AOS - 08 - KERNEL PROGRAMMING BASICS I
1 Lecture Info
Data:
Sito corso: link
Progresso unità: 1/6
Argomenti:
Schemi di indirizzamento
x86 memory access modes
Segmentation
Ring model
2 Processori di Sistema
Come prima cosa da fare per addentrarci nel mondo della programmazione di sistema dobbiamo capire come poter prendere le informazioni di nostro interesse dalla RAM. In particolare dobbiamo essere in grado di capire cosa possiamo fare e cosa non possiamo fare, a seconda dei livelli di privilegio.
Il concetto di livello di privilegio è fondamentale da tenere a mente. Un sistema operativo infatti può essere definito come un software che permette di discriminare tra software privilegiato e software non-privilegiato.
Collegato alla definizione di sistema operativo troviamo quella di processore di sistema. Un processore di sistema è un processore su cui ci si può montare sopra un sistema operativo. Un SO come baseline deve offrire la possibilità di discriminare rispetto al livello di privilegio del software. Questo significa che non tutti i processori sono stati processori di sistema.
Nei processori di sistema moderni gli schemi di indirizzamento sono supportati da capabilities interne dei processori. Queste capabilities sono di due tipi:
Registri della CPU,
Tabelle memorizzate nella memoria fisica e puntate da particolari registri della CPU.
Andiamo quindi a ripassare i vari possibili schemi di indirizzamento alla memoria da un punto di vista teorico, per poi vedere quali supporti ci offre l'architettura x86.
3 Schemi di Indirizzamento
3.1 Indirizzamento lineare
Nello schema di indirizzamento lineare la memoria viene vista come un singolo blocco di indirizzi contigui. Per specificare un punto nella memoria, ovvero un indirizzo, si utilizza solamente un intero, chiamato offset.
\[\text{Address} = \langle \text{offset} \rangle\]
Questo indirizzamento può essere utilizzato sia per la memoria virtuale e sia per la memoria fisica.
3.2 Segmentazione
Con questo schema di indirizzamento la memoria non è vista come un unico contenitore, ma viene vista come un insieme di zone differenti di memoria, ciascuna delle quali prende il nome di segmento. Ogni segmento a sua volta definisce uno spazio di indirizzamento lineare.
Per esprimere un indirizzo in memoria utilizzando questo schema necessitiamo dunque di due informazioni:
L'identificatore del segmento
L'offset da applicare a quel segmento.
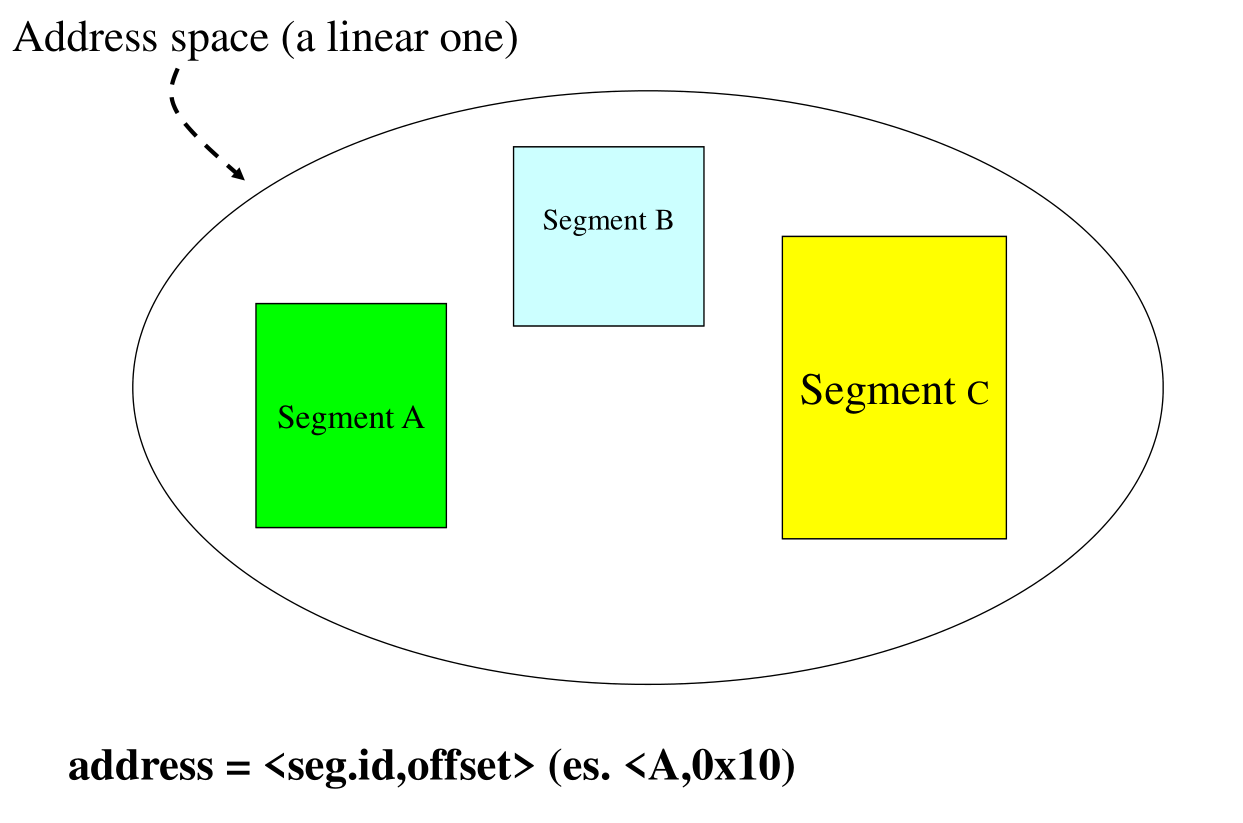
3.3 Segmentazione in uno spazio lineare
Nei moderni sistemi si utilizza un mix tra segmentazione e spazio di memoria lineare. Lo spazio di memoria lineare infatti è necessario per poter utilizzare la paginazione, una tecnica di gestione della memoria fisica che viene utilizzata nei moderni sistemi operativi per motivi di performance e di cui parleremo successivamente.
Per poter utilizzare questo schema di indirizzamento ibrido necessitiamo un modo che ci permette di passare da uno spazio segmentato ad uno lineare. Dall'indirizzo segmentato bisogna infatti passare in qualche modo ad un indirizzo lineare.
Un possibile approccio per risolvere questo problema è il seguente: si considerano i vari segmenti come collocati in punti diversi di un unico contenitore di memoria. Dato un indirizzo segmentato \(\langle \text{seg_id}, \text{offset} \rangle\) il relativo offset globale è dato da
\[\text{global_offset} = \text{base } + \text { offset}\]
dove \(\text{base}\) indica l'indirizzo di partenza, ovvero la base, del segmento con id \(\text{seg_id}\). Graficamente troviamo,
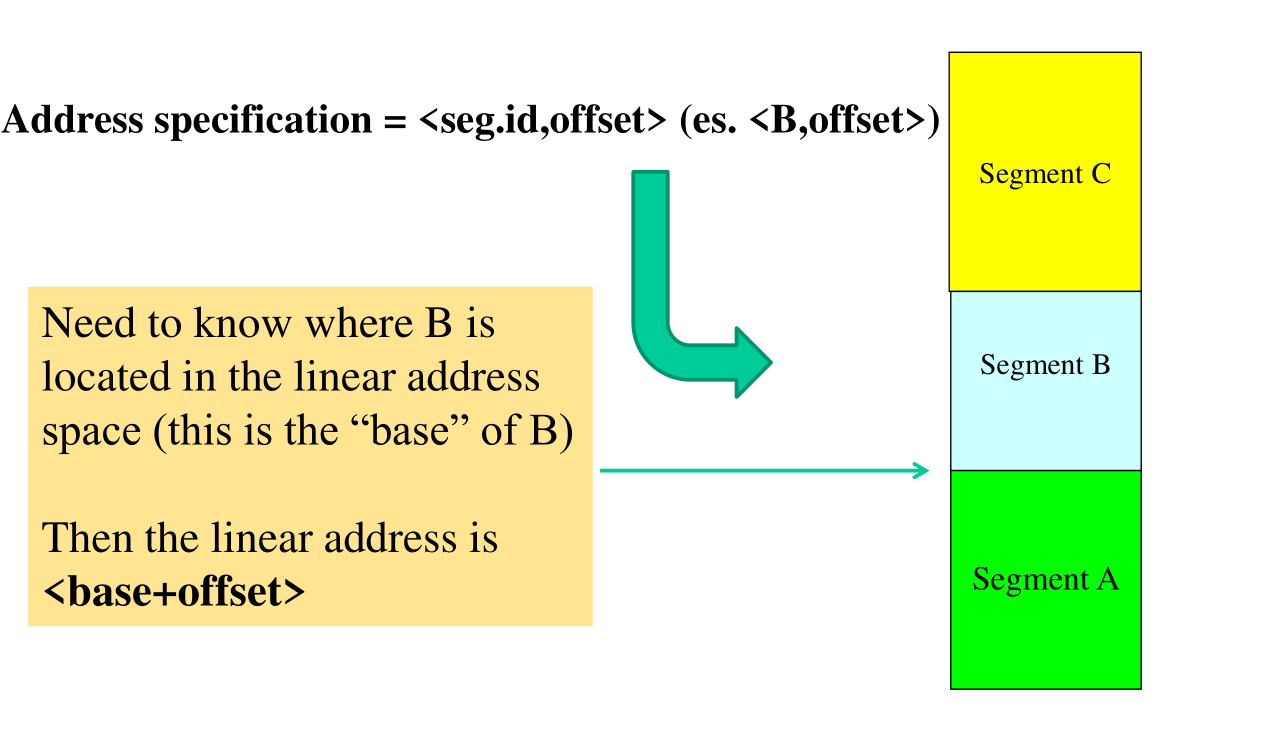
Anche questo schema può essere utilizzato sia per memoria virtuale che per memoria fisica.
3.4 Indirizzamento nei sistemi moderni
Nei sistemi operativi moderni la memoria è quasi sempre gestita
tramite uno schema di segmentazione. Nella nostra esperienza di
programmatori però anche utilizzando tecnologie relativamente basse
come il linguaggio C non abbiamo mai espresso a quale segmento
facevamo riferimento nelle nostre istruzioni di interazione con la
memoria. In altre parole abbiamo sempre visto gli indirizzi come
dei singoli numeri, ovvero come dei semplici offset a partire
dall'indirizzo 0x0 . Qual è la motivazione di questa mancanza?
La spiegazione di questa mancanza può spiegata osservando che i segmenti sono sempre stati gestisti alle nostre spalle, dal processore e dai supporti hardware utilizzati dal processore. In altre parole, anche se noi non non esplicitavamo il particolare segmento a cui facevamo riferimento, il compilatore, il firmware e l'hardware andavano ad aggiungere queste informazioni mancanti in modo da poterle utilizzare correttamente durante la risoluzione dell'indirizzo.
I moderni processori supportano in modo efficiente la segmentazione combinata con un indirizzamento lineare e un meccanismo di memoria virtuale. Quando cerchiamo di accedere ad una informazione in memoria, i seguenti steps vengono eseguiti
segmented addr -> linear addr -> paged addr -> physical addr
3.5 x86 example
Il seguente codice, scritto in ASM (AT&T syntax) fa utilizzare in modo implicito al processore tre segmenti diversi.
mov (%rax), %rbx push %rbx
I segmenti utilizzati sono i seguenti:
Il primo è il segmento che contiene il dato da caricare nel registro
RBX. L'offset che andiamo ad utilizzare all'interno di quel segmento è dato dal valore del registroRAX.Il secondo è il segmento che contiene la stack utilizzata per eseguire l'istruzione
push. L'offset che andiamo ad utilizzare questa volta è dato dal valore del registroRSP, che contiene lo stack pointer.Il terzo è il segmento che contiene le istruzioni da eseguire. L'offset che andiamo ad utilizzare questa volta è dato dal valore del registro
RIP, che contiene l'instruction pointer.
4 X86 Memory Access Modes
L'architettura x86 può lavorare in tre modi diversi per gestire l'accesso alla memoria, questi sono:
Real mode
Protected mode
Long mode
Andiamo quindi a descrivere le varie caratteristiche di ciascuna modalità di accesso alla memoria.
4.1 Real mode (286)
La real mode permette la retro-compatibilità rispetto a processori
vecchi come l' Intel 286 , ma permette comunque un accesso alla
memoria segmentata.
In questo schema un registro di segmento a 16-bit contiene il segment ID che si sta utilizzando per accedere alla memoria, mentre l'offset è specificato da 16-bit memorizzati in un general purpose register. Gli indirizzi, solamente fisici, vengono calcolati come segue
\[\text{PhysicalAddress} = \text{Segment_ID} \cdot 16 + \text{Offset}\]
Questo metodo di indirizzamento permette di indirizzare intorno a 1MB di memoria in quanto
\[2^{16} \cdot 2^4 + 2^{16} = 1.114112 \text{MB} \approx 1 \text{ MB}\]
La real mode rappresenta quindi il minimo supporto possibile per offrire la segmentazione. In questa modalità infatti non sono presenti informazioni di protezione sui vari segmenti, e quindi non è uno schema di indirizzamento adatto per i moderni sistemi operativi. La real mode, e in particolare alcune sue modifiche, sono utilizzate in modo temporeaneo durante il processo di boot.
4.2 Protected mode (80386)
In questa modalità il segment register utilizza solo 13-bit dei 16 disponibili per memorizzare il dato sull'ID del segmento. I restanti 3 bit vengono invece utilizzati per mantenere informazioni di protezione sul segmento. Utilizzando la protected mode siamo quindi in grado di discriminare le capabilities di accesso ad un dato segmento. In altre parole questi 3 bit permettono di supportare il software di un sistema operativo.
Per specificare gli offset invece si utilizzano 32-bit all'interno di un general purpose register.
La regola per calcolare l'indirizzo lineare partendo dall'indirizzo segmentato è la seguente
\[\text{Address} = \text{TABLE[segment].base} + \text{offset}\]
Dove \(\text{TABLE}\) è una tabella memorizzata in memoria che contiene, per ogni segmento, le informazioni relative al segmento. Tra queste informazioni sono di particolare interesse quelle relative all'indirizzo base in cui il segmento si trova all'interno dello spazio lineare globale.
Osservazione: Per aumentare le performance del sistema la tabella che contiene le informazioni relative ai segimenti può essere memorizzata in supporti di caching vicini al processore.
La protected mode ci permette di indirizzare 4GB di memoria lineare, sia fisica che logica. Tramite un supporto chiamato Physical Address Exstension è poi possibile aumentare lo spazio fisico di indirizzamento, passando da 4GB a 64GB.
4.3 Long mode (x86-64)
In questa modalità, simile alla protected mode, abbiamo un segmento di registro a 16 bit, di cui 13-bit vengono usati per specificare il segment_ID, e gli ultimi 3 bit vengono utilizzati per memorizzare informazioni di protezione sui segmenti.
A differenza dalla protected mdoe però, gli offset sono memorizzati in registri general-purpose a 64 bit. Notiamo che anche se i registri sono a 64 bit, gli offset possono solo variare solamente in uno spazio di 48-bit, che prende il nome di spazio di /indirizzamento globale in forma canonica.
La regola per calcolare l'indirizzo lineare partendo dall'indirizzo segmentato è la seguente, ed è la stessa del protected mode
\[\text{Address} = \text{TABLE[segment].base} + \text{offset}\]
Questo schema di indirizzamente permette di avere uno spazio di indirizzamento lineare di 256TB. In un futuro molto remoto poi, quando i 48 bit di offset non basteranno più, i vendor degli hardware disabiliteranno la forma canonica e sarà possibile utilizzare tutti e 64 i bit per esprimere l'offset.
5 x86 Segment Tables
In x86 esistono due tabelle che mantengono le informazioni sui segmenti. Queste sono:
GDT, che sta per Global Descriptor Table.
LDT, che sta per Local Descriptor Table.
La GDT e la LDT sono memorizzate in memoria fisica e sono direttamente accessibili da dei puntatori mantenuti in particolari registri della CPU.
Nei moderni sistemi software poi la LDT non viene più utilizzata, e quindi tipicamente tutti gli accessi alla memoria utilizzano solamente la GDT. Questo significa che durante il processo di start-up tutti i processi scrivono nella tabella GDT le appropriate informazioni.
La GDT ci permette quindi di sapere la locazione nello spazio globale di qualsiasi segmento dell'address space di un particolare processo. Una tipica entry della GDT è formatta nel seguente modo
Dove le FLAGS contengono delle informazioni di protezione rispetto al segmento.
6 Segmentation vs Paging
Tramite le modalità di accesso alla memoria protected-mode e long-mode, siamo in grado di utilizzare dei bit al fine di memorizzare e utilizzare delle informazioni di protezione a livello del segmento.
Nei moderni sistemi però non c'è solo la segmentazione, ma c'è anche la paginazione. Anche se la paginazione nasce come metodo per migliorare l'utilizzo della memoria fisica, all'interno delle pagine sono comunque presenti dei bit di protezione.
Nasce quindi il seguente dubbio: si sta forse duplicando questi bit di protezione, aggiungendo informazioni ridondanti?
La risposta è in parte che sì, si sta aggiungendo informazioni in parte ridondanti di protezione. Detto questo, bisogna tenere a mente il fatto che la segmentazione offre una protezione a grana grossa, ovvero ci permette di proteggere grandi sezioni di codice e dati (i segmenti possono essere molto grandi), mentre la paginazione offre una protezione a grana fine, in quanto le pagine sono tipicamente di dimensione molto limitata.
Notiamo poi che la segmentazione non è resa inutile e superflua dall'introduzione della paginazione.
In particolare la segmentazione è diventata fondamentale per i sistemi multi-core e multi-threading, in quanto permette di implementare particolari regole di acesso alla memoria che non sarebbero implementabili se non attraverso la segmentazione.
Anche nella programmazione multi-threading la segmentazione gioca un ruolo fondamentale.
7 The x86-64 revision
Con l'introduzione di x86-64, è stata cambiata anche la modalità in cui il firmware gestisce i vari segment IDs (anche chiamati selettori).
In particolare si era notato che molti programmatori scrivevano il
software utilizzando come base dei segmenti la base 0x0 . Così
facendo la potenzialità dell'hardware di tradurre in modo dinamico
la base dei segmenti veniva utilizzata poco.
Nel x86-64 si è quindi pensato di forzare la base di alcuni segmenti
al valore 0x0 . Per questi segmenti quindi le uniche informazioni di
interesse salvate nella tabella GDT sono relative ai bit di
protezione.
Detto questo, non tutti i segmenti hanno la base fissata a 0x0 . Ci
sono infatti segmenti che possono avere una base arbitraria, e per
cui la regola di traduzione utilizzata il procedimento descritto in
precedenza.
8 Ring Model
Il ring model è basato sulla presenza di bit di protezione su ogni segmento diverso e viene utilizzato come strumento di protezione e di supporto al flusso di esecuzioni dei thread nel seguente modo:
Ad ogni segmento è associato un livello di protezione differente, che prende il nome di protection level (o privilege level). Tipicamente vengono utilizzati 2 dei 3-bit disponibili su ogni segmento, permettendoci di avere quattro livelli di protezione diversi. Più alto è il livello di protezione e meno privilegio ho sul sistema.
Una routine che viene eseguita all'interno di un segmento che ha un livello di livello \(h\) può invocare qualsiasi altra routine che si trova in un segmento con livello di protezione \(h\). In questo caso infatti si parla di intra-segment jumps o cross-segment jumps tra segmenti con lo stesso livello di protezione.
Per poter invocare una routine con un livello di protezione diverso dal livello di protezione della routine in esecuzione necessitiamo di eseguire un cross-segment jump.
I cross-segment jump permettono sempre di saltare da un livello di protezione più basso ad uno più alto. Se mi trovo a livello di protezione \(h\) il sistema mi permette sempre di saltare ad un livello di protezione \(h + i\).
Se voglio invece effettuare un cross-segment jump ad un segmento con un livello di protezione più basso, devo utilizzare un GATE. I GATEs sono quindi delle porte, che permettono l'accesso al segmento anche a routine che hanno un livello di protezione più alto (e quindi peggiore).
Ogni segmento con livello di protezione \(h\) è associato ad una serie di access points, che prendono il nome di GATEs. Ciascun gate è identificato da una coppia \(\langle \text{seg_id}, \text{offset} \rangle\). Ogni GATE ha un livello massimo \(\max = h + j\) che specifica il livello di protezione massimo dal quale sono in grado di accedere al GATE.
In particolare, se \(\text{level}(S) = h\) e \(\max(GATES(S)) = h+i\), allora si può accedere al segmento \(S\) da routine con, al massimo, un livello di protezione di \(h+i\).
Notiamo che lo stesso meccanismo di protezione utilizzato per controllare il flusso di esecuzione del codice viene anche utilizzato per controllare l'accesso a segmenti contenenti dei dati. In particolare nella CPU sono presenti dei bit, chiamati CPL (Current Privilege Level), che specificano il livello corrente di privilegio. Ogni volta che il flusso di esecuzione passa da un segmento ad un'altro, a seconda del CPL vengono caricati (o meno) i bit di sicurezza del nuovo segmento all'interno della CPU, e il vecchio CPL viene sostituito con il nuovo livello di privilegio. Quando si accede ad un dato presente in un segmento quindi, per verificare se questo accesso può acceduto o meno, si confronta il CPL con i bit di privilegio associati al segmento dati a cui stiamo cercando di accedere.
8.1 Types of GATEs
Come abbiamo già descritto, I GATEs sono dei punti di accesso all'interno di un segmento che permettono di abbassare il livello di privilegio. In generale ci sono due famiglie di GATES, che sono:
Interrupt handlers: Un interrupt handler è un blocco di codice che deve essere eseguito quando un dispositivo esterno lo richiede. La variazione del flusso di esecuzione per l'esecuzione di un interrupt handler non è richiesta dal codice ma è richiesta dal dispositivo (invocazione asincrona).
Software traps: Le software traps portano ad una variazione del flusso di esecuzione. A differenza degli interrupt handler, le software traps vengono invocate dal software stesso.
Quando facciamo una divisione per \(0\) ad esempio, dato che il software non sa cosa fare, può invocare una software trap per cambiare il flusso di esecuzione del programma.
8.2 Ring Model in x86
Su processori x86 abbiamo quattro livelli di protezione. Il livello \(0\) è quello con più privilegi sul sistema, mentre il livello \(3\) è quello con meno privilegi.
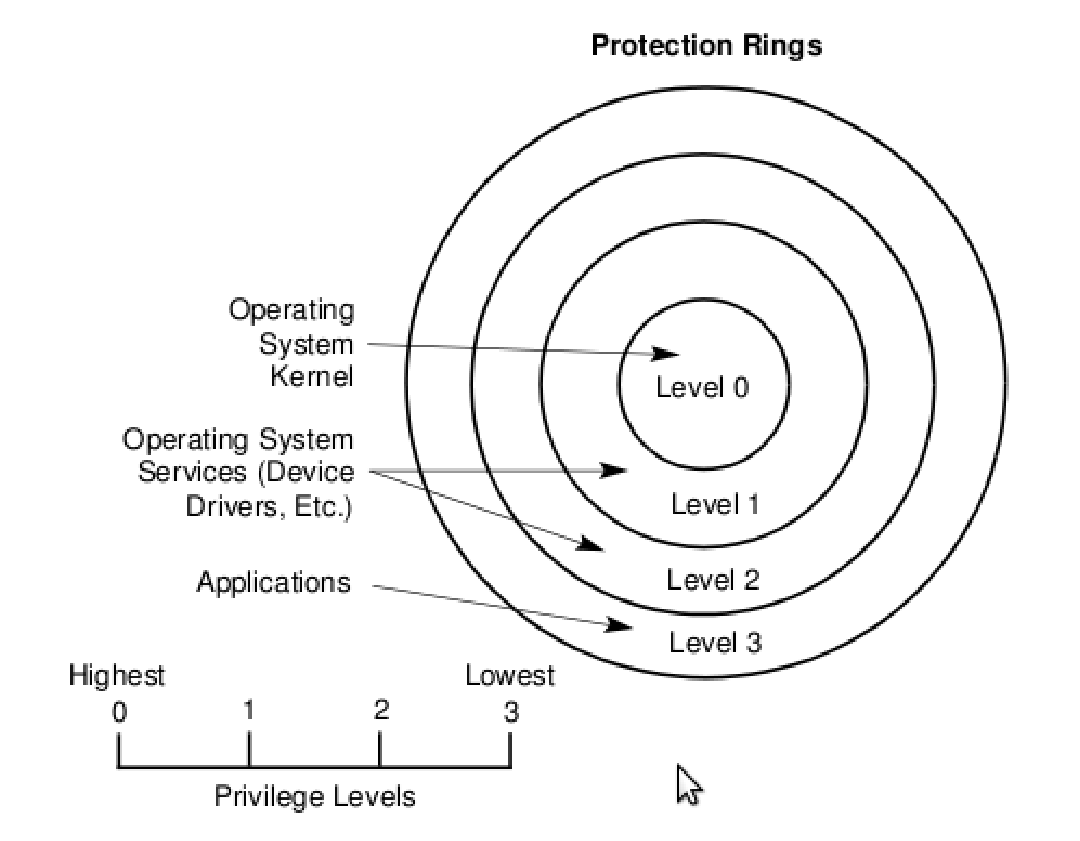
Da \(0\) posso passare a \(1\), \(2\) o \(3\) senza controlli, in quanto mi sto de-privilegiando. Da \(1\) posso passare a \(2\) o \(3\) tranquillamente, oppure a \(0\) tramite un GATE.
Per anni i livelli intermedi del ring model sono stati poco utilizzati: era prassi far girare il kernel del sistema operativo al livello \(0\), e le applicazioni degli utenti a livello \(3\). Con la diffusione della virtualizzazione poi anche i livelli intermedi hanno avuto il loro utilizzo. Il kernel di una virtual machine infatti non gira a ring \(0\), in quanto se fosse così la virtual machine potrebbe prendere il sopravvento su tutto, ma gira nei livelli intermedi \(1\) e \(2\).