AOS - 19 - CROSS RING DATA MOVE I
Lecture Info
Data:
Sito corso: link
Slides: AOS - 4 CROSS RING DATA MOVE I
Progresso unità: 1/1
Argomenti:
User/Kernel Data Movement Problem
Fix for Flexible Segmentation
Per-Thread Memory Limits*
User/Kernel Data Move API
Service Redundancy
Constrained Supervisor Mode
Kernel Masked Segfaults
Introduzione: In questa lezione ci poniamo il seguente problema: come possiamo comunicare informazioni tra moduli software che lavorano ad un livello di privilegio differente?
1 User/Kernel Interactions
Abbiamo visto nelle lezioni precedenti che siamo in grado di
cambiare il livello di privilegio del flusso di esecuzione passando
da lato user a lato kernel. Gli effetti di questo passaggio sono il
cambio del registri di segmentazione e il cambio del CPL associato
al text segment.
Abbiamo già visto, attraverso l'architettura delle system calls, e
le istruzioni syscall~/~int 0x80 come sia possibile utilizzare i
general purpose registers della CPU per passare i valori tra lo user
space e il kernel space.
L'utilizzo dei soli registri della CPU però non è una soluzione
scalabile per passare i dati da user/kernel. Per implementare
meccanismi di I/O, ad esempio per le system calls read() write()
necessitiamo di un ulteriore meccanismo di passaggio dei dati.
Lo scambio di pointers tra user space e kernel space offre un meccanismo in grado di passare dati da user a kernel in modo più flessibile.
L'utilizzo dei pointers però rompe completamente il sistema di protezione ring-based, in quanto un pointer può essere definito lato user, e il contenuto puntato può essere sovrascritto, o semplicemente letto, lato kernel. Questo implica che non c'è una separazione netta tra i vari livelli, in quanto è l'user che stabilisce dove il kernel va a lavorare. Necessitiamo dunque di meccanismi addizionali per gestire la comunicazione user/kernel senza rompere il ring-model.
Le possibili soluzioni a questa problematica dipendono dai supporti offerti dall'hardware, come il supporto per la segmentazione, ed eventuali altri componenti più recenti.
1.1 Flexible Segmentation
Consideriamo il caso in cui abbiamo una segmentazione flessibile, ovvero una segmentazione in cui:
La base di ogni segmento può essere un qualsiasi indirizzo logico.
La dimensione dei segmenti può essere di taglia arbitraria.
In questo caso ad esempio ricade la protected-mode offerta
dall'archtiettura x86 .
Con questo supporto siamo in grado di separare completamente i buffer utilizzati lato users e i buffer utilizzati lato kernel, e quindi siamo sempre in grado di stabilire se una lettura/scrittura fatta in modalità kernel va su zone di memoria allocate allo user space.
Utilizzando questo approccio però dobbiamo stare attenti e non
lasciare la gestione della segmentazione completamente al
compilatore. In particolare, se assumiamo che i segmenti CS/DS lato
user e quelli CS/DS lato kernel iniziano da basi diverse, allora
non possiamo semplicemente utilizzare gli offset che ci vengono
passati lato user, in quanto altrimenti, girando lato kernel,
andremmo ad applicare l'offset al selettore DS kernel, e non al
selettore DS user.
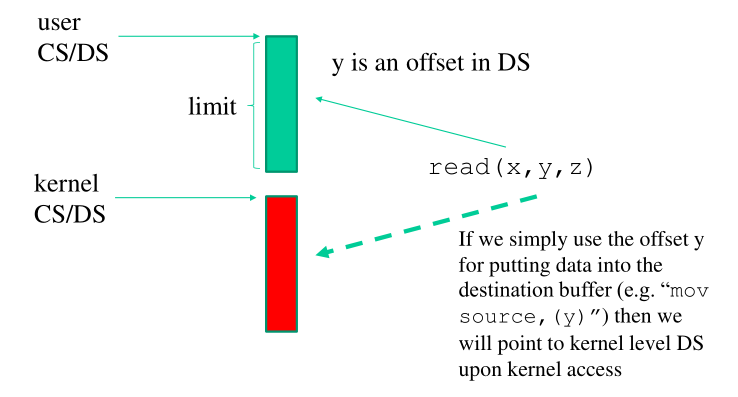
L'idea è quindi quella di gestire "a mano" le istruzioni che
spostano informazioni dal lato user al lato kernel. In particolare
è possibile utilizzare il selettore di segmenti FS mappandolo al
selettore DS lato user. Le istruzioni che muovono dati devono
quindi utilizzare il displacement FS assieme all'offset passato
dall'utente. Queste operazioni vengono anche chiamate segmentation
fixup.
Supponiamo quindi che l'utente esegue una read(src, dst,
count) . Lato kernel dobbiamo eseguire le seguenti operazioni:
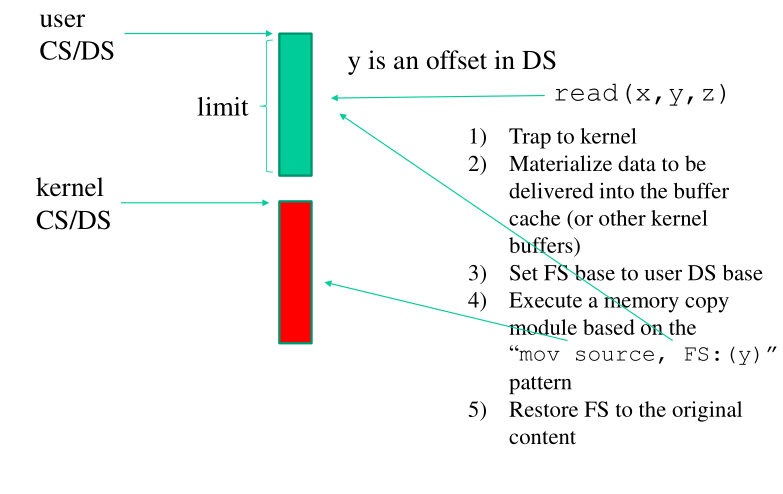
In dettaglio:
Entriamo lato kernel con una trap (int x080 o syscall).
Materializziamo in qualche buffer livello kernel i dati che devono essere passati all'user.
Settiamo la base del segmento
FSpari alla base del segmentoDSlatouser.Eseguiamo una copia della memoria utilizzando
FScome displacementmov src, FS: (dst)
Ripristiniamo il valore originario del selettore FS.
Le operazioni di semgentation fixup coinvolgono quindi più
istruzioni macchina del previsto, ed è per questa ragione che molto
spesso le librerie di sistema, come libc , utilizzano dei buffer
interni e cercano di chiamare le system call nel modo più
morigerato possibile.
1.2 Constrained Segmentation
Nelle moderne versioni di x86 , ovvero nella modalità long-mode , la
soluzione descritta prima non può più essere applicata in quanto
tutti i segmenti tranne FS e GS hanno la base forzata all'indirizzo
0x0 . Utilizzando la soluzione vista prima il risultato può essere
una scrittura nelle pagine del kernel a seconda del valore di 'y',
che viene passato dall'utente.
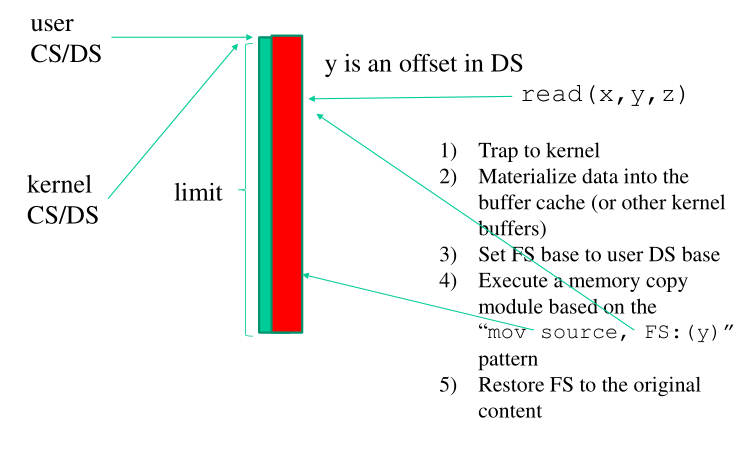
Le soluzioni offerte in questo caso dunque non possono far affidamento solamente allo stato del processore, ma devono necessariamente utilizzare delle facility software del kernel, il cui compito principale è quello di verificare la leggitimità delle operazioni di scambio dati tra user space e kernel space. Questa verifica deve essere effettuata individualmente per ogni thread e per ogni address space gestito dal kernel.
I singoli thread hanno quindi deve limitazioni sui luoghi in cui i pointers possono puntare per l'eventuale scambio di informazioni user/kernel space.
2 Per-Thread Memory Limits
Per rappresentare gli address space linux utilizza due supporti, che sono:
addr_limit: è un pointer (di tipo unsigned long) che descrive quali sono le zone di memoria specificabili a livello user da quel thread per il movimento dati. Tale pointer viene embeddato all'interno di una struttura con il nome
seg. Può essere letto con la APIget_fs()e può essere aggiornato ad un valore generico con la kernel APIset_fs(x).Se l'area di memoria in cui vado a fare movimento dati supera l'addr_limit, l'operazione non è valida. Questo tipo di controllo è semplice e veloce e tutti i servizi che implementano movimento dati tra user e kernel controllano questo campo.
// Current the limit is set to 0x00007ffffffff000, which is the lower // half of the x86 long mode canonical addressing form. // Show current addr_limit unsigned long limit; limit = (unsigned long) get_fs().seg; printk("limit is %p\n", limit);
La possibilità di cambiare l'addr_limit tramite la API set_fs() viene fornita perché altrimenti non saremmo in grado di leggere i dati lato kernel nella memoria.
Oltre a capire se i buffer specificati a livello user sono leggittimi, un altro controllo viene eseguito sulla leggimità dell'esistenza dei buffer in cui il lato user ci ha detto di scrivere. Può infatti succedere che ci venga specificato un indirizzo leggitimo e quindi che passa il controllo su
addr_limit, ma che non è stato mappato. L'eventuale accesso in lettura/scrittura a tale indirizzo andrebbe a generare unseg_fault. Dato però che lavoriamo in lato kernel, non possiamo generare un seg_fault.
3 User/Kernel Data Move API
A seguire troviamo le API del kernel che implementano tutti i controlli necessari per scambiare informazioni user/kernel:
copy_from_user(): Copia
nbytes dall'indirizzo user spacefromall'indirizzo kernel spaceto.unsigned long copy_from_user(void *to, const void *from, unsigned long n);
copy_to_user(): Copia
nbytes dall'indirizzo kernel spacefromall'indirizzo user spaceto.unsigned long copy_to_user(void *to, const void *from, unsigned long n);
get_user(): Copia un valore intero dall'indirizzo user space
fromall'indirizzo kernel spaceto.void get_user(void *to, void *from);
put_user(): Copia un valore intero dall'indirizzo kernel space
fromall'indirizzo user spaceto.void put_user(void *from, void *to);
strncpy_from_user(): Copia una stringa
null-terminated di al massimocountbytes dall'indirizzo user spacesrcall'indirizzo kernel spacedstlong strncpy_from_user(char *dst, const char *src, long count);
access_ok(): Ritorna un valore diverso da \(0\) se lo spazio di memoria user space è valido, e \(0\) altrimenti. Questa funzione viene chiamata dalle altre API per verificare la validità del trasferimento dati.
int access_ok(int type, unsigned long addr, unsigned long size);
Notiamo che queste operazioni di lettura/scrittura possono essere bloccati da altri componenti del kernel. Questo vuol dire che queste operazioni possono "fallire". In caso di fallimento le API ritornano il numero di bytes che devono essere ancora spostati. In ogni caso, questi "fallimenti" sono limitati a regioni già mappate dello spazio di indirizzamento, e dunque non portano alla generazione di segmentation faults.
L'operazione di spostamento potrebbe anche portare il thread a bloccarsi (sleep).
3.1 copy_to_user() timeline
Le moderne versioni di linux utilizzano le facility SMAP e SMEP
(leggi avanti) offerte dall'hardware per aumentare il livello di
sicurezza del sistema. L'implementazione delle facility
copy_to_user() e copy_from_user() necessitano quindi la
disabilitazione temporanea di SMAP.
Per effettuare una copy_to_user() vengono effettuate le seguenti operazioni:
Si controlla il per-thread limit tramite la variabile
addr_limitper verificare se la zona di memoria con cui dobbiamo interagire ricade nel corretto intervallo.Si determina la quantità legale di dati da copiare.
Si disabilità
SMAPmodificando laACflag nel registroEFLAGStramite l'istruzione x86stac.Si effettua la copia (potrei bloccarmi, ma niente SEGFAULT).
Si abilità SMAP di nuovo, tramite l'istruzione x86 clacl che modifica la AC flag nel registro EFLGS.
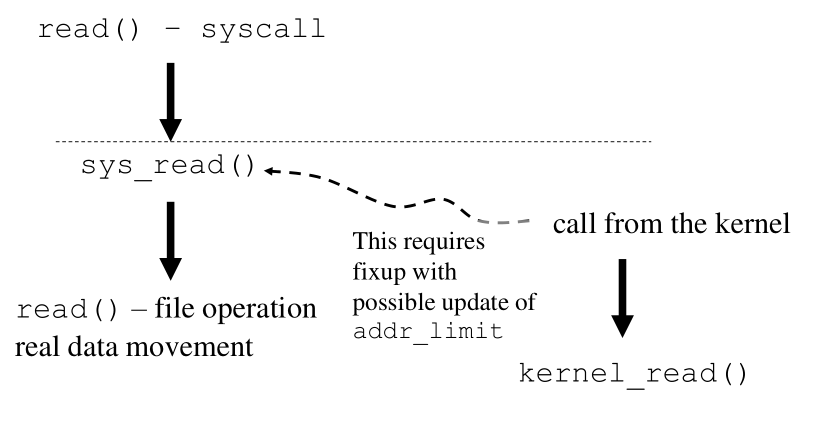
4 Service Redundancy
Supponiamo di avere un servizio importante per fare movimento dati,
e supponiamo che questo servizio deve poter essere utilizzato sia
dal software user sia dal software kernel. Un esempio potrebbe
essere la sys_read() , che è la versione kernel della funzione read()
e che viene molto spesso dal software livello kernel.
Con l'architettura vista prima, in particolare con il controllo al
valore addr_limit , se del codice kernel dovesse chiamare la funzione
sys_read() che esegue la copy_from_user() , quest'ultima chiamata
fallisce, in quanto qualsiasi buffer del kernel supererà
necessariamente il limite addr_limit .
Per poter utilizzare la sys_read() anche all'interno del kernel un
primo approccio potrebbe essere quello di modificare il valore di
addr_limit per "cammuffare" i buffer del kernel e farli passare
come validi buffer users. Questa soluzione però è estremamente
inefficiente, in quanto se chiamo la funzione dall'interno del
kernel non devo fare nessun controllo sull'eventuale utilizzo di
buffers del kernel.
Un altro approccio è quello della "service redundancy", che si
basa sul duplicare il servizio read() all'interno del
kernel. Abbiamo quindi due funzioni read() , una utilizzata per far
interagire user e kernel, sys_read() , e un'altra utilizzata solo
per chiamate che partono dal kernel, kernel_read() .
5 Constrained Supervisor Mode
Cosa succede se per via di un bug, o di un effetto speculativo, la
funzione memcpy() viene chiamata dal kernel con dei pointer
arbitrary? Una situazione del genere potrebbe far si che il kernel
scriva su pagine accessibili lato user, ed è quindi importante da
risolvere.
Nelle versioni datate dei processori e di linux non potevamo farci nulla al riguardo.
Nelle architetture moderne è stata introdotta una modalità operativa
del processore chiamata constrained supervisor mode. Questa modalità
permette di imporre dei limiti sul movimento dati anche al ring
0 . In particolare, se la modalità è attiva effettuare delle attività
su delle pagine mappate lato user porta alla generazione di una trap.
Questa modalità cambia quindi il modo in cui il firmware gestisce la page table e mi permette di ottenere un maggior livello di sicurezza.
L'attivazione del constraint supervisor mode in x86 viene effettuata
tramite due bits del registro CR4 (il \(21\) e \(20\)). In particolare
abbiamo due facility, che sono
SMAP (Supervisor Mode Access Prevention): Blocks data access to user pages when running at CPL 0. SMAP può essere disabilitata settando il bit AC nel registro di stato EFLAGS.
SMEP (Supervisor Mode Execution Prevention): Blocks instruction fetches from user page when running at CPL 0.
6 Kernel Masked Segfaults
Notiamo nella timeline della copy_to_user(), per effettuare il passo
2, ovvero la determinazione della quantità legale di dati da
copiare, siamo costretti ad ispezionare la memory map tramite la
struttura mm del running thread. Per fare questo necessitiamo dunque
di ulteriori istruzioni macchina, e il tutto potrebbe avere un costo
lineare (non costante).
Per motivi di performance le versioni moderne del kernel all'interno
della funzione access_ok() eseguono solo il check sul valore di
addr_limit . Se il check passa, la memoria viene copiata
direttamente, senza controllare che le pagine coinvolte siano pagine
effettivamente mmappate.
Questo vuol dire che durante l'operazione di copiatura il kernel
potrebbe potenzialmente andare in SEGFAULT . Per gestire questa
situazione è stato introdotto il masking dei kernel
segfaults. Utilizzando questo sistema il page fault handler che
gestisce il SEGFAULT ha una tablela in cui sono presenti due
sequenze di valori di RIP : Nella prima colonna sono presenti i
valori del registro RIP (segfaulting RIP) per eventuali segfaults
durante il movimento dati da user/kernel, e nella seconda colonna
sono presenti gli alternative RIP che il page fault handler deve
seguire per gestire gli eventuali SEGFAULTS.
Il codice di blocco alternativo non fa altro che ritornare il numero di bytes che devono ancora essere scambiati alla routine che ha chiamato la routine di movimento.
7 RUNNING EXAMPLES
7.1 message-exchange-service
Implementa un servizio di logging e retrieval di messaggi all'interno di un buffer del kernel senza bufferizzazione esterna. Necessita la conoscenza dell'indirizzo di memoria della sys_call_table.
/* IMPORTANT: nelle funzioni sys_log_message() e sys_get_message() quando entro nelle sezioni critico e chiamo le funzioni copy_from_user() e copy_to_user() posso essere bloccato dal page fault handler. Dunque, fino a quando non finisco, la risorsa è bloccata e nessun altro thread può accedere al buffer. Questa versione senza buffering intermedio non è quindi molto performante. ,*/ // buffer utilizzato per postare i messaggi con il relativo size. #define MAX_MSG_SIZE 4096 char kernel_buff[MAX_MSG_SIZE]; size_t valid = 0; // Dato che le operazioni di modifica del buffer non possono essere // effettuate in modo atomico, dobbiamo utilizzare un semaforo. static DEFINE_MUTEX(log_get_mutex); // sys call utilizzata lato user per postare il messaggio nel buffer. asmlinkage long sys_log_message(char *mex, size_t size) { int ret; if(size >= (MAX_MSG_SIZE - 1)) goto bad_size; mutex_lock(&log_get_mutex); // Inizio sezione critica ret = copy_from_user((char*) kernel_buff, (char*) mex, size); kernel_buff[size-ret] = '\0'; valid = size - ret; mutex_unlock(&log_get_mutex); // Fine sezione critica return size - ret; // ritorna numero bytes validi bad_size: return -1; } asmlinkage long sys_get_message(char *mex, size_t size) { int ret; if(size > (MAX_MSG_SIZE)) goto bad_size; mutex_lock(&log_get_mutex); if (size > valid) size = valid; ret = copy_to_user((char*) mex, (char*) kernel_buff, size) mutex_unlock(&log_get_mutex); return size - ret; // return number of bytes left to read bad_size: return -1; }
7.2 message-exchange-service-intermediate-buffering
Simile all'esempio visto prima ma questa volta con un buffering intermedio che mi permette di essere più performante.
#define MAX_MSG_SIZE 4096 char kernel_buff[MAX_MSG_SIZE]; size_t valid = 0; static DEFINE_MUTEX(log_get_mutex); // Logs message into kernel buffer with buffering. In particular it // does the following: // // 1) Maps kernel page to use as intermediate buffer; // // 2) uses copy_from_user() to copy mex into intermediate buffer; // // 3) gets lock on kernel_buff and copies the user message previously // copied into the intermediate buffer with memcpy(). // asmlinkage long sys_log_message(char* mex, size_t size) { unsigned long ret; void* addr; if(size >= (MAX_MSG_SIZE - 1)) goto bad_size; // Get a kernel page to use as an intermediate buffer. addr = (void*) get_zeroed_page(GFP_KERNEL); if(addr == NULL) return -1; // NOTE: now we copy in our intermediate buffer, so that, even if we // do get blocked, we are not blocking other threads from accessing // the kernel_buff. // // copy from mex (user_space) to addr (kernel_space). ret = copy_from_user((char*) addr, (char*)mex, size); mutex_lock(&log_get_mutex); // Inizio sezione critica memcpy((char*) kernel_buff, (char*) mex, size); kernel_buff[size - ret] = '\0'; valid = size - ret; mutex_unlock(&log_get_mutex); // Fine sezione critica // Free the kernel page used for buffering. free_pages((unsigned long)addr, 0); return size - ret; bad_size: return -1; } // Gets message from kernel buffer into user buffer with buffering. In // particular it does the following: // // 1) Maps kernel page to use as intermediate buffer; // // 2) Takes lock on kernel_buff to copy its content in intermediate // buffer using memcpy. // // 3) uses copy_to_user() to copy intermediate buffer to user buffer. // asmlinkage long sys_get_message(char* mex, size_t size) { int ret; void* addr; if(size > (MAX_MSG_SIZE)) goto bad_size; if (size > valid) size = valid; addr = (void*) get_zeroed_page(GFP_KERNEL); mutex_lock(&log_get_mutex); memcpy((char*) addr, (char*) kernel_buff, size) mutex_unlock(&log_get_mutex); // Copy from addr (kernel space) to mex (user space). ret = copy_to_user((char*) mex, (char*) addr, size); free_pages((unsigned long) addr, 0); return size - ret; // return bytes left to read bad_size: return -1; }