AOS - 07 - HARDWARE INSIGHTS VII
1 Lecture Info
Data:
Sito corso: link
Slides: AOS - 1 HARDWARE INSIGHTS
Progresso unità: 7/7
Argomenti:
Linearizability
Lock-freedom
Wait-freedom
Lock-free insertion/deletion on linked lists
Algoritmo ARC (Anoynmous Reader Counting)
RCU
Vettorizzazione
Introduzione: Abbiamo visto nella scorsa lezione che l'architettura x86 non garantisce la sequential consistency per gli accessi alla memoria, ma garantisce il TSO (Total Store Order).
Al fine di sincronizzare gli accessi alla memoria di thread che lavorano in modo concorrente abbiamo poi visto l'utilizzo delle memory fences. Tramite l'utilizzo delle fences e delle istruzioni RMW (Read Modify Write), siamo stati in grado di implementare uno spinlock, che può essere utilizzato per sincronizzare gli accessi alla memoria condivisa. La soluzione tramite spinlock però non è scalabile, ed è quindi necessario trovare una soluzione che permette di ottenere una sincronizzazione più performante e scalabile.
2 Scalability
É possibile utilizzare le facility hardware per permettere a dei thread the lavorano in modo concorrente di accedere ad una zona di memoria condivisa in modo coerente e consistente senza dover racchiudere gli accessi alla memoria condivisa in una sezione critica controllata tramite uno spinlock?
Notiamo che le facility offerte dall'hardware per la sincronizzazione della memoria sono le memory fences e le istruzioni RMW. Queste, da sole, non permettono di ottenere ciò che vogliamo. Dobbiamo quindi costruire sopra questo hardware un algoritmo, scritto nel software, che permette di sincronizzare dei thread in modo non-bloccante.
Come vedremo, implementare degli algoritmi non-bloccanti per l'accesso e la sincronizzazione di zone di memoria condivise è molto complesso. Molto spesso quindi si sceglie di implementare algoritmi che sono solo parzialmente non-bloccanti al fine di diminuire la complessità ma ottenere comunque una soluzione scalabile. Nel kernel linux è implementato un algoritmo non bloccante, che prende il nome di RCU (Read Copy Update).
2.1 Linearizability
Il primo step da prendere per definire degli algoritmi non-bloccanti che lavorano in modo corretto è proprio definire cosa vuol dire lavorare in modo corretto su strutture dati condivise tra vari thread. A tale fine introduciamo il concetto di linearizzazione.
Una struttura dati condivisa è detta linearizzable, se l'effetto delle esecuzioni di qualsiasi operazione \(X\), \(Y\) e \(Z\), sulla struttura dati, eventualmente eseguite anche in modo concorrente tra loro, è identico all'effetto che avrei ottenuto se avessi eseguito le operazioni in una specifica sequenza, eseguendo una operazione dopo l'altra.
Al fine di pensare alla linearizzabilità in un contesto concorrente dobbiamo considerare che queste operazioni hanno \(i)\) una durata, e \(ii)\) possono essere eseguite sullo stesso thread. Nel secondo caso, ovvero quando abbiamo due operazioni \(B\) e \(C\) che vengono eseguite sullo stesso thread, l'unico ordine possibile in cui la struttura dati è linearizzabile è l'ordine \(B \to C\), che rappresenta quindi un vincolo di linearizzabilità. Se invece abbiamo due operazioni che vengono esegute su thread diversi, allora queste operazioni possono essere concorrenti nel tempo oppure no.
Al fine di costruire una struttura dati linearizzabile dobbiamo far si che le operazioni effettuate in modo concorrente eseguino specifiche attività in memoria che fanno capire l'ordine secondo cui queste operazioni concorrenti si stanno effettivamente materializzando sulla struttura dati. L'idea è quindi quella di utilizzare le istruzioni RMW e le memory fences per creare dei punti di linearizzazione per la struttura dati. ù
NOTA BENE: Con questo approccio, l'algoritmo di sincronizzazione non-bloccante è codificato nelle operazioni stesse che eseguo sulla struttura dati, e non è più un algoritmo esterno che, ad esempio, prende un lock.
2.2 Locks vs RMW
Come abbiamo detto quindi, l'idea è quella di utilizzare delle istruzioni RMW per implementare dei punti di linearizzazione durante l'esecuzione delle operazioni sulla struttura dati condivisa. Questi punti di linearizzazione poi possono essere utilizzati per ottenere la storia delle operazioni linearizzate.
Ricordiamo però che le istruzioni RMW possono fallire. Il fallimento di una istruzione RMW quindi può portare ad un diverso ramo di esecuzione che implica un diverso punto di linearizzazione, che può quindi avvenire prima o dopo il previsto (ovvero prima o dopo il punto che sarebbe stato il punto di linearizzazione se la prima istruzione RMW non avesse fallito).
L'utilizzo di locks basati su RMW permette di linearizzare in modo banale le operazioni. Tramite un lock infatti i vari punti di linearizzazione sono sempre disgiunti tra loro, in quanto un solo thread può avere accesso alla regione critica (struttura dati condivisa) in un dato momento.
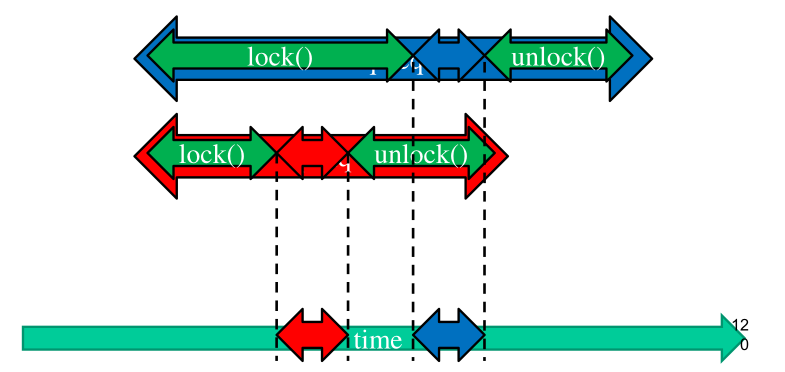
Ovviamente, anche se i locks ci permettono di linearizzare le operazioni effettuate, la soluzione dei locks come abbiamo menzionato prima non è una soluzione scalabile, e quindi dobbiamo cercare un modo alternativo per linearizzare le operazioni utilizzando delle primitive RMW
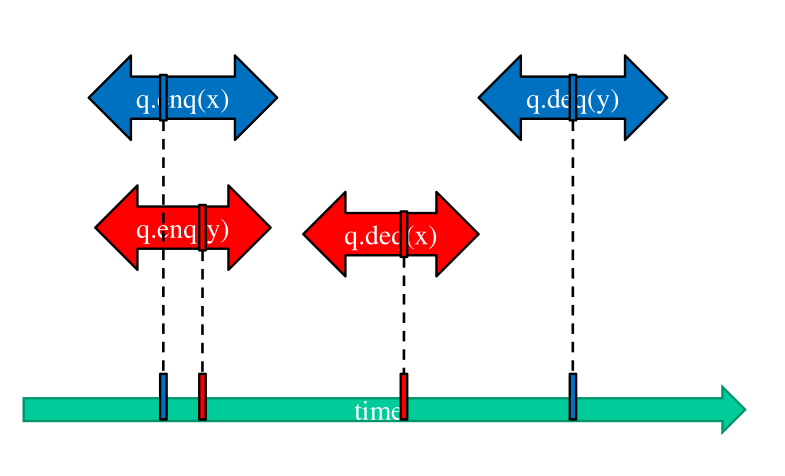
3 Non-Blocking Algorithms
La classe degli algoritmi non-bloccanti è suddivisa in due sottoclassi. Ciascuna sottoclasse offre determinate proprietà a seconda di quello che può succedere ai threads in esecuzione. Le sottoclassi sono:
Lock-freedom:
Qualche istanza di chiamata ad una funzione che tocca la struttura dati condivisa può terminare correttamente in un tempo finito.
Tutte le istanze terminano correttamente o no in un tempo finito.
Wait-freedom:
Tutte le istanze di chiamata a funzioni che toccano la struttura dati condivisa terminano con successo in un tempo finito.
Notiamo che la wait-freedom è più forte della lock-freedom, in quanto nella wait-freedom stiamo dicendo che ogni chiamata esegue un lavoro utile, indipendente se le RMW falliscono oppure no, e quindi tutti i thread fanno progresso, mentre nella lock-freedom il progresso è garantito solamente ad un thread.
I vantaggi della sincronizzazione non-bloccante sono svariati. In particolare troviamo i seguenti:
Tutti i thread possono terminare le loro operazioni in un tempo finito.
Anche se un thread fallisce, o perché viene de-schedulato o perché riceve un segnale particolare, gli altri possono comunque continuare ad eseguire le loro operazioni sulla struttura dati.
Questa proprietà in particolare è fondamentale quando si lavora con i moderni sistemi che usano pesantamente per la virtualizzazione approcci di tipo CPU-stealing.
Utilizzando un classico sistema di sincronizzazione bloccante (e.g. spin-lockcs) abbiamo che il numero di passi di computazione necessari per finalizzare una determinata funzione è determinato da i) il comportamento del thread che attualmente possiede il lock; ii) la sequenza delle lock acquisitions.
3.1 Lock-Freedom
Gli algoritmi lock-free sono basati sui concetti di abort e retry. L'idea è che, in caso del fallimento di una WMR, un thread decide di eliminare l'operazione corrente (abort) e successivamente di rifarla (retry).
In particolare, se due operazioni sono incompatibili nell'ordinamento linearizzato, ovvero se una RMW causa ad un'altra RMW di fallire, una delle due operazioni può essere accettata e l'altra rifiutata.
Anche se un eventuale abort/retry causa delle perdite di performance, l'assunzione che si fa per poter applicare questi algoritmi è che non ci saranno tanti aborts, e quindi che il tempo sprecato non sarà troppo elevato.
L'idea alla basa della lock-freedom è quindi quella di sviluppare delle strutture dati "resilienti ai conflitti", ovvero che definiscano delle operazioni che lavorano su varie parti della struttura dati, e che quindi raramente entrano in conflitto tra loro.
Non sempre è possibile utilizzare un approccio lock-freedom. Andiamo adesso a vedere come poter implementare le operazioni base di inserimento ed eliminazione di un nodo in una linked list.
3.1.1 Linked List
Per eseguire l'operazione di inserimento, possiamo:
Creare il nuovo nodo da inserire;
Collegare il nuovo nodo al successivo nella lista, a seconda di dove lo vogliamo inserire;
Utilizzare una CAS (Compare And Swap) per modificare il puntatore del nodo precedente e per farlo puntare al nuovo nodo che vogliamo inserire.
Notiamo che durante l'inserimento può succedere che, nella concorrenza, un alto thread potrebbe voler inserire un altro nodo esattamente nello stesso punto. In questa situazione un thread sarà il winner, e un thread sarà il loser. Il thread loser riproverà con un retry a reinserire il nodo che voleva inizialmente inserire.
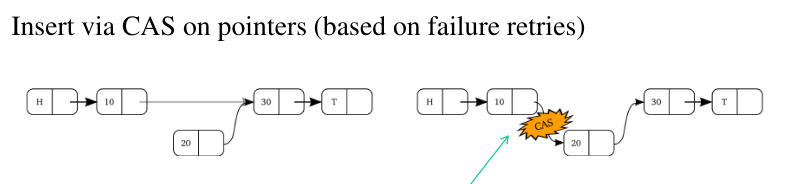
Per quanto riguarda invece l'eliminazione di un nodo da una lista, la situazione è più complessa. Non basta infatti semplicemente cambiare il puntatore del nodo precedente al nodo che volevamo eliminare tramite una CAS, in quanto nella concorrenza un thread potrebbe usare come sorgente per l'aggiunta di un nuovo nodo il nodo che noi volevamo eliminare.

Per risolvere questo problema dobbiamo introdurre il concetto di cambio di stato logico di uno degli elementi nella struttura dati condivisa. Il cambio di stato logico in questo caso eliminazione consiste nel comunicare agli altri thread che l'elemento in questione non fa più parte della lista, anche se è ancora allocato in memoria. Le operazioni da eseguire per eliminare un nodo possono essere quindi schematizzate come segue
Attraversiamo la lista per arrivare al nodo che vogliamo eliminare;
Eseguiamo una CAS per cambiare il bit di validità del nodo, andando a indicare che il nodo non fa più parte della lista (anche se è ancora istanziato in memoria).
Così facendo le successive CAS che potrebbero utilizzare quel nodo per agganciare un nuovo elemento nella lista falliscono, e quindi abbiamo effettivamente eliminato il nodo.
Per fare questo dobbiamo quindi avere all'interno di ogni nodo una unica informazioni accessibile tramite accessi alla memoria atomici che mi dice sia dove si trova il nodo successivo, e sia se il bit è valido oppure no.
Una volta che ho eliminato logicamente il nodo dalla lista posso poi a valle fare un ricompattamento della lista andando ad eliminare tutti i nodi non validi.

3.2 Wait-Freedom
Andiamo adesso a vedere come poter risolvere il problema di permettere ad un writer di postare in modo atomico del nuovo contenuto a N readers. Questo problema è chiamato wait-free atomic \((1, N)\) register.
Un registro atomico è una zona di memoria dove un writer può inserire delle nuove informazioni e un reader può accedere e leggere le informazioni inserite.
Notiamo che se il registro atomico è a 64 bit il problema è risolto in modo banale utilizzando le istruzioni RMW offerte dall'ISA in uso. Il problema è quindi interessante quando il registro atomico è di taglia arbitraria.
Una soluzione banale è la seguente:
Quando il writer vuole scrivere un nuovo dato, utilizza un buffer diverso dal buffer attualmente utilizzato dagli N readers.
Una volta che il writer ha finito di scrivere le informazioni sul nuovo buffer, atomicamente tramite una CAS su un pointer cambia.
Notiamo però che questa soluzione non può essere implementata, in quanto richiederebbe una memoria infinita. Il writer infatti non può semplicemente deallocare il vecchio buffer, in quanto qualche reader potrebbe ancora essere impegnato a leggerlo.
3.2.1 ARC
Al fine di risolvere questo problema necessitiamo di un algoritmo più complesso. La letteratura ci dice che per risolvere questo problema necessitiamo di utilizzare almeno N+2 buffers. L'algoritmo che stiamo per descrivere prende il nome di Anonymous Reader Counting (ARC) e risolve il problema di interesse utilizzando esattamente N+2 buffers.
I buffer utilizzati hanno le seguenti funzioni:
N buffers leggibili dai readers, in quanto ciascun reader può leggere una versione diversa.
1 buffer per memorizzare l'ultima versione, non accessibile dai readers.
1 buffer da utilizzare per memorizzare un contenuto nuovo.
L'algoritmo funziona come segue:
Viene utilizzata una variabile a 64 bit per sincronizzare i vari readers e il writer.
La variabile è divisa in due campi, di cui il primo (i 32 bit più significativi) contiene l'indice al buffer in cui è stato scritto l'ultimo valore accessibile ai readers, mentre nel secondo campo (i 32 bit meno significativi), contiene il numero di readers che hanno deciso di leggere quel buffer.
Quando un reader vuole leggere l'ultimo buffer postato dal writer, se capisce che è stato postato un nuovo contenuto, in modo atomico prende il nuovo indice del buffer e incrementa il numero dei reader che stanno leggendo quel contenuto.
Prima di andare a leggere il nuovo buffer il reader fa un incremento atomico sui metadati associati al buffer che stava leggendo. Questi metadati vengono utilizzati dal writer per capire quando tutti i reader hanno finito di leggere un particolare buffer, in modo da poterlo riutilizzare. Il writer infatti scrive solamente nella copia del buffer tale che il numero dei reader che sono usciti è uguale al numero dei reader che sono entrati, ovvero nel buffer che attualmente non è utilizzato da nessun reader. Esiste una dimostrazione formale che tale buffer esiste sempre.
L'algoritmo ARC è un algoritmo wait-free in quanto non ci sono tempi di attesa. Inoltre questo algoritmo è in grado di linearizzare le operazioni di lettura senza bisogno di eseguire delle istruzioni RMW. Questo permette all'algoritmo ARC di essere scalabile.
L'inizializzazione dell'algoritmo è fatta nel seguente modo
procedure INIT(content, size)
for all slot in [0, N+1] do
register[slot].size = 0
register[slot].r_start = 0
register[slot].r_end = 0
MEMCOPY(register[0].content, content, size)
register[0].size = size
current = N
3.3 Buffer re-usage
Gli approcci basati su RMW ci permettono di capire qual'è lo stato in cui si trova un elemento in una struttura dati condivisa. Il problema però è che non è possibile sapere chi ancora sta utilizzando per particolare elemento, e quindi non possiamo deallocare quella memoria e utilizzarla per un'altra cosa, in quanto altrimenti eventuali thread ancora a lavoro sull'elemento deallocato si potrebbero ritrovare in zone di memoria a loro non pertinenti. Questo potrebbe portare anche a delle gravi problematiche di sicurezza.
Il problema della garbage collection per algoritmi non-bloccanti è molto importante, e molto spesso quando si definisce un algoritmo non bloccante si definisce anche un garbage collector non bloccante. Questo problema è affrontato direttamente dalla tecnica RCU (Read Copy Update).
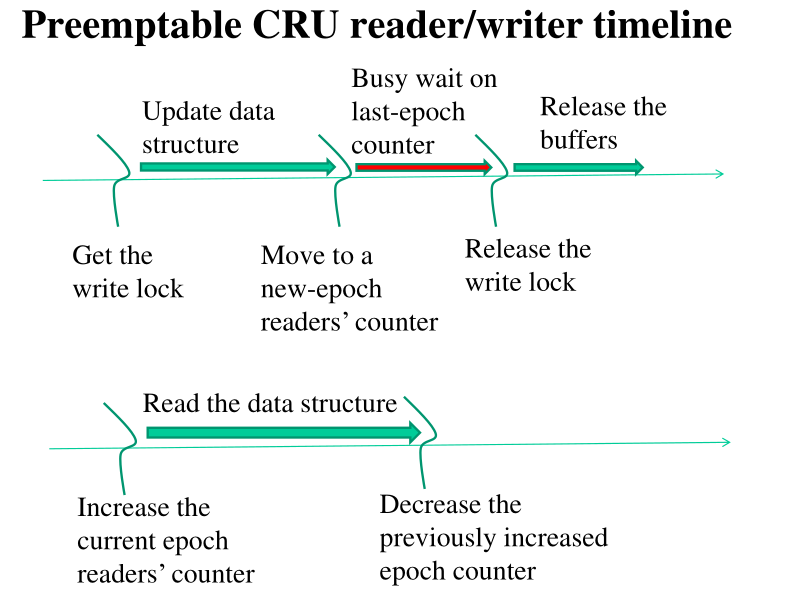
4 RCU
L'idea fondamentale di RCU è quella di avere, in un dato momento, un solo writer e più readers che interagiscono su una struttura dati. I writers lavorano in mutua esclusione, e la concorrenza è presente solamente tra readers e il writer del momento.
La sincronizzazione RCU funziona bene su strutture dati in cui si accede molto più in lettura che in scrittura. Non a caso RCU è stato sviluppato all'interno del kernel linux, in cui ci sono molte strutture dati che vengono usate molto più in read che in write.
Per attuare questa idea si procedere nel seguente modo:
I link di uscita di porzioni della struttura dati che sono state logicamente eliminate non vengono distrutte fino a quando tutti i readers sono passati alla nuova versione della struttura dati, e non si trovano più in quella modificata.
Per non far crescere troppo la memoria però, dopo un determinato grace period (periodo di grazia), la memoria associata alle porzioni della strutura dati che erano state logicamente eliminate viene reallocata e utilizzata per scrivere nuove cose. Il grace period permette a tutti i readers di uscire dalle vecchie porzioni della struttura dati.
Per implementare questo meccanismo di sincronizzazione è necessario essere in grado di suddividere i readers in due gruppi: i readers old che sono readers che si trovano in porzioni modificate della struttura dati, ad esempio porzioni che sono state logicamente eliminate, ed i readers new, che si trovano nella versione nuova della struttura dati. Questo significa che ogni struttura dati ha due forme: la vecchia forma e la nuova forma.
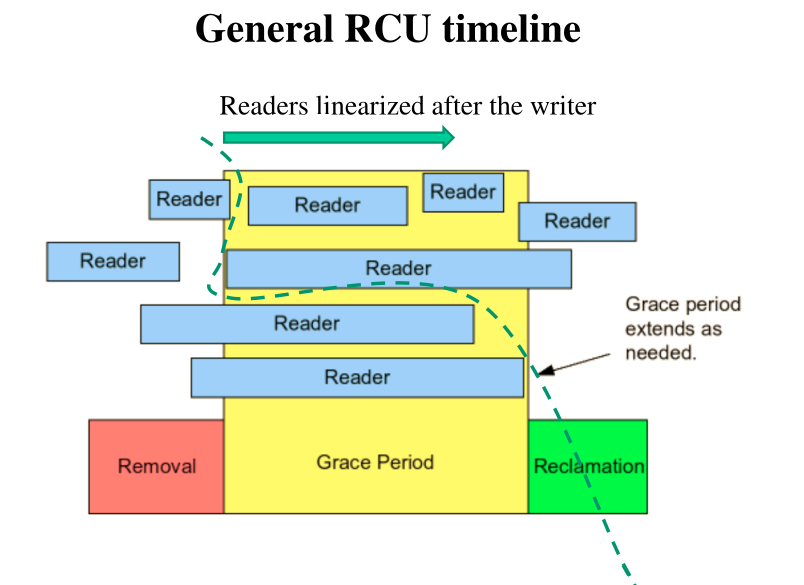
4.1 Operations
Le letture e le scritture in RCU sono gestite nel seguente modo:
Il reader:
Segnala che sta leggendo
Legge
Segnala che non legge più
Il writer:
Prende un blocco per il write
Aggiorna la struttura dati
Aspetta che gli standing readers finiscano
Rilascia i buffer utilizzati per il riutilizzo
A seconda di come implementiamo queste operazioni abbiamo diverse versioni di RCU. In particolare nel contesto del kernel linux troviamo due versioni: una implementata a livello kernel-space, e l'altra a livello user-space.
4.2 Kernel Space
Ricordiamo che se la CPU è preemptable, allora il kernel è in grado di de-schedulare un thread ad un certo punto della sua esecuzione tramite la ricezione di un interrupt. Se invece sono non-preemptable allora non posso essere interrotto da un interrupt.
Se il mio SO è di tipo non-RT (RealTime), ovvero se abbiamo una configurazione kernel di tipo non-preemptable, il reader deve disabilitare la preemption per fare una lettura, e riabilitarla appena finito.
Il writer capisce che nessun standing reader sta ancora lavorando sulla parte vecchia della struttura dati andando ad eseguire se stesso su tutte le CPUs, utilizzando funzioni come
for_each_online_cpu(cpu);
run_on(cpu);
Tramite l'utilizzo di queste funzioni il writer si può assicurare che non c'è più nessun standing reader che aveva iniziato la sua lettura prima del writer.
4.3 User Space
A livello user invece è possibile implementare RCU attraverso dell istruzioni RMW. In particolare l'idea è quella di utilizzare due contatore atomici di presenze. Ogni volta che la struttura dati viene aggiornata da un writer si crea una nuova epoca, e si azzera il vecchio contatore di presenze.
Quando il writer crea la nuova epoca, modifica anche il puntatore al contatore utilizzato dai readers, e i successivi readers che accedono alla struttura dati vanno ad incrementare il nuovo contatore. I vecchi readers, invece, una volta che escono dalla vecchia versione della struttura dati decrementano il contatore della vecchia epoca e incrementano quella della nuova.
Una volta che il contatore della vecchia epoca raggiunge lo \(0\), il writer è sicuro di poter eliminare le porzini della struttura dati che non sono più logicamente valide.
4.4 RE: RCU
Il file HARDWARE-INSIGHTS/RCU/list.h contiene la struttura dati
utilizzata, che è una linked-lista, e che varia a seconda se stiamo
utilizzando uno spin-lock oppure RCU, assieme alle operazioni che
possiamo eseguire sulla struttura dati.
Il file HARDWARE-INSIGHTS/RCU/locked-list.c contiene
l'implementazione della linked list utilizzando degli
spin-lock. Ogni operazione sulla lista viene effettuata andando
prima a prendersi il lock per poi rilasciarlo una nuova terminata
l'operazione.
Il file HARDWARE-INSIGHTS/RCU/rcu-list.c contiene
l'implementazione della linked list utilizzando RCU per ottenere la
sincronizzazione della memoria dei threads.
Il file HARDWARE-INSIGHTS/RCU/try.c contiene il codice necessario
per testare le performance andando ad eseguire varie operazioni in
modo concorrente sulla struttura dati.
Una cosa interessante è che nell'implementazione della linked list tramite RCU non andiamo sempre ad aspettare il perido di grace. Ad esempio nell'operazione che permette di aggiungere un nodo non andiamo ad aspettare che i vecchi readers escano dalla vecchia versione della struttura dati.
5 Vettorizzazione
La vettorizzazione è una forma di parallelismo presente nelle moderne architetture basata sull'esecuzione di operazione non su singole locazioni di memoria, ma su vettori di elementi.
Tramite la vettorizzazione siamo in grado di ottenere un parallelismo di tipo SIMD (Single Instruction Multiple Data). Altri tipi di processamento sono:
MIDM (Multiple Instruction Multiple Data): processing trovato nelle architetture con multi-processors/multi-core.
MISD (Multiple Instruction Single Data): raramente trovato, anche se alcuni affermano che l'esecuzione speculativa segue questo schema.
SISD (Single Instruction Single Data): banale processamento single-core senza esecuzione speculativa.
5.1 Processor Scheme
Un processore vettoriale necessita della replicazione dell'hardware per eseguire lo stage di execute sui vari elementi del vettore nello stesso ciclo di clock.
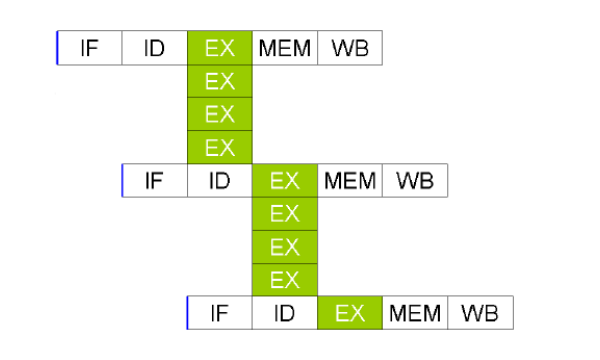
All'interno dell'ISA devono essere presenti delle istruzioni per eseguire operazioni sui vettori, e per caricare (risp. scrivere) dei vettori dalla memoria (risp. alla memoria). Le operazioni di lettura e scrittura prendono il nome di scatter/gather. Nelle regole di scatter/gather vengono specificati in quali luoghi della memoria possono essere scritti i valori da processare in modo vettoriale.
5.2 Vectorization in x86
In x86 la vettorizzazione è attualmente chiamata SSE, che sta per Streaming SIM Exstension, ed è stata introdotta nei processori Pentium III col nome di MMX.
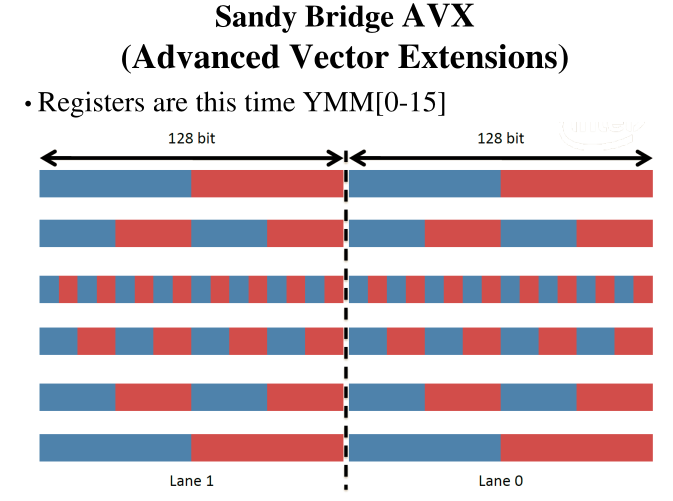
La differenza tra SSE e MMX è la quantità di dati che riesco a toccare tramite le operazioni vettorizzate, ovvero il numero di bit utilizzati per rappresentare i dati. Nella programmazione MMX i registri erano a \(64\) bit, mentre nella SSE (versione 1) avevamo \(8\) registri a \(128\) bit, e nella SSE (versione 2) ci sono \(16\) registri a \(128\) bit.
I registri a \(128\) bit possono essere visti in modi diversi. In particolare troviamo il seguente schema

Esiste poi una ulteriore estensione, chiamata Sandy Bridge, o AVX (Advanced Vector Exstensions), che permette di averere registri a 256 bit.
5.3 C Intrinsics for SEE
Per lavorare con SSE abbiamo ci vengono forniti una serie di intrinsics, tra cui
5.4 Memory Alignment
Le operazioni vettorizzate più ottimizzate impongono dei vincoli di allineamento nella memoria ai dati su cui operano. In questi casi infatti, se i dati in input non sono ben allineati, si potrebbe persino generare una exception di tipo General Protection Error per il non-allineamento dei dati in memoria.
L'allineamento tipicamente è agli \(8\) o \(16\) bytes, e può essere ottenuto in vari modi:
Per strutture statiche possiamo utilizzare il costrutto gcc
__attribute__ ((aligned (16)))Utilizzando la mmap abbiamo delle pagine automaticamente allineate ai 16-bit.
Utilizzando gcc tramite la flag
-Oper ottimizzazione il codice generato dal compilatore.
5.5 RE: SSE
Nel file HARDWARE-INSIGHTS/SSE/sse.c facciamo vedere il guadagno
di performance quando vogliamo operare su una sequenza di elementi
in modo vettoriale.
Nel file HARDWARE-INSIGHTS/SSE/sse1.c facciamo vedere un caso in
cui eseguire le operazioni vettorizzate porta ad un guadagno di
performance.
Nel file HARDWARE-INSIGHTS/SSE/array-sum-multiplication.c
mostriamo come il compilatore può scegliere di vettorizzare le
operazioni se sono attivi i giusti flag di ottimizzazione. Il
Makefile presente nella cartelle contiene i due modi per compilare:
uno senza ottimizzazioni e un altro con ottimizzazione -O3 .
<