di meltdown è il seguente,
retry: ; leggi il byte B dalla pagina del kernel ; e caricalo nel registro al mov al, byte [rcx] ; esegui uno shift aritmetico a sinistra di 0xc = 12 posizioni sul ; registro RAX. Questo shift viene eseguito perché voglio ; utilizzare il byte B letto per sapere quale pagina del probe array ; carico nella cache. Dato che una pagina contiene 4096 bytes, ; indirizzabili da 12 bit, i 12 bit meno significativi non mi ; interessano, e dunque li pongo a 0. shl rax, 0xc ; se ho ottenuto 0 da questa operazione significa che il valore ; che avevo caricato dalla pagine del kernel è 0. Dato che ; tipicamente non mi interessa leggere il byte 0 dalle pagine del ; kernel, se leggo 0 riprovo a leggere un nuovo byte. jz retry ; carico nel registro rbx una particolare pagina del mio probe ; array. mov rbx, qword [rbx + rax]
Notiamo che necessitiamo di effettuare lo shift di \(12\) bits del byte letto dal kernel perché dobbiamo avere una certa distanza tra i vari valori che vogliamo caricare in cache. Queste segue dal fatto che,
Se non ci fosse una certa distanza tra i byte che sto caricando, allora la cache caricherebbe più byte nella stessa linea di cache e quindi non saremmo in grado di stabilire quale tra i tanti valori possibili è stato quello caricato in cache.
Le cache moderne effettuano anche operazioni di pre-fetch, e quindi non caricano solo la linea di cache che comprende il byte a cui si è provato ad accedere, ma contengono bytes che sono vicini a quel byte.
Spostandomi di pagina in pagina riesco quindi a creare una distanza sufficiente per capire qual'è la singola pagina caricata, e quindi il valore del byte \(B\). Dato che una pagina è formata da \(4096\) bytes, ottengo che lo shift necessario da effettuare è di \(12\) bits.
4.4 Cache Latency
Notiamo che meltdown non è un attacco deterministico e quindi non funziona ogni volta. Questo segue dal fatto che la cache viene utilizzata da altre parti del sistema, ed è quindi difficile sapere in modo certo cosa ci sarà e cosa non ci sarà nella cache in un dato istante.
In particolare, se nell'intervallo di tempo in cui l'eccezione viene generata e processo che l'ha generata riprende il controllo, può succedere che altre cose vengano caricate nella cache, e in caso di "bad luck" i dati caricati nella cache possono sovrascrivere la pagina del probe array che era stato caricato nella cache in modo speculativo utilizzando il byte \(B\) letto dalla memoria del kernel.
Inoltre anche i tempi di latenza della cache non sono deterministici, e quindi andare a capire quale pagina è stata caricata nella cache può non sempre essere così chiaro.
4.5 Side Channels
Idealmente un program flow non dovrebbe essere influenzato dal contenuto della cache, che non è una risorsa esposta dall'ISA. Detto questo, l'unico effetto che il contenuto della cache ha sul program flow è la performance. Notiamo come questo sia inevitabile, in quanto il ruolo della cache è proprio quello di aumentare la velocità negli accessi della memoria effettuati dai vari program flow in esecuzione.
Andando ad analizzare la performance però, un possibile attaccante è quindi in grado di inferire informazioni sullo stato della cache.
Questa tipologia di attacchi in cui si cerca di inferire informazioni sul sistema andando ad analizzare e osservare il comportamento del sistema prendono il nome di side-channel attacks (o covert-channel attacks). Meltdown è quindi un attacco di tipo side-channel.
4.6 Possible Fixes
Abbiamo tre principali fix per metldown, che sono
KASLR: Sta per Kernel Address Space Randomization, e consiste nel randomizzare la locazione delle pagine del kernel nella memoria fisica. Ad ogni boot del sistema quindi le pagine del kernel si trovano in un luogo diverso. Questo fix comunque non funziona contro attacchi di tipo brute-force.
PTI: Sta per Page Table Isolation, o Kernel Isolation in Linux (KAISER), e consiste nel separare le page tables del kernel e delle applicazioni user-mode. Così facendo quando provo a leggere il byte dalla pagina del kernel ottengo un page-fault, e quindi neanche speculativamente riesco a leggere il byte dalla pagina del kernel.
Eseguire il flush della cache ogni volta che ritorniamo dal kernel mode.
Questo tecnica riduce estremamente le performance e non riesce a risolvere completamente la problematiche.
A seguire qualche osservazione utile:
Per implementare una soluzione di tipo KAISER (o PTI), necessitiamo che il processore offra un indirizzamento RIP relative, ovvero un indirizzamento in cui gli indirizzi sono passati come dei (signed) 32-bit displacement dal valore corrente dell'instruction pointer.
In ogni caso, anche utilizzando tecniche come PTI o KASLR, non è completamente possibile nascondere tutte le pagine del kernel rispetto ai processi user-mode. Infatti i kernel-entry points devono necessariamente essere accessibili ai processi user-mode.
Infine, anche con una soluzione di tipo KAISER, quando c'è un context-switch, ad esempio con una system call, dato che modifichiamo il contenuto del registro CR3 che punta alla page table del processo corrente, necesistiamo di eseguire un TLB flush. Questa patch quindi danneggia tutte le applicazioni che sono CPU intensive e che entrano molto spesso in modo kernel, come le applicazioni HPC (High Performance Computing).
5 Branch Prediction
Nel program flow mi devo preoccupare delle istruzioni di jmp. Il supporto hardware che si occupa di migliorare le performance nelle pipelines in caso di istruzioni di jmp, ovvero in situazioni di branching, è chiamato dynamic predictor (o branch preditor).
Il branch predictor è quella parte dell'hardware che fa scegliere al sistema se cambiare il flusso di esecuzione oppure no, a seconda di una particolare condizione. La branch prediction fondamentalmente si basa sul fatto che il passato recente è una buona approssimazione del futuro immediato.
Un branch predictor è detto dinamico le scelte che effettua non sono statiche, ma se vengono calcolate in funzione a quello che sta succedendo all'architettura e alle caratteristiche del program flow.
Il supporto hardware per questa attività avviene tramite un buffer chiamato Branch-Prediction Buffer (BPB) o anche Branch History Table (BHT). In questo buffer sono contenute delle informazioni sugli ultimi salti, che vengono utilizzare dall'hardware per capire se la prossima volta si dovrà saltare oppure no.
L'implementazione di questo buffer avviene tramite una cache indicizzata dai bit meno significativi delle branch instructions, assieme ad un bit di status. Il bit di status indica se il salto associato alla branch instruction è stato eseguito di recente oppure no. L'esecuzione speculativa del program flow segue la direzione basandosi su questo bit di status.
5.1 1-bit Predictors
Utilizzare un solo bit per fare la branch prediction può avere un impatto disastroso per le performance del sistema. Un chiaro esempio di questo può essere visto analizzando il comportamento di un predittore ad un bit nell'esecuzione di un nested loop come il seguente
mov $0, %ecx .outerLoop: cmp $10, %ecx je .done mov %0, %ebx .innerLoop: inc %ebx cmp $10, %ebx ;; This branch prediction is inverted jnz .innerLoop ;; at each ending inner-loop cycle inc %ecx jmp .outerLoop .done:
In questo caso infatti se ho un predittore ad un bit, ad ogni fine dell'inner-cycle la branch prediction è inverted, e quindi ogni volta devo flushare la pipeline.
Per gestire meglio gli inner loops possiamo aumentare il numero di bit necessari per capire se dobbiamo saltare oppure no. Così facendo, prima di cambiare la nostra decisione se saltare oppure no, dobbiamo prima eseguire due errori.