AOS - 16 - KERNEL MEMORY-MANAGEMENT III
Lecture Info
Data:
Sito corso: link
Progresso unità: 3/5
Argomenti:
PAE
x86-64 architecture
page table auditor
L1TF
Core map
1 Physical Address Extension (PAE)
Notiamo che in i386 non possiamo indirizzare oltre ai 4GB di memoria. Inoltre in x86 protected mode gli indirizzi logici e gli indirizzi fisici hanno esattamente la stessa taglia di 32 bit.
Il primo passo atto ad espandere la capacità di gestione della memoria nelle architetture hardware x86 lo si è fatto nei confronti della sola memoria fisica tramite la Physical Addess Extension (PAE). Questo sviluppo è stato introdotto nelle architetture perché, per molte applicazioni, avere solamente 4GB di memoria logica andava bene, ma essere limitati anche nella memoria fisica era un problema. Un esempio del genere è il caso di un servizio erogato da un server multi-processo.
Con la PAE si è in grado di indirizzare fino a 36 bit di indirizzi fisici. Lo spazio di indirizzamento fisico aumenta quindi da 4GB a 64GB di memoria. Per ottenere questo aumento è stata modificata l'organizzazione delle page tables.
In particolare le due page tables, al posto di avere 1024 entries,
sono state riorganizzate per avere la metà delle entry, ciascuna
però a taglia doppia rispetto a prima (64-bit piuttosto che
32). Utilizzando solamente le vecchie due page tables, riusciamo
quindi ad indirizzare solo 1/4 del vecchio numero di pagine. Per
poter indirizzare lo stesso numero di pagine che venivano gestite
precedentemente è stato quindi introdotto un terzo livello di paging
tramite una top level page, che contiene 4 entry a delle pagine di
secondo livello. La top level page è puntata dal registro CR3 . Il
registro CR4 invece ci dice, tramite il PAE-bit (quinto bit), se il
PAE è attivato oppure no.
2 x86-64 Architectures
Lo schema PAE è stato poi esteso tramite la long addressing mode, ovvero x86-64.
2.1 Canonical Addresses
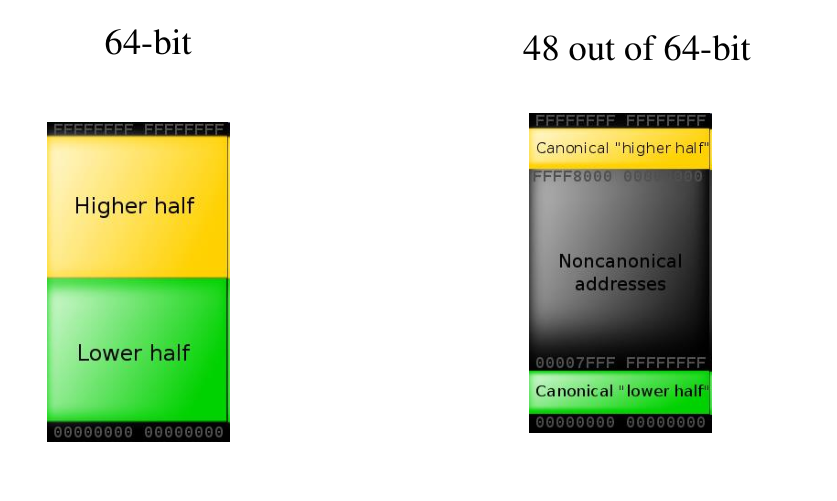
Tramite lo schema long mode gli indirizzi logici sono espressi utilizzando \(64\) bit. In questo schema un processo può, teoricamente, indirizzare \(2^{64}\) bytes di memoria logica. In pratica però, per motivi di convenienza, non tutti gli indirizzi dello spazio di indirizzamento a \(64\) bit sono validi. In particolare è possibile far variare solamente \(48\) bit dell'indirizzo, mentre gli altri sono fissati. Tramite questo schema si riesce quindi a raggiungere \(2^48\) indirizzi logici, ovvero 256 TB. Detto questo, non tutti i sistemi operativi utilizzano l'intero span di 256 TB.
Tale schema di indirizzamento prende il nome di schema di indirizzamento canonico, ed è formato da indirizzi tali che, se il \(48\) -esimo bit è \(1\), allora dal \(49\) in poi sono tutti \(1\), e se il \(48\) -esimo bit è \(0\), allora dal \(49\) in poi sono tutti \(0\).
Ad esempio l'indirizzo 0x00009FFFFFFFFFFFF non è un indirizzo
canonico, in quanto il 48 esimo bit è 1, ma i restanti dal 49 in
su, sono 0, e non 1.
2.2 Linux Address Space on x86-64
Lo spazio di indirizzamento logico a 64 bit per un processo ha la seguente forma,
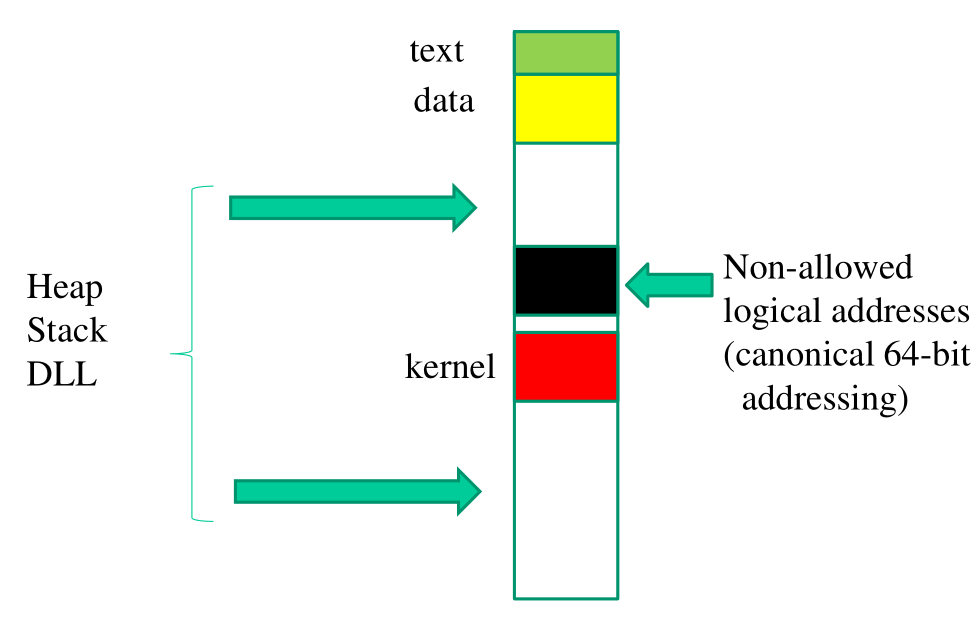
Notiamo che in x86-64 il kernel viene collocato immediatamente dopo la zona dei non-canonical addresses. Il fatto che il kernel non occupa completamente la parte bassa dello spazio di indirizzamento viene fatto per rendere più flessibile eventuali modifiche al kernel.
2.3 48-bit Addessing in x86-64
In long mode abbiamo una paginazione a quattro livelli, in cui tutte le tabelle delle pagine hanno la stessa taglia, ovvero \(512\) entries. La quarta page table aggiunta è chiamata Page-Map level. In questo modo siamo in grado di indirizzare \(512^4\) pagine di size 4KB, per ottenere un totale di 256TB.
L'indirizzo logico viene spezzato nel seguente modo per eseguire il processo di traduzione utilizzando le page tables
L'indirizzo logico viene quindi visto come blocchi da 9 bit, con un offset finale da 12 bit. Ciascun blocco viene utilizzato per indicizzare la page table di un particolare livello.
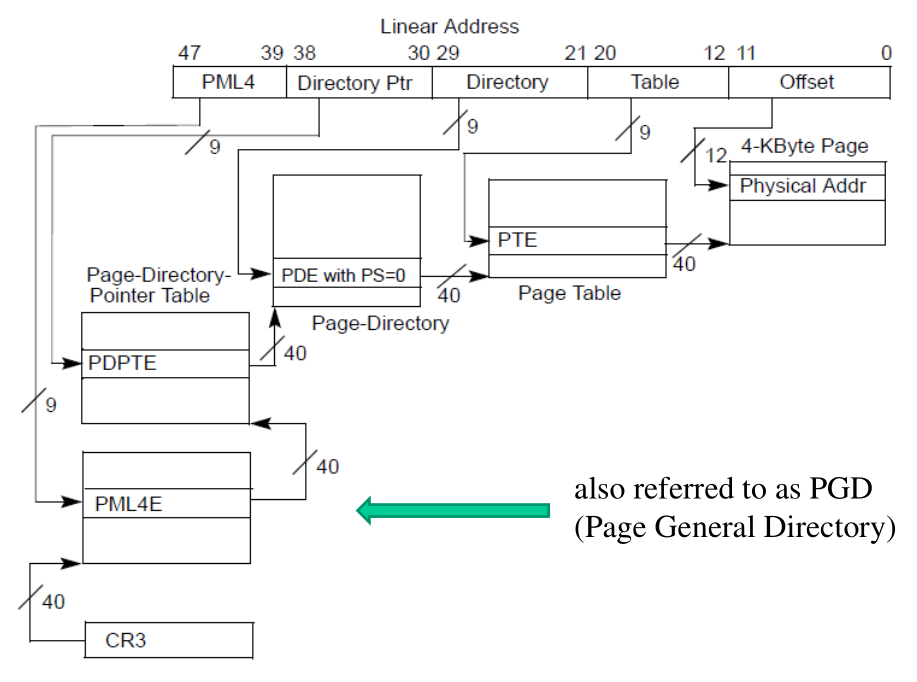
Notiamo che oltre alla possibilità di mappare pagine di 4KB o di 2MB, le entry della tabella di secondo livello, la PDPT (Page Directory Pointer Table), possono contenere gli indirizzi di tabelle di terzo livello, oppure indirizzi di frame grandi 1GB.
Per ogni tabella delle pagine, e per ogni entry, è presente un bit XD, che ci permette di stabilire se è possibile eseguire il fetch da quelle particolari pagine. Questo meccanismo base ha fornito gli strumenti per implementare meccanismi di protezione, come il bit NX (stack non eseguibile).
Osservazione: Nei processori x86 long mode, tramite una singola entry della PML4 siamo in grado di mappare 512 GB. Questo ci permette di mappare in modo diretto tutta la memoria fisica in modo diretto, ed eventualmente rimapparla in modo non diretto per motivi di flessibilità.
2.4 PAGE-TABLE-AUDITOR/page-table-auditor.c
In questo esempio è presente una system call,
sys_page_table_audit() , che prende un intero, e a seconda
dell'intero la sys call fa una page walk delle page table fino al
livello specificato.
Notiamo che nella particolare esecuzione vista in classe si era visto che la page table che veniva osservata non era quella del livello user, ma piuttosto quella del livello kernel. Tramite la PTI (Page Table Isolation) infatti, il contenuto del registro CR3 viene cambiato.
Osservazione: Il software, quando manda in setup la page table per un nuovo processo che deve partire, crea una PML4 di 8KB, allineata agli 8KB. I primi 4KB sono relativi alla tabella per l'applicazione, ovvero user-mode, mentre i secondi 4KB sono relativi alla tabella del kernel. Le struttre dati del kernel che vengono molto più spesso in lettura piuttosto che in scrittura vengono mappate in pagine giganti di 1GB.
2.5 Huge Pages for Users
L'architettura offre l'allocazione di pagine di 1GB a partire dalla PDPT (second level page table). I sistemi operativi come Linux però offorno il supporto delle huge pages solamente a partire dal terzo livello, ovvero dalla PDE. Questo significa che un processo applicativo può scegliere se utilizzare pagine a granularità 2MB, oppure pagina a granularità 4KB.
Il file /proc/sys/vm/nr_hugepages conta il numero di huge pages che
posso utilizzare lato user, mentre il file /proc/meminfo contiene
varie informazioni sulla memoria.
L'utilizzo di huge pages può essere utile per non creare troppi conflitti nelle linee di cache. Le linee di cache infatti non memorizzano l'intero indirizzo fisico, ma solamente parte di esso. Da questo segue che se ho tante pagine da 4KB che si trovano in luoghi sparsi della memoria fisica, può succedere che alcune pagine possano avere dei conflitti e quindi non riesco a controllare i conflitti nelle cache.
3 L1 Terminal Fault (L1TF)
Nelle architettura moderne sono presenti dei problemi di sicurezza relativi alle page table entries.
In particolare, supponiamo di voler accedere ad un indirizzo logico
che viene mappato da una entry della page table con bit di validità
a 0. La CPU, quando capisce che la table entry non è valida, non
lancia direttamente una eccezione, ma marka l'istruzione come
offending, e continua speculativamente ad eseguire altre
istruzioni. Se il TAG dell'indirizzo fisico presente nella PTE con
present bit a 0 è presente nella L1 cache del CPU core, il dato
relativo all'indirizzo viene, speculativamente, passato al
processore. Questo dato, anche se viene solo letto durante
l'esecuzione speculativa, può essere utilizzato per fare probing
tramite il caricamento di una particolare pagina di un array nella
cache.
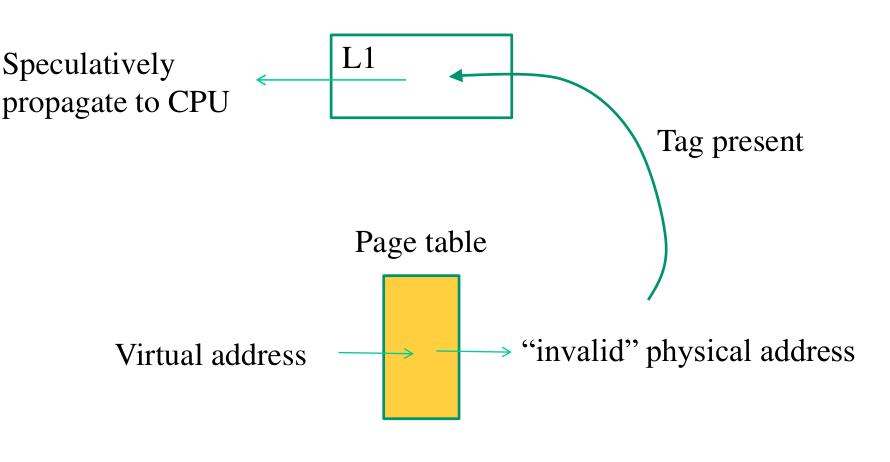
Quindi, il punto critico dell'architettura che provoca la vulnerabilità nota come L1TF è il fatto che una page table entry con il presence bit settato a 0, per via di ottimizzazioni fatte dall'hardware, specialmente in processori Intel, può propagare il valore puntato dall'indirizzo fisico contenuto all'interno della page table entry se il TAG relativo a quell'indirizzo fisico è già presente nella L1 cache.
Per eseguire questo attacco l'attaccante deve:
Associare un indirizzo virtuale ad una page table entry che è stata precedentemente modificata dall'attaccante.
La page table entry modificata deve contenere l'indirizzo fisico che vogliamo leggere, e il present bit deve essere uguale a 0.
Se l'allocazione associata a quell'indirizzo fisico era già presente nella L1 cache, durante la risoluzione dell'indirizzo virtuale in modo speculativo il valore viene propagato dalla cache al processore, che lo può puoi utilizzare per fare del probing e leggere tramite un side-channel il valore propagato.
L'assunto fondamentale per questo attacco è quindi che il dato a cui stiamo tentando di accedere sia già caricato nella L1 cache. Si potrebbe quindi pensare che semplicemente facendo un cache flush ogni volta che scheduliamo la nostra vm, allora l'attacco L1TF non potrà funzionare. Notiamo però che questo non basta, in quanto le architetture moderne sono hyper-threaded, e quindi abbiamo più flussi di esecuzione che lavorano sullo stesso core e che utilizzano la stessa L1 cache.
3.1 L1TF and Virtualization
Per fare questo attacco bisogna essere in grado di modificare le page table del sistema operativo. Questo potrebbe far pensare che questo tipo di attacco non è poi così grave.
In realtà, la vulnerabilità L1TF diventa critica in contesti di cloud computing, e in generale di data center e web services. Infatti oramai la virtualizzazione è ovunque, e i data center hanno un sacco di macchine virtuali, alcune delle quali condividono la stessa cache L1.
Questo implica che una VM, andando a modificare le proprie page tables, può attaccare l'underlying host, e quindi anche altre macchine virtuali.
3.2 Hardware Supported "virtual memory" Virtualization
Quando scheduliamo una vm, entriamo in una modalità chiamata
Virtual Machine Mode. Quando entriamo in VMM, il registro CR3 viene
cambiato per puntare alla page table utilizzata per iniziare il
processo di traduzione di un indirizzo virtuale all'interno della
virtual machine.
Lavorando con una VM abbiamo quindi due livelli di page walk:
La prima page walk serve per capire qual'è l'indirizzo fisico della VM associato all'indirizzo virtuale della VM;
L'indirizzo fisico della VM viene poi trattato come indirizzo logico dell'host, e viene tradotto tramite una seconda page walk per capire il relativo indirizzo fisico dell'host.
A seconda dei processi abbiamo diverse tecnologie per avere questo supporto:
Intel Extended Page Tables (EPT)
AMD Nested Page Tables (NPT)
4 Core Map
La core map è un array le cui entry mantengono informazioni su uno
specifico frame. In uno schema di direct mapping poi le informazioni
mappate sui frame mantengono implicitamente le informazioni sulle
pagine logiche mappate su quel frame.
Nel kernel linux la core map è un array di mem_map_t , la cui
struttura è definita nel file include/linux/mm.h
typedef struct page { struct list_head list; //... atomic_t count; /* Conta il numero di pagine logiche mappate su quel particolare frame */ unsigned long flags; /* Flags utilizzate per descrivere particolari informazioni sul frame */ //... } mem_map_t;
Notiamo in particolare l'elemento struct list_head list , che ci
permette di relazionare tra loro diversi elementi della core
map. Questi collegamenti sono poi utilizzati per creare le free
lists , che sono viste ad alto livello dello stato della core-map.
Inizialmente la struttura non esiste, e la dobbiamo creare in modo
dinamico durante lo start-up. La struttura della core-map è mem_map
ed è dichiarata nel file mm/memory.c .
L'inizializzazine del pointer alla core map viene fatta tramite
l'esecuzione della funzione free_area_init() .
Dopo l'inizializzazione, ogni entry della core-map, e quindi ogni
frame, avrà il valore di 0 nel suo reference counter (campo count),
ed avrà il il bit PG_reserved nel campo flags.
Le pagine vengono poi rilasciate tramite l'esecuzione della funzione
mem_init() , presente in arch/i386/mm/init.c , che resetta il bit
PG_reserved .