AOS - 06 - HARDWARE INSIGHTS VI
1 Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 6/7
Argomenti:
Memory consistency
Sequential consistency
Total Store Order
x86 memory syncronization
2 Memory Consistency
Nella lezione precedente avevamo introdotto il concetto di coerenza del sistema di cache, che era definito a partire da una singola locazione di memoria. Andiamo adesso a definire il concetto di consistenza della memoria.
Iniziamo notando che la consistenza della memoria è definita rispetto a quello che i programmi cercano di fare sulla memoria. Mentre la coerenza del sistema di caching era definito a valle delle operazioni dei vari CPU-core, il problema della consistenza della memoria riguarda quanto la memoria sta riflettendo correttamente il flusso delle istruzioni macchina che stanno attraversando il CPU-core.
In particolare, in un contesto di concurrent data access, mentre la lettura di una locazione di memoria dovrebbe ritornare l'ultimo valore scritto, il vero problema riguarda la scrittura dei valori in memoria. Nelle architture moderne le scritture da parte dei vari CPU core che vanno in commit non vengono immediatamente scritte nella memoria fisica, in quanto esiste un componente che media l'interazione tra il CPU-core e la memoria.
Il modello di consistenza della memoria di una architettura definisce in quale ordine i CPU core percepiscono gli accessi concorrenti (anche in scrittura) verso la memoria. Il tutto è quindi basato sull'ordine di accesso alla memoria, e non necessariamente sul tempo necessario per i vari accessi. Questo significa che la coerenza e consistenza della memoria sono due concetti ortogonali. La coerenza della memoria infatti dipende dal sistema di caching, mentre la consistenza della memoria dipenda da quanto la memoria riflette ciò che sta succedendo all'interno dei vari CPU core.
2.1 Terminology
Al fine di definire modelli di consistenza della memoria necessitiamo l'introduzione dei seguenti concetti:
Program order: Sequenza degli accessi in memoria codificati nel program flow che gira su un CPU core. (Visione locale al singolo core)
Visibility order: Ordine di tutti gli accessi alla memoria, osservati come se fossi un osservatore esterno. (Visione globale al livello di sistema)
2.2 Sequential Consistency
A seguire la definizione, presa da Lamport, 1979:
A multiprocessor system is sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
Un modello di memoria è sequential consistency se posso sequenzializzare gli accessi in memoria di ogni program flow mantenendo l'ordine codificato nel program flow.
Andiamo adesso a vederne un esempio di sequential consistency. Supponiamo di avere due program flow che girano su due CPU core diversi e che eseguono le seguenti istruzioni
CPU1
-----
[A] = l; (operazione chiamata a1)
[B] = l; (operazione chiamata b1)
CP2
----
u = [B]; (operazione chiamata a2)
v = [A]; (operazione chiamata b2)
A seconda della nostra architettura di memoria possiamo avere un ordine diverso di accessi in memoria. Alcuni ordini garantiranno una sequential consistency e altri no.
Il seguente accesso alla memoria è detto sequentially consistent, in quanto il visibility order (visione globale) non viola il program order di nessun program flow
a1, b1, a2, b2
Il seguente acesso alla memoria invece non è sequentially consistent, in quanto il visibili order (visione globale) viola il program order del program flow eseguito dalla CPU1.
b1, a2, b2, a1
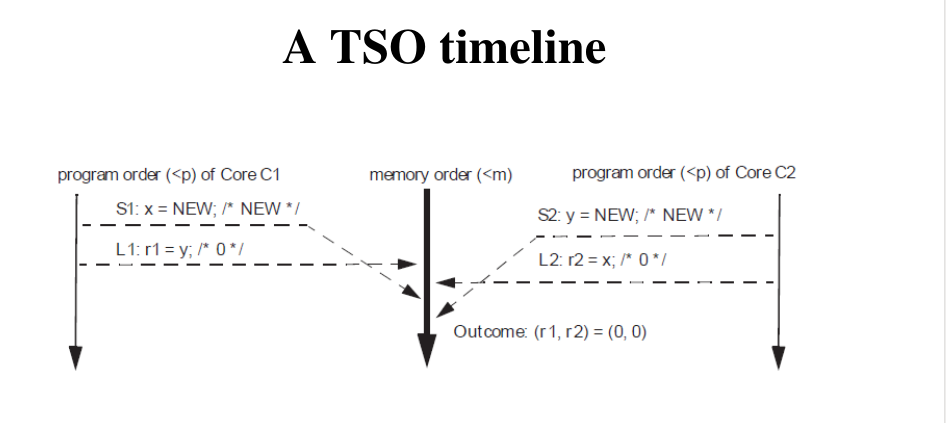
2.3 Total Store Order
Le architetture moderne, per motivi di performance e scalabilità, non garantiscono la sequential consistency. Molti chipset offrono un altro modello di consistenza della memoria, che prende il nome di Total Store Order (TSO).
La sequential consistency è infatti molto inconveniente in termini di performance della memoria. Per far capire il perché questo è vero consideriamo il seguente esempio: supponiamo di avere due istruzioni nel nostro program flow, \(I_1\) e \(I_2\). Sia \(I_1\) che \(I_2\) sono istruzioni di write in memoria, ma \(I_1\) deve scrivere su un blocco di memoria che attualmente non è esclusivo al CPU-core, mentre \(I_2\) deve scrivere su un blocco di memoria che è già nello stato esclusivo. Se dovessi sequenzializzare gli accessi alla memoria in modo tale che, osservandoli esternamente, l'ordine delle operazioni sarebbe in accordo con l'ordine in cui sono codificate nel program flow, sarei costretto ad aspettare il tempo necessario per effettuare la transazione MESI e ottenere l'esclusività del blocco in cui voglio scrivere con \(I_1\) prima di poter eseguire \(I_2\). Tramite il TSO siamo invece in grado di fare la seguente cosa: eseguo \(I_2\) e scrivo il risultato in un buffer spugna intermedio (chiamato store buffer). Il risultato sarà poi reso percepibile agli altri CPU-cores solo dopo aver preso l'esclusività del blocco di cache che mi serve per eseguire \(I_1\).
Le architetture di memoria di tipo TSO si basano sul fatto che le scritture eseguite dal software non sono equivalenti, in termine di tempistiche, agli update di memoria effettuati dall'hardware. In queste architetture esiste infatti un componente che si trova in mezzo e che decide il momento più conveniente in cui aggiornare la memoria fisica con le scritture effettuate dal software. Questo componente intermedio è chiamato store buffer, si trova tra il CPU core e il sistema di cache e non è una risorsa esposta all'ISA.
Dunque, il TSO si basa sulla seguente nozione
Scrivere sulla memoria != Aggiornare in modo sincrono la memoria.
2.3.1 Store Bypass
Lo store bypass avviene quando una scrittura supera un'altra che ancora deve essere eseguita. Notiamo che uno store bypass non rompe mai un program flow, in quanto per come è strutturata l'architettura, la lettura dei dati avviene sempre effettuata prima dallo store buffer, e se non è possibile dalla memoria. Quindi, quando ho una lettura successiva ad una scrittura, la lettura vede sempre il valore aggiornato, anche se questo non è effettivamente riportato in memoria.
Quello che può succede però è che le scritture pendenti, ovvero le scritture che si trovano ancora nello store buffer e che ancora devono aggiornare la memoria, non vengono viste dai program flow in esecuzione sugli altri CPU-core. Questo è la ragione dietro al fatto che nelle architetture TSO non è possibile implementare degli algoritmi di sincronizzazione basati su semplici read e write di dati condivisi (vedere Bakery algorithm, Dekker's algorithm).
Infine, con una architettura di tipo TSO, anche l'ordine delle LOAD può essere invertito, e si possono avere delle LOAD che leggono dei dati dallo store buffer, e che quindi vengono perse rispetto alla visione globale degli accessi in memoria.
3 x86 Memory Synch
L'architettura x86 utilizza un modello di consistenza della memoria di tipo TSO (Total Store Order). Questo significa che l'hardware non garantise che le operazioni di scrittura vengono effettuate in ordine, e non garantisce nemmeno che le letture vengono effettuate in ordine. Questo crea dei seri problemi, specialmente per lo sviluppo di programmi concorrenti, e quindi in particolare per lo sviluppo di un sistema operativo. Nasce quindi il problema di offrire al programmatore delle primitive che permettono di controllare il comportamento dello store buffer e delle operazioni in memoria. In altre parole, dobbiamo sapere come poter garantire un certo livello di sincronizzazione tra le varie operazioni che effettuiamo in memoria.
3.1 Memory Fences
Al fine di risolvere questo problema sono state introdotte le memory fences, che sono primitive offerta dall'ISA di x86 per gestire la sincronizzazione delle operazioni in memoria. Queste primitive hanno però dei costi, e dunque devono essere utilizzate solamente nei casi in cui l'ordine di visibilità globale non deve essere invertito.
Le memory fences sono tre, e sono riportate a seguire:
SFENCE (Store Fence): Esegue una serializzazione di tutte le istruzioni store-to-memory (scrittura a memoria) codificato nel program flow prima dell'istruzione SFENCE. Questa operazione di serializzazione garantisce la visibilità globale di tutte le istruzioni di STORE che precedono la SFENCE prima di tutte le istruzioni di STORE che seguono la SFENCE.
LFENCE (Load Fence): Stessa cosa di SFENCE, ma questa volta per le LOAD, e non per le STORE.
MFENCE (Memory Fence): Stessa cosa di SFCENE e LFENCE, ma vale più generalmente sia per le LOAD che per le STORE.
3.2 Serializing Instructions
Le istruzioni di tipo FENCES sono istruzioni serializzanti (serializing), ovvero sono istruzioni che specificano i punti del program flow che non possono essere mischiati tra loro, ovvero i punti in cui le istruzioni che vengono prima non possono superare quelle che vengono dopo.
Le istruzioni di tipo FENCES non sono le uniche istruzioni serializzanti. Altre istruzioni di tipo serializzanti sono CPUID, LGDT, LIDT, etc...
Queste ultime istruzioni però sono serializzanti perché causano lo squash della pipeline, e causano lo squash della pipeline in quanto, molto spesso, sono istruzioni che vanno a cambiare il firmware che dice all'hardware come processare le istruzioni nella pipeline. Ad esempio, su x86 è possibile disabilitare la paginazione e processare ogni accesso in memoria utilizzando direttamente l'indirizzo fisico; l'istruzione che permette questo è inevitabilmente una istruzione serializzante, in quanto causa lo squash della pipeline.
Altre istruzioni possono essere prefissate con la parola LOCK per diventare istruzioni serializzanti. Tra queste istruzioni troviamo
3.3 RMW Instructions
Un'altra classe di istruzioni serializzanti negli accessi a memoria sono le istruzioni RMW, che permettono di caricare un dato dalla memoria, modificarlo, ed eventualmente scrivere il contenuto modificato nella memoria.
L'istruzione più importante per eseguire questo tipo di attività in x86 è l'istruzione CMPXCHG, che permette di comparare e di aggiornare un dato valore nello stesso ciclo di clock.
Le istruzioni RMW sono molto spesso utilizzate per creare degli
SPIN-LOCK, che sono alla base di costrutti come il
pthread_mutex_lock() e il pthread_mutex_trylock() presenti
nella libreria <pthread.h> .
Al fine di eseguire in modo atomico istruzioni di tipo RMW l'idea è quella di bloccare il memory bus in caso di scrittura su più blocchi di cache. Se invece devo modificare un solo blocco di cache posso semplicemente sfruttare il funzionamento di base di MESI, andando a prendere in exclusive il blocco che voglio aggiornare.
Per rendere l'istruzione CMPXCHG serializzante devo introdurre il prefisso LOCK. Se non lo faccio infatti l'istruzione non è più serializzante e quindi il risultato della scrittura può rimanere nella memoria tampone dello store buffer e non essere visibile agli altri CPU-core.
3.4 gcc built-ins
gcc offre le seguenti built-in function per gestire le memory fences e le istruzioni di compare and exchange.
void _mm_sfence(void); void _mm_lfence(void); void _mm_mfence(void); bool __sync_bool_compare_and_swap(type *ptr, type oldval, type newval)
3.5 Trylock via CMPXCHG
Questo codice presenta un semplice modo di implementare un trylock tramite una istruzione CMPXCHG effettuta in modo serializzante tramite la keyword LOCK. Tramite la LOCK CMPXCHG siamo quindi in grado di controllare una locazione di memoria ed eventualmente di scriverci sopra in modo atomico. Se la locazione di memoria è 0, allora la modifico scrivendoci 1 e inizio ad eseguire la regione critica, invece se è già 1, allora vuol dire che la regione critica è già occupata.
int try_lock(void *uadr) { unsigned long r = 0; asm volatile( "xor %%rax, %%rax \n" // Azzero il contenuto del // registro RAX. Il registro RAX // è utilizzato in modo implicito // dall'operazione CMPXCHG. "mov $1, %%rbx\n" // Carico il valore 1 nel // registro RBX. Il // registro RBX è // utilizzato // dall'operazione // CMPXCHG. "lock cmpxchg %%rbx, (%1)\n" // la CMPXCHG confronta // il registro RAX con il // contenuto puntato da // uadr, e se sono uguali // scrive nell'indirizzo // puntato da uadr il // contenuto del registro // RBX. "sete (%0)\n" // se la cmp ha avuto un // esito positivo scrive // nella variabile r. : : "r" (&r), "r" (uadr) : "%rax", "%rbx" ); return (r) ? 1 : 0; }
3.6 Active-Wait Barrier
Il seguente codice mostra un esempio di una active-wait barrier, in cui i thread aspettano che tutti siano entrati nella corrente barriera per passare a quella successiva e ripetere così il ciclo.
https://gcc.gnu.org/onlinedocs/gcc-4.1.0/gcc/Atomic-Builtins.html
long control_counter = THREADS; long era_counter = THREADS; int barrier(void){ int ret; // Busy waiting in cui I thread aspettano che tutti siano pronti per // passare alla nuova barriera. while(era_counter != THREADS && control_counter == THREADS); /* Permette di decidere chi è il winner della race, ovvero chi entra per primo nella barriera. Il primo thread che esegue questa funzione infatti confronta control_counter con THREADS e, notando che sono uguali, assegna a control_counter il valore 0. Dato che l'operazione è effettuata in modo atomico, tutti gli altri thread quando eseguono la funzione vedono che control_counter != THREADS, e quindi procedono oltre, ovvero entrano nella barriera. */ ret = __sync_bool_compare_and_swap(&control_counter,THREADS,0); // Solo il winner avrà ret != 0, e quindi solo il winner potrà // azzerare il contenuto di era_counter. if( ret ) era_counter = 0; // Ogni thread scrive, in modo atomico, su control_counter, // affermando di essere entrato nella nuova barriera. __sync_fetch_and_add(&control_counter,1); // Busy waiting in cui I thread aspettano che tutti entrano nella // nuova barriera. while(control_counter != THREADS); // Ogni thread scrive, in modoa atomico, su era_counter, affermando // di voler uscire dalla nuova barriera. __sync_fetch_and_add(&era_counter,1); return ret; }
4 Scalability
Notiamo che la semplice soluzione del trylock per il problema della sincronizzazione non è una soluzione scalabile. Siamo quindi interessati ad una soluzione più scalabile sfruttando l'architettura TSO e i meccanismi di FENCE.
L'idea è quella di implementare degli algoritmi di sincronizzazione e coordinamento non-bloccanti. Un algoritmo di questo tipo, che però è solo parzialmente non-bloccante, è chiamato Read Copy Update, ed è inizialmente stavo sviluppato per il kernel Linux.
Gli algoritmi di sincronizzazione non-bloccanti si basano sull'esecuzione di atomiche RMW, che permettono di capire se posso o non posso modificare determinate strutture dati. A differenza di quelli bloccanti però, se trovo che una struttura è già stata presa da un altro thread, al posto di bloccarmi continuo la mia esecuzione.
Osservazione: Notiamo che una soluzione scalabile al problema della sincronizzazione è fondamentale per supportare la tecnologia della virtualizzazione. Utilizzando delle macchine virtuali infatti, i thread in esecuzione vengono eseguiti su dell'hardware simulato. Ricordiamo a tale fine che la virtualizzazione è possibile grazie al concetto di CPU-STEAL, che permette all'host che ospita varie macchine virtuali di deschedulare un thread in una macchina virtuale per mandare in esecuzione un altro thread di un'altra macchina virtuale. Questo implica che la durata delle sezioni critiche che vengono eseguite da threads di macchine virtuali possono essere potenzialmente molto lunghe. Dobbiamo quindi trovare degli schemi di sincronizzazione più flessibili e meno bloccanti.
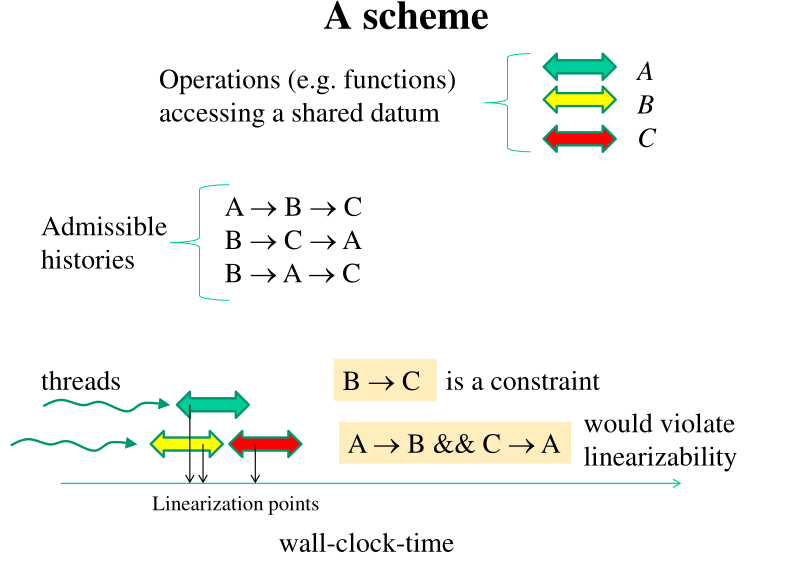
4.1 Linearizability
Una struttura dati condivisa è detta linearizzabile se le operazioni che vengono effettuate sulla struttura dati appaiono sempre come sequenzializzabili. In particolare questo è verificato se,
Tutti i metodi e funzioni di accesso alla struttura dati, anche se richiedono più cicli di clock, possono essere visti come se il loro effetto si materializzasse in uno specifico punto nel tempo.
Tutte le operazioni che sono in over-lap time wise possono essere ordinate in base al punto in cui selezioniamo la materializzazione dell'operazione.
La linearizzabilità è una restrizione della serializzabilità, la quale concerne strutture dati multiple.
Per poter definire delle strutture dati linearizzabili, dobbiamo quindi cercare di definire i punti in cui materializziamo la nostra operazione sulla struttura dati tramite delle atomiche RMW. In generale quindi la sfida nel costruire algoritmi non bloccanti è rappresentata dal cercare di bilanciare le seguenti cose:
Eseguire il numero minore possibile di atomiche
Funzionalmente a quello che sta succedendo, ovvero funzionalmente a quello che gli altri fanno devo capire cosa fare e slittare eventualmente l'esecuzione di un pezzo di codice.
A seguire un esempio di linearizzabilità.