AOS - 05 - HARDWARE INSIGHTS V
1 Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 5/7
Argomenti:
Cache coherency
CC protocols
Snooping cache coherency protocols
ESI
MESI
False cache sharing
ASM Inline
FLUSH+RELOAD
2 Cache Coherency
Le architetture moderne delle cache sono essenzialmente dei sistemi di replicazione. Tramite l'utilizzo delle cache siamo infatti in grado di avvicinare i dati già presenti in memoria alla CPU. Così facendo la CPU ha un accesso ai dati più veloce, andando quindi a migliorare le performance del sistema. Durante l'esecuzione la poi CPU potrebbe anche scrivere in memoria, e per far questo essa si interfaccia al sistema di caching.
Studiando il sistema di caching uno dei problemi fondamentali è il problema della cache coherency, ovvero il problema della coerenza della cache. Il problema consiste nel decidere che valore dovrebbe essere ritornato durante la lettura di un dato replicato presente nel sistema di cache. Al fine di risolvere questo problema dobbiamo quindi decidere quale, tra le varie repliche, deve consegnare il dato a tutti i CPU-core che lo richiedono.
Osservazione: Non bisogna confondere i concetti di cache coherency e di memory consistency. Nella prossima lezione andremo a vedere il concetto di memory consistency, per adesso ci soffermiamo al concetto di cache coherency. Volendo riassumere brevemente la differenza tra i due concetti, la memory consistency riguarda definire il timestamp in cui i valori scritti dai program flow in esecuzione nel sistema possono essere letti nella memoria, mentre la cache coherency riguarda definire, durante una lettura da parte di un program flow, quale valore ritornare tra le varie copie presenti nel sistema di cache.
2.1 Definition
Al fine di avere un sistema di caching coerente, necessitiamo di rispettare le seguenti proprietà:
Casual consistency along program order: Una lettura da una locazione \(X\), che è stata precedentemente scritta dallo stesso processore che sta attualmente sta leggendo, ritorna l'ultimo valore scritto se, nel frattempo, nessun altro processore ha scritto nella locazione \(X\).
Con questo intendiamo che se un sistema di caching è cache coherent, allora è anche casualy consistent a livello del singolo program flow, ovvero mantiene la casualità a livello del data flow presente nel program order.
Avoidance of staleness: Una lettura da una locazione \(X\) da parte di un processore che segue una scrittura su \(X\) da parte di un altro processore, ritorna il valore scritto dall'altro processore se le due operazioni sono separate nel tempo, e se nel frattempo nessun altro processore scrive in \(X\).
Con questo stiamo dicendo che, quando un processore scrive su una locazione di memoria, questa scrittura deve eventualmente arrivare anche agli altri processori.
Cannot invert memory updates: Tutte le scritture su una data locazione di memoria \(X\) devono essere serializzate, in modo tale che tutti i processori vedono le scritture in \(X\) nello stesso ordine.
Notiamo come prima cosa che la definizione di cache coherency è stata data a livello della singola locazione di memoria, ovvero della singola linea di cache.
Notiamo poi che non necessariamente le operazioni di scrittura escono dal CPU core ed entrano nel sistema di caching in modo immediato. Il CPU core e il sistema di cache sono infatti disaccoppiati, e la loro interazione viene gestita da un terzo componente hardware, che prende il nome di store buffer. (Vedere lezione 02).
2.2 CC Protocols Basics
Al fine di avere un sistema di cache che sia cache coherent dobbiamo quindi definire un protocollo distribuito di cache coherency. Per fare questo però dobbiamo prima definire i seguenti oggetti:
L'insieme delle transazioni supportate dal sistema di cache.
L'insieme degli stati per ogni linea di cache (cache blocks).
L'insieme degli eventi gestiti dai controllers.
L'insieme delle transizioni che permettono alle linee di cache di passare da uno stato ad un'altro.
Il design dei protocolli di CC (Cache Coherency) è influenzato dai seguenti aspetti hardware:
Interconnection topology: ovvero il modo in cui i processori e il sistema di caching sono collegati tra loro.
Communication primitves: ovvero il modo in cui un componente comunica con gli altri componenti collegati tra loro.
Memory hierarchy features: che specificano come vengono gestiti i vari livelli di cache. In questo contesto, una memoria è detta inclusiva se le informazioni che ho nelle cache L1 sono anche contenute nelle cache L2 (le cache L1 sono quelle più vicine alla CPU).
Cache policies: che specificano come vengono gestite le varie scritture. Esempi di cache policy solo le policy write-through e write-back. Con una cache policy write-through appena scriviamo un dato in cache, questo dato viene anche salvato in RAM. Nella modalità write-back invece i dati salvati in cache non vengono immediatamente salvati anche in RAM in modo sincrono, ma vengono salvati in RAM tramite un ordine deciso da un particolare componente hardware che cerca di ottimizzare le interazioni tra i vari sistemi di memorizzazione.
Inoltre, diverse tipologie di protocolli di CC possono ottimizzare diversi aspetti, tra cui troviamo:
Latency: vogliamo minimizzare il tempo per completare una singola transazione.
Throughput: vogliamo massimizzare il massimo numero di transazioni completate in un'unità di tempo.
Space overhead: vogliamo minimizzare il numero di bits necessari per mantenere lo stato delle linee di cache.
2.3 CC Protocols Families
Le famiglie più importanti di CC protocols sono due, e rispondo in maniera diversa alla seguente domanda: quand'è che dobbiamo aggiornare le copie all'interno dei vari componenti di cache, quando uno di questi componenti viene aggiornato?
Invalidate protocols: In questa famiglia di protocolli quando un core scrive un dato nella sua componente di caching, tutte le altre copie dello stesso dato presenti nelle diverse componenti vengono invalidate. Soltanto chi scrive ha la copia aggiornata. Questa famiglia di protocolli permette di ridurre l'ampiezza di banda, andando però ad aumentare la latenza del sistema.
Update protocols: A differenza degli invalidate, gli update protocols aggiornano tutti i componenti in modo immediato. Incrementa l'ampiezza di banda per diminuire la latenza.
Notiamo che l'utilizzo degli update protocols assume che le CPU diverse lavorano su località simili, e che quindi se modifico il dato all'interno di una località, anche le cache delle altre CPU sono interessate alla scrittura, e dunque vogliono essere aggiornate. Questa ipotesi nei sistemi reali è chiaramete non verificata, e infatti sono gli invalidate protocols ad essere i protocolli più utilizzati nei moderni sistemi di caching.
3 Bus snooping
Con bus snooping intendiamo una sottofamiglia di protocolli CC, chiamati anche snooping cache coherency protocols, di tipo invalidanti (invalidate protocols). Questa sottofamiglia è caratterizzata dall'utilizzo di un broadcast medium per far parlare tra loro i vari controller, ciascuno dei quali è responsabile della gestione di una porzione del sistema di caching.
I vari CPU core dunque, al fine di interagire con la cache di sistema, e più in generale con la memoria, si interfacciano con questi controller, che a sua volta si interfacciano tra loro tramite il broadcast medium. Dandosi il turno quindi i controller possono utilizzare il broadcast medium per comunicare con tutti gli altri controllers. Questo permette di serializzare le transazioni che vengono eseguite nel sistema.
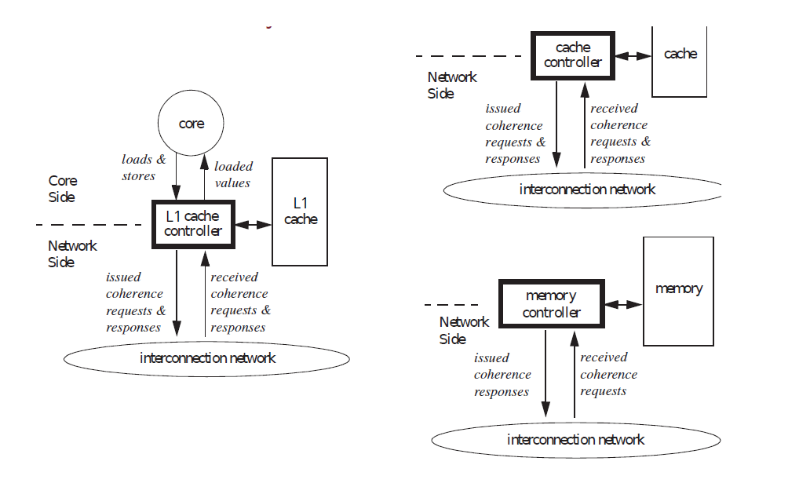
Andiamo adesso ad analizzare due implementazioni di protocolli CC che sono invalidanti e che utilizzano il broadcast medium per serializzare le transazioni.
3.1 MSI
Il protocollo MSI (Modified Shared Invalid) funziona nel seguente modo: ogni transazione di scrittura invalida tutte le altre copie della particolare linea di cache. Le transazioni di lettura, invece, funzionano come segue
Nel caso in cui la cache policy è write-through, una lettura prende l'ultima copia aggiornata dalla memoria.
Nel caso in cui la cache policy è write-back, una lettura può prendere o l'ultima copia aggiornata dalla memoria, oppure da un altro componente di caching.
Infine, i cambiamenti di stato avvengono invece nel seguente modo:
Un blocco di cache passa nello stato modificato il momento in cui viene scritto dal CPU-core. Questo automaticamente invalida tutte le copie dello stesso blocco presenti nelle altre cache.
Un blocco si trova nello stato di shared se è stato letto o da chi l'ha scritto, oppure da un'altro che l'ha letto a sua volta.
Un blocco è nello stato invalido se è stato scritto da un altro CPU-core.
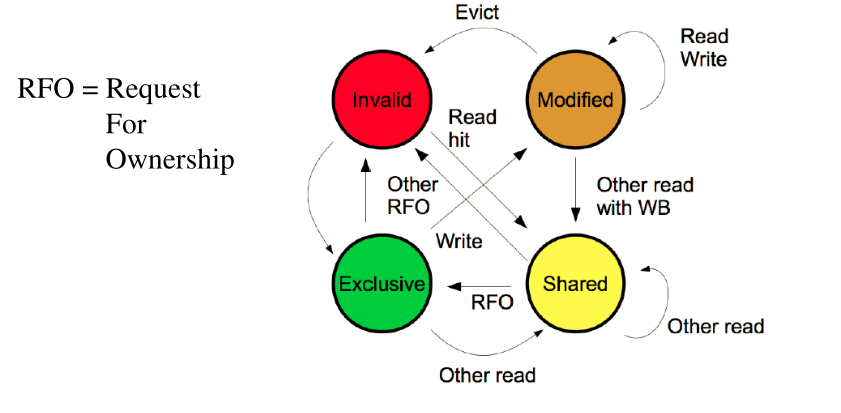
3.2 MESI
Con il protocollo MSI abbiamo che ogni volta che scriviamo su una linea di cache, viene eseguita una transazione distribuita per andare a invalidare il blocco scritto nelle altre cache. Questo non è performante per le operazioni di scrittura, specialmente per le operazioni di scrittura in cui solo un CPU-core ha un particolare cache-block.
Il protocollo MESI entra quindi in gioco come estensione del protocollo MSI, al fine di migliorarne le performance. Con il protocollo MESI abbiamo infatti i tre stati di prima, assieme ad un ulteriore stato, lo stato di Exclusive, che permette di ottenere un blocco di cache per una singola CPU.
Quando scriviamo su un blocco acquisito in modalità Exlusive, non necessitiamo di invalidare tutte le altre copie, in quanto gli altri controller sanno già che, se vogliono leggere quel blocco, lo devono leggere da noi.
Con questo protocollo l'invalidazione di un blocco avviene in due scenari: o andiamo a togliere il blocco dalla cache (evict operation); oppure un altro controller richieste l'esclusività del blocco tramite una RFO (Request For Ownership).
Il protocollo MESI può essere descritto dal seguente automa
4 False Cache Sharing
Il false cache sharing succede quando due program flow diversi lavorando, in modo indipendente, su due parti di una stessa cache line. Questo crea dei problemi di performance, in quanto ad ogni scrittura uno dei due processori deve prima acquisire l'esclusività del blocco di cache.
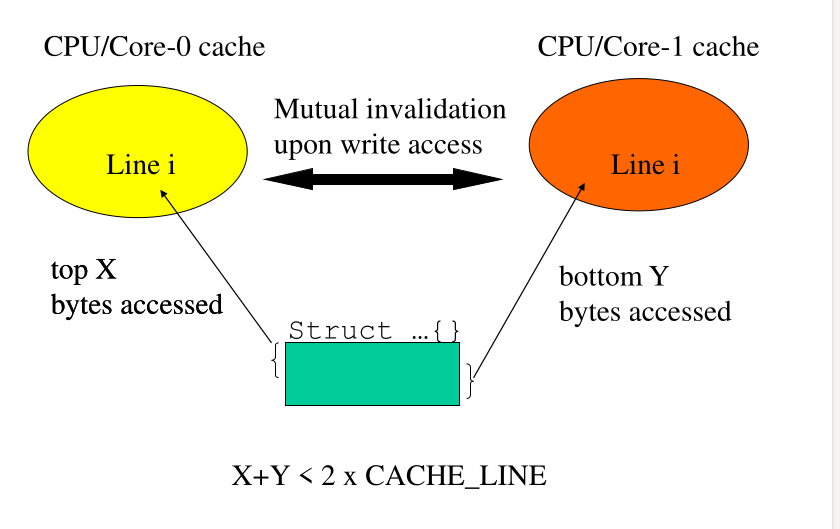
Bisogna quindi stare attenti a come inserire le informazioni rispetto alle linee di cache. In particolare bisogna inserire campi correlati vicini tra loro e separare campi che vengono gestiti in modo indipendente.
Al fine di gestire questo problema possiamo utilizzare degli allocatori di memoria "alligned". In particolare la funzione
#include <stdlib.h> int posix_memalign(void **memptr, size_t alignment, size_t size)
permette di allocare della memora in modo allineato rispetto alle cache lines.
4.1 RE: FALSE-CACHE-SHARING
Se andiamo a compilare il programma FALSE-CACHE-SHARING/fsc.c
senza flags,
gcc fcs.c -pthread
time ./a.out
otteniamo il seguente output
real 0m6.449s
user 0m12.103s
sys 0m0.080s
Notiamo che senza flag il programma fa lavorare due threads separati sulla stessa linea di cache. Se invece utilizziamo un particolare flag che serve per far lavorare i due threads su due linee diverse
gcc -DTARGET=64 fcs.c -pthread
time ./a.out
otteniamo
real 0m2.113s user 0m4.213s sys 0m0.008s
che è un valore valore molto più basso.
5 ASM Inline
L'ASM inline permette di embeddare nel codice C del codice assembly. Così facendo il programmatore ha più controllo sull'assembly che il compilatore altrimenti avrebbe potuto generare.
La sintassi da utilizzare è la seguente
__asm__ [volatile] [goto] ( AssemblerTemplate
[ : OutputOperands ]
[ : InputOperands ]
[ : Clobbers ]
[ : GoToLabels])
dove,
volatile: forza il compilatore a non eseguire nessun tipo di ottimizzazione.
goto: permette al codice assembly di saltare in ogni label presente nella lista GoToLabels.
AssemblerTemplate: rappresenta il codice assembly che vogliamo far eseguire.
OutputOperands: lista delle post condizioni a cui i dati devono essere sottoposti.
InputOperands: lista delle precondizioni a cui i dati revono essere sottoposti.
Clobbers: lista dei registri che vengono indirettamente coinvolti dal codice ASM presente, e il cui contenuto deve quindi prima essere salvato per poi essere ripristinato.
GoToLabels: insieme delle labels che posso inserire all'interno del codice assembly.
Quando scriviamo del codice in ASM inline, gli operandi possono essere abbreviati nei seguenti modi
6 FLUSH+RELOAD
Il side channel utilizzato negli attacchi visti di meltdown e spectre utilizza l'abilità di un processo che gira in user-mode di analizzare il tempo di accesso alla cache e inferire se una determinata pagina è stata caricata in cache oppure no. Andiamo quindi a risolvere il problema di come possiamo analizzare a livello software questo tempo di accesso.
L'attacco classico per analizzare il tempo di accesso alla cache prende il nome di FLUSH+RELOAD, ed è stato introdotto nel 2013 tramite il seguente paper per capire se un thread vittima ha effettuato l'accesso in una finestra temporale a determinate locazione di memoria. L'idea dietro all'attacco è la seguente:
Si esegue il flush della cache rispetto a un qualche dato condiviso con il thread che vogliamo attaccare.
Successivamente si accede nuovamente al dato condiviso.
A seconda del timing di accesso alla cache possiamo inferire se, nel frattempo, il dato è stato acceduto dal thread vittima.
L'implementazione di questo attacco nell'architettura x86
necessita quindi delle seguenti cose
Un resolution timer con una determinata resolution (precisione).
La possibilità di eseguire un cache-flush a livello di user-mode.
6.1 RDTSC
L'istruzione RDTSC offerta dall'architettura x86 permette di
leggere il registro real time clock, che contiene una maschera di
bit che viene incrementata di una unità ad ogni ciclo di clock, e
che quindi permette di contare i cicli di clock del
processore. L'istruzione carica il risultato in due registri: i 32
bit più significativi del risultato vengono caricati in
\(\text{EDX}\), mentre i 32 bit meno significativi vengono caricati
in \(\text{EAX}\).
Osservazione: Il registro che contiene il real time clock è un registro MSR (Module Specific Register). I registri MSR sono tipicamente dei registri che non vengono utilizzati per programmazione "convenzionale", ma piuttosto per fare della programmazione di sistema.
6.2 CFLUSH
L'istruzione CFLUSH offerta dall'architettura x86 permette di
flushare una specifica cache line dalla cache.
Notiamo che al fine di capire esattamente quanto tempo necessitiamo per fare una lettura in memoria, dobbiamo essere sicuri che l'ordine in cui le istruzioni vengono eseguite dall'hardware sia corretto. Se infatti mandiamo una CFLUSH e poi facciamo la lettura, ma l'hardware al fine di ottimizzare fa prima la lettura e poi esegue il flush, il tempo che andiamo a misurare non è il tempo che vogliamo misurare. Dovremo quindi capire, nella prossima lezione, come dire all'hardware di serializzare un determinato insieme di istruzioni tramite l'utilizzo delle memory fences.
6.3 RE 1: FLUSH-AND-RELOAD
Il codice FLUSH-AND-RELOAD/far.c fa vedere l'esecuzione di un
attacco di tipo FLUSH+RELOAD. A seguire una porzione commentata di
del codice necessario per calcolare il tempo di accesso in cicli di
clock per accedere all'indirizzo adrs.
// Calcola il tempo di accesso in cicli di clock necessario per // accedere all'indirizzo adrs. Ad ogni iterazione flusha il contenuto // della cache. unsigned long probe(char *adrs) { volatile unsigned long cycles; asm( "mfence \n" // Put a memory fence. The memory fence here is // used because this function is called inside a // cycle, and thus we want that each iteration is // executed before starting the new iteration. "lfence \n" // This Load fence is actually not needed. It can // be removed without any problems. "rdtsc \n" // Take real time clock value "lfence \n" // Put a load fence "movl %%eax, %%esi \n" // Move value from register EAX to // register ESI. Note that EAX contains // the least significat bits of the real time clock value. "movl (%1), %%eax \n" // Load the address given by the argument // adrs into register EAX. We are // interested in knowing if this memory // address was loaded into the cache. "lfence \n" // Put a load fence. All the instruction that came // before will not surpass the instruction that come // after. This is done so that the second rdtsc in // the code will actually get executed after the // first rdtsc and after having loaded the memory // location adrs. "rdtsc \n" // Take real time clock value "subl %%esi, %%eax \n" // Subtract the last clock value from the // first clock value to check how many // clock cycles have passed during the // load operation. "clflush 0(%1) \n" // Flush the cache line containg the address // adrs. We do this so we know that when we // do load the memory, if it is found to be // on the cache, it is because the victim's // program flow has loaded it, and not us. : "=a" (cycles) : "c" (adrs) ); return cycles; // Return the number of cycles needed to load the // address adrs. }
6.4 RE 2: FLUSH-AND-RELOAD
Il codice FLUSH-AND-RELOAD/cache-side-channel.c simula un attacco
FLUSH+RELOAD in cui abbiamo un thread (vittima), che accede a delle
porzioni di memoria di un array, mentre un altro thread
(attaccante), cerca di capire a quali porzioni dell'array il thread
(vittima) ha cercato di accedere di recente.
6.5 Do we need RDTSC?
Dato che tutti gli attacchi che abbiamo visto utilizzano l'istruzione RTDSC per ottenere il cronometro interno e dunque analizzare il tempo di accesso alla cache, si potrebbe pensare che togliendo la possibilità di eseguire l'istruzione RTDSC user-space, il nostro sistema potrebbe essere più sicuro.
Questo non è vero, in quanto è sempre possibile misurare un tempo relativo per l'accesso alla cache. Infatti, la cosa importante non è cronometrare in modo preciso ciò che succede nell'hardware, ma è sapere che un cache hit è significativamente più veloce di un cache miss.
Il running examle FLUSH-AND-RELOAD/far-emulated-timer.c mostra
come sia possibilie discriminare un cache-miss da un cache-hit
anche senza l'utilizzo dell'istruzione RTDSC.
6.6 Cache Inclusiveness
Abbiamo detto che un sistema di cache è inclusivo se il contenuto delle cache di livello più alto (quelle più vicine ai processori) è sempre contenuto (incluso) nelle cache di livello più basso.
Non tutti i chipsets hanno un sistema di caching inclusive. Per questi chip un attacco di tipo FLUSH+RELOAD potrebbe fallire se i due thread, il thread attaccante e il thread vittima, si trovano in due CPU-core diversi, e quindi non condividono la stessa cache L1.