AOS - 14 - KERNEL MEMORY-MANAGEMENT I
Lecture Info
Data:
Sito corso: link
Progresso unità: 1/5
Argomenti:
Startup Tasks
BIOS e UEFI
Kernel start-up code
RAM organization
Kernel data structures for steady state memory
Introduzione: Iniziamo adesso a trattare il modo in cui il kernel gestisce la memoria. In particolare tratteremo il memory managament in due diverse fasi: inizialmente durante la fase di start-up, in cui il kernel inizializza la sua immagine e le strutture dati utilizzate, e poi a steady-state, quando è pronto per far lavorare i processi applicativi.
1 Startup Tasks
Per trattare il processo di start-up necessitiamo di conoscere i seguenti termini:
Firmware: Il firmware è un programma codificato all'interno di un device con Read Only Memory (ROM). Durante la fase di start-up il firmware è la prima cosa che viene eseguita.
Bootsector: Settore predeterminato di un dispositivo di memorizzazione (come un disco), che mantiene del codice eseguibile necessario per lo start-up del sistema.
Bootloader: Il codice che viene eseguito per inizializzare il processo di start-up e dare il controllo all sistema operativo che vogliamo far partire. Si può trovare in parte nel bootsector e in parte in altri settori del disco.
Il bootloader viene utilizzato per parametrizzare l'esecuzione del sistema operativo e far si che il sistema operativo veda il giusto stato dell'hardware. Così facendo siamo in grado di decidere in modo dettagliato come il nostro SO si deve comportare a seconda dei parametri che gli passiamo tramite il bootloader.
I task che vengono eseguiti durante la fase di start-up sono
Il firmware viene eseguito appena accendiamo il sistema. Il firmware legge il bootsector e lancia il bootloader.
Il contenuto del bootsector viene eseguito, e questo potrebbe portare ad eseguire il contenuto di altre porzioni in cui il bootloader è situato.
Il bootloader carica il kernel del sistema operativo target e gli passa il controllo.
Il kernel esegue le sue operazioni di startup, che consistono di cambiare l'architettura del sistema, di costruire o modificare strutture dati e di attivate determinati processi. Durante la fase di start-up, per emulare uno scenario steady state, almeno un processo, chiamato
IDLE PROCESS, viene eseguito a partire dal boot thread.
Osservazione: L'utilizzo dell' IDLE PROCESS per far si che ci sia
sempre almeno un processo attivo permette alla logica del kernel di
non doversi preoccupare degli stati in cui nessun processo è attivo,
permettendo dunque un risparmio notevole di tutto il codice che
avrebbe dovuto gestire il caso in cui nessun processo è in
esecuzione. Dato che il codice deve essere caricato in memoria,
questo permette di risparmiare anche in termini di utilizzo di
memoria.
Tutti gli step menzionati portano a vari cambiamenti dell'immagine dei dati e del codice presente in memoria. Questi cambiamenti sono necessari per settare l'immagine finale del kernel, e possono avvenire su tre livelli diversi:
Architecture setup
Kernel initialization
Kernel common operation
In tutti questi tre step quindi necessitiamo di avere dei meccanismi per gestire la memoria. L'immagine del kernel che viene caricata durante la fase di start-up è dunque molto diversa dall'immagine del kernel quando si arriva alla fase steady-state.
2 BIOS e UEFI
2.1 BIOS e MBR in x86
Il firmware tradizionale utilizzato in x86 è chiamato BIOS (Basic
I/O System).
Tramite l'utilizzo di determinate keys ( F1 ) è possibile accedere ad
una modalità interattiva in cui l'utente è in grado di
parametrizzare l'esecuzione del firmware. I parametri sono
tipicamente memorizzati tramite della memoria CMOS, mentre il
codice vero e proprio è scritto in una memoria ROM. Tra le altre
cose che possiamo specificare al BIOS, possiamo anche scegliere
l'ordine in cui cercare il boot sector tra diversi dispositivi.
Il primo settore di un dispositivo utilizzato per fare il boot
contiene il "master boot record", abbreviato MBR . Il MBR contiene
sia un pezzo di codice eseguibile che una tabella a quattro
entrate, ciascuna delle quali identifica una particolare partizione
del dispositivo tramite la sua posizione all'interno del
dispositivo.
Il primo settore in ogni partizione può operare come partition boot
sector ( BS ). Se la partizione è estesa ( extended partition ), allora
può contenere addizionalmente altre 4 sub-partitions. Ogni
sub-partition può avere il proprio boot sector.
La struttura del MBR è la seguente
Utilizzando il BIOS la massima capienza di disco gestibile è di 2TB.
2.2 UEFI
UEFI è stato introdotto per avere una maggiore flessibilità
rispetto alle limitazioni del BIOS. UEFI offre vari vantaggi, tra
cui:
Possibilità (teorica), di gestire disk up to 9 zettabytes.
Interfaccia visuale molto più avanzata.
Permette di eseguibile del codice (EFI executables). Ovvero UEFI è un interprete di programma (virtual machine), per determinati programmi. UEFI offre quindi un ISA parallelo a quello del processore che permette di avere una maggiore flessibilità durante la fase di start-up.
Permette una interfaccia al sistema operativo per poter essere configurato. Questo significa che UEFI è visibile al sistema operativo (cosa non vera per BIOS).
Le informazioni sulle partizioni di un hard drive utilizzando UEFI
sono mantenuta in una tabella a taglia variabile chiamata GPT (GUID
Partition Table), dove GUID per Globally Unique
Identifier. Teoricamente può contenere un numero illimitato di
partizioni.
Dato che UEFI è retrocompatibile con MBR, la tabella GPT è presente nel primo settore del disco. La GPT però, a differenza della tabella utilizzata con il BIOS, è replicata, ed è presente anche nell'ultimo settore del disco.
3 Kernel Start-Up Process
Il bootloader/EFI-loader, tipicamente GRUB, carica in memoria
l'immagine iniziale del kernel del sistema operativo che vogliamo
lanciare. Prima di passare il controllo al sistema operativo viene
eseguito del "machine setup code" che permette di far vedere uno
specifico stato dell'hardware al kernel. Una volta terminata questa
fase passiamo il controllo al kernel. L'immagine iniziale del kernel
inizia la sua esecuzione nella funzione start_kernel() presente nel
file init/main.c
L'immagine del kernel durante il processo di start-up è molto diversa dall'immagine del kernel a steady state. Questo deriva da una serie di fattori, tra cui il fatto che il kernel, per operare steady state necessita di molte strutture dati che non possono essere scritte direttamente in fase di compilazione, in quanto altrimenti l'immagine iniziale del kernel sarebbe troppo pesante e quindi il processo di start-up troppo lento.
3.1 Multi-Core Startup Process
In caso di macchine multi-core, in tecnologia convenzionale la
funzione start_kernel() viene eseguita da un solo CPU-core (il
master). Tutti gli altri cores (slaves) si mettono ad aspettare
tramite dei meccanismi di spin-locking che il master abbia finito.
La funzione interna del kernel smp_processor_id() permette di
identificare l'identificativo del core in esecuzione, e si basa
sull'istruzione macchine CPUID . Notiamo che a questo livello non è
ancora implementata la per-CPU memory e quindi, anche se
l'esecuzione di CPUID porta ad uno squash della pipeline, non
abbiamo altri modi per identificare i processori.
L'istruzione CPUID non ritorna solo l'identificativo della cpu, ma
torna anche varie informazioni hardware sul processore. A seconda
del valore del registro EAX prima dell'esecuzione la CPUID può
avere dei side effect sui registri EAX, EBX, ECX e EDX.
Osservazione: Il problema di gestire uno start-up in modo parallelo è un problema difficile di ricerca, in quanto molte delle facility che ci permettono di gestire la concorrenza non sono ancora presenti durante la fase di start-up.
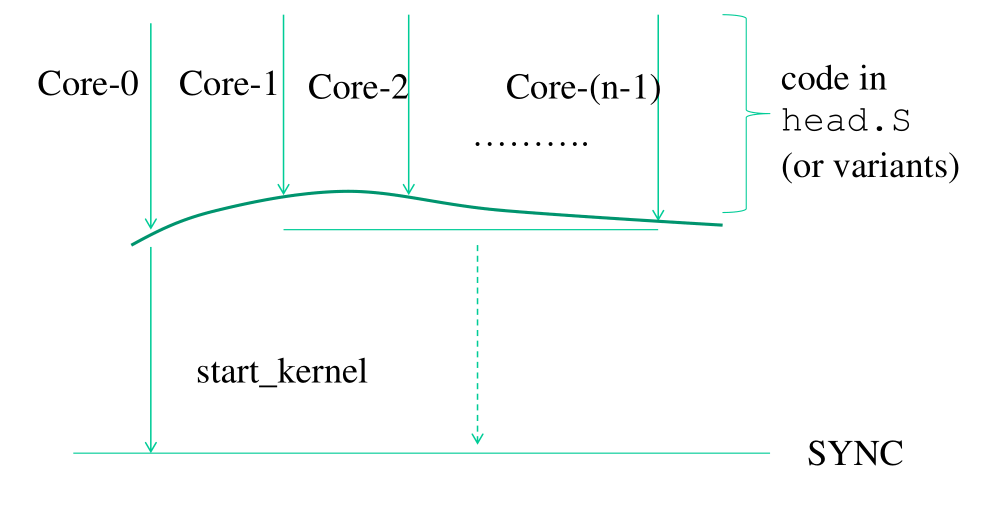
3.2 head.S
Ogni CPU-core della macchina non prende il codice nella funzione
start_kernel() , ma prende il codice in un blocco di codice machine
dependent presente in head.S (o varianti). In questo
machine-dependent code il cpu-core prende varie informazioni
sull'hardware, decide se è master o slave, e in caso è master
comincia ad eseguire la funzione start_kernel() , altrimenti si
mette in attesa.
Tra le altre cose che vengono eseguite in head.S c'è anche il seguente blocco di codice, che viene eseguito da tutti i CPU-core e che si occupa di attivare la paginazione. Dopo l'esecuzione di questo blocco di codice ogni indirizzo che viene generato dalla CPU è un indirizzo lineare logico, e quindi necessita dell'utilizzo della page table per ricavare il relativo indirizzo fisico.
movl $swapper_pg_dir - __PAGE_OFFSET, %eax movl %eax, %cr // set the page table pointer movl %cr0, %eax orl $x80000000, %eax movl %eax, %cro // set paging (PG) bit
Notiamo che nei moderni sistemi __PAGE_OFFSET è una costante,
mentre $swapper_pg_dir è l'indirizzo logico della tabella delle
pagine. L'indirizzo fisico viene quindi computato come segue
indirizzo_fisico = indirizzo_logico - offset
Notiamo quindi che questo processo necessita che le seguenti ipotesi siano verificate durante il processo di compilazione:
L'indirizzo logico della page table è dato da $swapper_pg_dir.
Il contenuto della tabella posizionata in $swapper_pg_dir è tale che tutti gli indirizzi logici che vado poi a esprimere vengono tradotti correttamente per accedere alla memoria fisica.
3.3 __init Functions
La signature della funzione start_kernel è fatta come segue
__init start_kernel(void)
La specifica __init viene utilizzata dal compilatore del kernel, e
serve per indicare che la relativa funzione non ha ragione di
esistere in memoria nelle fasi successive allo start-up. Le
funzioni marcate con __init vengono quindi solamente utilizzate
durante il kernel boot, e le pagine logiche che contengono tale
funzioni vengono recuperate una volta eseguito lo start-up.
Le ragioni per questo riciclo sono varie sono varie: anche se inizialmente veniva fatto per ridurre lo spazio utilizzato in RAM, attualmente i kernel stanno diventando sempre più complessi, e quindi anche le funzioni di start_up diventano sempre più complesse. Risulta quindi sempre utile avere la possibilità di eliminare della logica del kernel, se questa non viene utilizzata al di fuori della fase di start-up.
Per fare questo riciclo necessitiamo che durante la compilazione e
il linking del kernel, le pagine logiche che contengono queste
funzioni __init siano marcate con dei metadati in modo da poterle
riciclare una volta terminata lo face di start-up.
Le pagine logiche in cui si inseriscono i dati e la logica
necessari per lo start-up identificano un sottosistema di gestione
della memoria che prende il nome di bootmem e che viene utilizzato
per gestire la memoria quando il kernel non ha ancora raggiunto la
fase steady-state.
3.4 Botmem
Il sistema bootmem ci permette di gestire la memoria durante la
fase di start-up.
La bootmem in particolare contiene delle bitmaps che riportano
varie informazioni sulle pagine logiche generate durante il
processo di compilazione. Queste informazioni sono varie. Tra
queste troviamo anche se la pagina è stata utilizzata, se è
riutilizzaible, se è libera oppure no.
Queste bitmaps utilizzate dal sistema bootmem vengono scritte a tempo di compilazione, e permettono di capire qual'è la struttura della memoria nelle prime fasi di start-up. Utilizzando la bootmem il kernel può richiedere zone di memoria non utilizzate per cominciare a lavorare ed espandersi con lo scopo finale di raggiungere lo steady-state.
Sui moderni sistemi linux il sottosistema bootmem ha un nome diverso (memblock), ma fa essenzialmente la stessa cosa.
3.5 Memblock
Nelle più recenti versioni del kernel linux, il sottosistema
bootmem ha cambiato nome ed è diventato memblock .
Memblock vede la memoria non più come un unico blocco, ma è in
grado di gestire architettura NUMA . Lo start-up di un sistema
utilizzando memblock quindi ci permette di vedere lo stato delle
varie pagine fisiche all'interno dei vari blocchi numa.
L'API tra i due sistemi è cambiata leggermente, ma essenzialmente i sistemi ci permettono di fare le stess cose.
3.6 Addr Resolution
Durante la fase di start-up il kernel utilizza l'astrazione dei pointers. Gli indirizzi generati dalla CPU sono quindi indirizzi logici, e non fisici. Per ottenere il relativo indirizzo fisico deve quindi essere presente un meccanismo di traduzione, rappresentato tipicamente da una page table.
L'immagine iniziale del kernel necessita quindi di una page table che mappa tutte le pagine logiche presenti gestite dal sottosistema bootmem in pagine fisiche. Così facendo il kernel può chiedere al sottosistema bootmem (o memblock) la memoria, e questa viene tradotta utilizzando la page table.
4 Modern RAM Organization
La memoria moderna non è una flat-latency memory access, ovvero non
garantisce la stessa latenza di accesso a tutti i core presenti
nella macchina. Tipicamente infatti la memoria a blocchi su un
chipset NUMA (Non Uniform Memory Access).
Ogni CPU-core ha quindi alcuni banchi di RAM che sono vicini e altri che sono lontani. Ogni banco di memoria è associato ad un NUMA-node.
I moderni sistemi operativi sono progettati per gestire le macchine NUMA.
4.1 numactl
Comando utilizzato per vedere varie informazioni riguardo al sistema NUMA. In particolare ci permette di vedere i nodi numa per ogni CPU-core e le distanze tra i vari nodi numa.
Tramite questo comando siamo in grado di configurare la macchina per gestire il sistema NUMA nel miglior modo possibile.
5 Structure for Steady-State Memory Management
Una volta che il kernel si trova in steady state, per gestire la memoria utilizza generalmente almeno tre strutture dati, che sono
Kernel Page Table: page table "ancestrale" che ci da il mapping nella memoria fisica di tutte le pagine del kernel. Questa pagina è vista da tutti i CPU-core e viene utilizzata come modello quando dobbiamo creare delle page table per processo. Tra un processo e un'altro infatti cambia solo la parte user, e non la parte kernel. La Kernel Page Table viene quindi condivisa con le page table dei vari processori. Questa necessità di condivisione implica che le page table non sono array sequenziali ma strutture dati complesse con puntatori.
Core map: La core map contiene informazioni di gestione per ciascun frame della memoria fisica. La core map in particolare ci dice se un frame è libero oppure no e permette di allocare/deallocare memoria a granularità fissa (1 frame).
Free list: La free list è una struttura dati che ci permette di allocare e deallocare la memoria a livello kernel. La free list è quindi la struttura dati che espone lo stato della core map ma che offre delle sue facilty per cercare di ottimizzare le operazioni di allocazione e deallocazione. Tramite la free list il kernel è in grado di allocare memoria ad una granularità arbitraria.
Durante lo start-up del sistema queste strutture dati non esistono e
devono essere costruire e finalizzate per arrivaro allo steady
state. Notiamo infatti che una struttura dati come la core map non
può essere presente nell'immagine del kernel create durante il
compile time, in quanto la quantità di memoria fisica accessibile, e
quindi la dimensione della core-map, è un parametro che può
modificare l'utente prima della fase di start-up. Il kernel deve
quindi essere in grado di costruire in modo dinamico questa e le
altre strutture dati.
La kernel page table è la prima struttura dati che viene modificata per arrivare alla sua versione da steady state. Sia in start-up che in steady state la kernel page table permette l'utilizzo di indirizzi logici da parte dei CPU-cores. Durante lo start-up però la page table può raggiungere una porzione limitata della memoria, e viene quindi modificata durante il processo di start-up per essere in grado di raggiungere sia in lettura che in scrittura la massima memoria disponibile dall'hardware, o eventualmente quella scelta dall'utente.
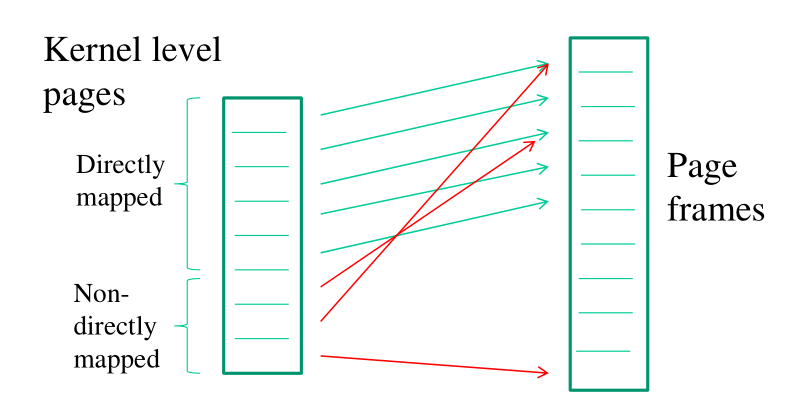
6 Directly Mapped Memory Pages
Una pagina logica del kernel è detta directly mapped se può essere
mappata nella memoria fisica (frame) tramite l'applicazione di una
funzione deterministica che mappa gli indirizzi virtuali in
indirizzi fisici.
Formalmente, una pagina è directly mapped se, rappresentato con \(\text{VA}\) un indirizzo logico all'interno della pagina, si ha che il relativo indirizzo fisico \(\text{PA}\) è dato da
\[\text{PA} = \psi(\text{VA})\]
dove $è una funzione deterministica, che tipicamente è implementata tramite dei semplici shift (sottrazioni) dal valore di \(\text{VA}\).
Notiamo che avere questo tipo di mapping è molto utile al kernel, in quanto molto spesso non basta sapere l'indirizzo logico di un dato, ma si è anche interessati al suo indirizzo fisico. Un esempio di questo caso è il codice visto in head.S che veniva eseguito da tutti i CPU-core per settare la paginazione.
In ogni caso, non tutte le pagine del kernel vengono mappate in modo diretto, in quanto altrimenti non sarei in grado di utilizzare due frame non contigui per mappare due pagine logiche continue, e il mio spazio di indirizzamento virtuale sarebbe limitato dallo spazio di indirizzamento fisico.
Dobbiamo quindi distinguere le varie pagine logiche, a seconda se sono directly mapped o no.
Osservazione: Su IA32 di x86, il valore di __PAGE_OFFSET è pari a
3GB, e dunque qualsiasi indirizzo logico del kernel compare nella
memoria fisica come shiftato di 3GB indietro.