AOS - 22 - KERNEL TASK MANAGEMENT I
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 1/7
Argomenti:
Definizione di Tasks
Deferred Work
Top/Bottom Half Programming
Task Queues
SoftIRQ Architecture
Tasklets
Introduzione: In questa lezione abbiamo iniziato a vedere i meccanismi e le strutture dati principali che il kernel utilizza per la gesitone dei processi, e più in generale per la gestione dei tasks.
1 Homework #4
TODO.
2 Homework #5
TODO.
3 Tasks vs Processes/Threads
Sui sistemi convenzionali un task è visto come una traccia di esecuzione di istruzioni macchina. Abbiamo tre tipologie di traccie di esecuzioni:
User mode process/thread
Kernel mode process/thread
Interrupt management
Per gestire tutte le varie traccie all'interno di un sistema necessitiamo quindi di un meccanismo di time-sharing, che assegna le risorse dell'hardware di volta in volta a tracce diverse.
4 Time-Sharing With Work Deferring
La gestione del time-sharing in modo non-deterministico, ovvero quando accetto interrupts in un qualsiasi momento durante l'esecuzione del thread, può avere dei problemi di inefficienza e scalabilità quando le tracce di esecuzione sono estremamente legate tra loro. Così facendo infatti il tempo medio per eseguire le sezioni critiche può variare enormemente.
Un altro modo per gestire il time-sharing è in modo deterministico. Con questa modalità i momenti durante l'esecuzione in cui vado a gestire gli interrupt sono deterministicamente pre-determinati. Questa tecnica si chiama work deferring, in quanto stiamo ritardando il lavoro da fare aspettando un momento conveniente.
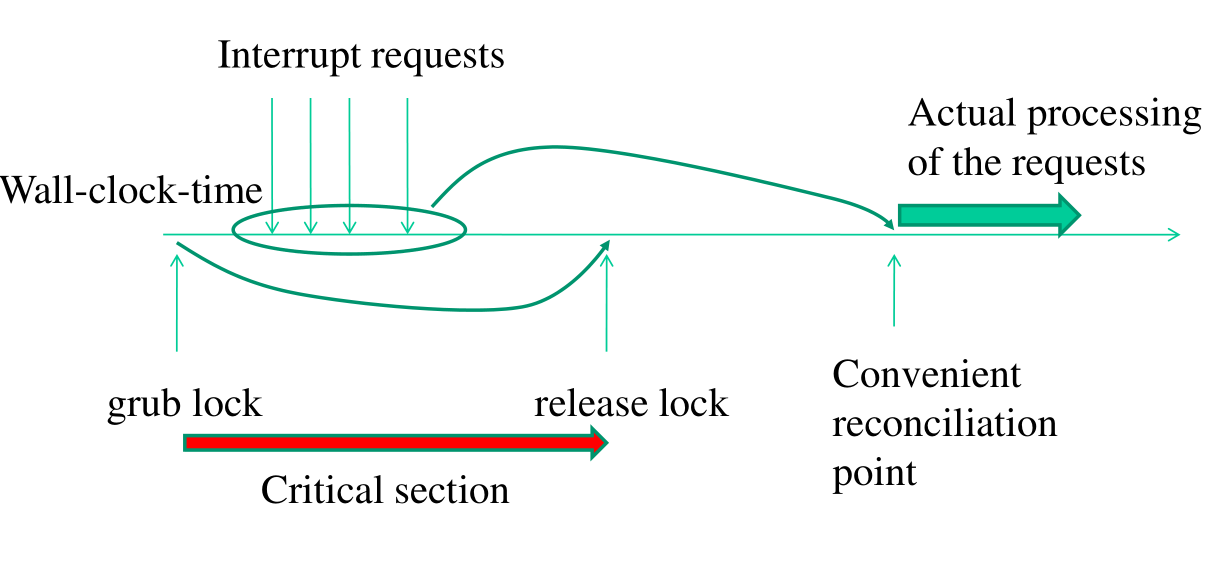
Con il work deferring è possibile poi introdurre un meccanismo di aggregazione, che funziona andando a raggruppare insieme dei task di lavoro da eseguire. Ogni volta in cui la CPU è libera possiamo andare ad eseguire tutti i task che sono stati deferred.
4.1 Reconciliation Points
Tramite il work deferred possiamo spostare il lavoro richiesto dagli interrupt a determinati momenti durante l'esecuzione di un thread. I punti in cui andiamo a fare del deferred work sono i seguenti:
Ritorno da syscall: Questo necessita che all'interno del nostro sistema ci siano delle applicazioni che possano chiamare delle system calls. Inoltre non può essere l'unico punto di riconciliazione.
Context-switch: Ogni volta che facciamo del context-switch verifichiamo anche se c'è del deferred work da fare. Questo necessita che ci sia almeno un thread in esecuzione e quindi che si possa chiamare la funzione di schedule. Questa richiesta è soddisfatta dalla presenza dell'idle-process.
Riconciliazione all'interno di un process-context: Con questo schema il deferred work viene gestito da un thread kernel level.
La gestione tramite il deferred work garantisce un eventually, ovvero che ogni singolo interrupt viene processato ad un certo punto durante l'esecuzione del sistema.
4.2 Top/Bottom Half Programminng
L'introduzione del deferred work e dei reconciliation points tende a favorire le attività del software a discapito di quelle dell'hardware. Infatti, se ogni volta che riceviamo un interrupt non facciamo nulla, il dispositivo che ha inviato l'interrupt non riceve neanche l'ACK, e quindi rimane bloccato.
Per risolvere queste problematiche è stato implementato nel kernel linux un paradigma più generale che prende il nome di top/bottom half programming. L'idea è quella di splittare in due parti ogni task, che sono:
Top-half: La parte iniziale, detta top-half, esegue un lavoro minimale rispetto al task totale, e viene eseguito come preparazione per la successiva finalizzazione del task completo. La porzione del codice top-half, tipicamente, è gestita con uno schema non-interrompibile.
La porzione top-half del task si deve anche occupare di memorizzare da qualche parte che successivamente la parte bottom-half relativa allo stesso interrupt deve essere eseguita.
Bottom-half: La parte finale, detta bottom-half, viene eseguita più tardi di quella top-half e si occupa di finalizzare la richiesta di interrupt.
Tramite il top/bottom half programming siamo quindi in grado di gestire gli eventi in modo scalabile senza mantenere le risorse hardware lockate subito dopo l'invio dei segnali di interrupt.
Esempio: Supponiamo di dover ricevere un pacchetto da un socket. Senza splittare il task possiamo dobbiamo eseguire i seguenti step
packet extraction ip level tcp/udp level vfs level
Se invece utilizziamo il top/bottom half programming, possiamo andare ad estrarre il pacchetto e metterlo in una task queue. Nella task queue ci andrà poi il codice che estrae i dati dal pacchetto e che verrà eseguito in un momento futuro.
4.2.1 Implementation in Linux
Il flusso storico del top/bottom half programming per la gestione degli interrupt nel kernel linux è il seguente:
Viene generato un interrupt.
Tramite il meccanismo di gestione degli interrupt eseguo un particolare interrupt handler che esegue il top-half del task e mette in una particolare struttura dati il fatto che la relativa bottom half deve essere eseguita.
Ritorno dalla gestione dell'interrupt e continuo la normale esecuzione del thread.
Appena mi trovo in un punto di riconciliazione vado ad eseguire il bottom-half inserito prima.
In LINUX questo archetipo architetturale è stato implementato in due modi diversi: nelle versioni < 2.5 del kernel abbiamo le task queues, mentre nelle versioni > 2.5 del kernel abbiamo le Softirqs, le Tasklets e le Work queues.
Osservazione: Anche se i task bottom half possono essere eseguiti in process context da un particolare thread a livello kernel, il contesto in cui quel thread gira deve comunque essere "interrupt context", in quanto durante l'esecuzione dei bottom-halves non possiamo avere dei servizi bloccanti.
5 Task Queues
Le task queue sono delle code di task, che possono essere associate a nomi di variabili.
5.1 Pre-Defined Task Queues
A partire dalla versione kernel 2.2 abbiamo tre predefinite task-queues, ciascuna delle quali ha ha determinati punti di riconciliazione:
tq_immediate: Memorizza i task da eseguire sui timer-interrupt o dopo il ritorno da syscall (syscall return).
tq_timer: Memorizza i task da eseguire sui timer-interrupt. Notiamo che c'è una particolare cadenza in cui i timer-interrupt vengono gestiti. Questo non vuol dire che i task memorizzati in questa cosa vengono processati esattamente nel momento in cui si riceve il timer-interrupt.
tq_schedule: Coda guardata da uno specifico thread. I task memorizzati in questa coda sono eseguiti dal thread nel momento stesso in cui questo va in esecuzione, e vengono quindi eseguiti in "process context".
Le prime due task possono essere processate da qualsiasi thread, mentre l'ultima è processata da un thread particolare.
5.2 Task Queue Data Structure
Internamente una task queue è definita nel file
include/linux/tqueue.h nel seguente modo
struct tq_struct { struct tq_struct *next; // linked list of active bottom halves int sync; void (*routine)(void *); // function to call void *data; // argument to function }
Il campo sync deve essere inizializzato a \(0\) quando inserisco la
task all'interno della queue.
5.3 Task Queues API
Il kernel offre le seguenti API per interagire con le task queues
queue_task(): Funzione utilizzata per inserire un nuovo task in una task queue già esistente. Notiamo che questa funzione non esegue il task, ma lo registra solamente.
int queue_task(struct tq_struct *task, task_queue *list);
run_task_queue(): Utilizzato per eseguire tutte le tasks presenti in una data task queue.
void run_task_queue(task_queue *list);
schedule_task(): Utilizzato per accodare un task nella task queue predefinita
tq_schedule.int schedule_task(struct tq_struct *task);
Il valore di ritorno delle API che accodano task ad una particolare
task queue è diverso da zero nel caso in cui il task non è ancora
stato registrato all'interno della queue. Questo controllo sfrutta
il campo sync , che viene settato a \(1\) quando il task viene
accodato.
Per quanto riguarda la creazione di nuove task queue, la seguente
macro, definita in include/linux/tqueue.h , può essere utilizzata
DECLARE_TASK_QUEUE(queuename)
Le task queues create con questa macro possono essere flushate solo
tramite esplicite chiamate alla funzione run_task_queue() . Le task
queue pre-definite invece vengono flushate automaticamente dal
kernel.
Quando inseriamo un task all'interno della tq_immediate task queue,
dobbiamo fare una chiamata alla funzione
mark_bh(IMMEDIATE_BH) . Questa funzione indica che la strutture dati
relativa al task inserito non è vuota.
5.4 Reconciliation Points
Utilizzando le task queues i reconciliation points, definiti
dall'invocazione della funzione do_bottom_half() , sono i seguenti:
All'interno dello scheduler, ovvero all'interno della funzione
schedule().All'interno di
ret_from_syscall(), ovvero quando ritorniamo da system calls.
5.5 Limitations
Una delle più grandi limitazione delle task queues è il fatto che, una volta che un particolare thread comincia ad esegure i task inseriti in una particolare task queues, il thread deve processare tutti i bottom half presenti nella task queues.
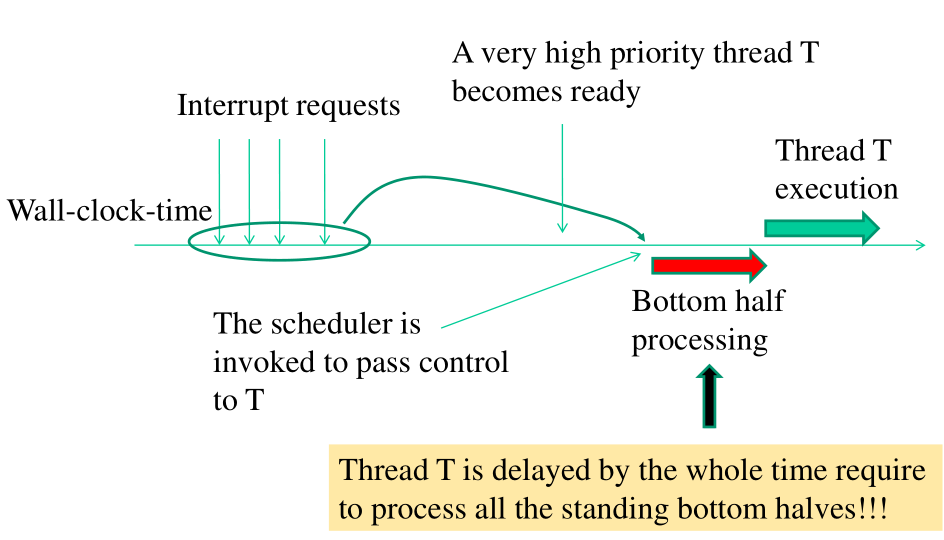
Assegnare ad un solo thread il processamento di tutti i bottom-halves di una task queues ha varie conseguenze, tra cui:
Impossibilità di exploitare multple CPU-cores for interrupt management.
Impossibilità di ottimizzare la località delle operazioni e degli accessi ai dati (NUMA).
Non gestisce bene interrupt con un heavy bottom-half load.
Non gestisce bene una parallelizzazione dell'hardware molto scalata.
Notiamo poi che gli interrupt possono anche essere lanciati dal software. Questo è un tipico scenario per la gestione dei drivers dei logical devices. La conseguenza di questo è che gli interrupt drivers potrebbero richiedere un carico di lavoro proporzionale al numero di threads in esecuzione, e quindi proporzionale al numero di CPU-cores disponibili.
Al fine di migliorare queste limitazioni sono state introdotte delle architeture più scalabili per la gestione degli interrupt.
6 SoftIRQ Architecture
In una softIRQ architecture un interrupt non necessariamente avviene da un dispositivo hardware, ma in modo più generale da un componente software.
A seguire lo schema architetturale:
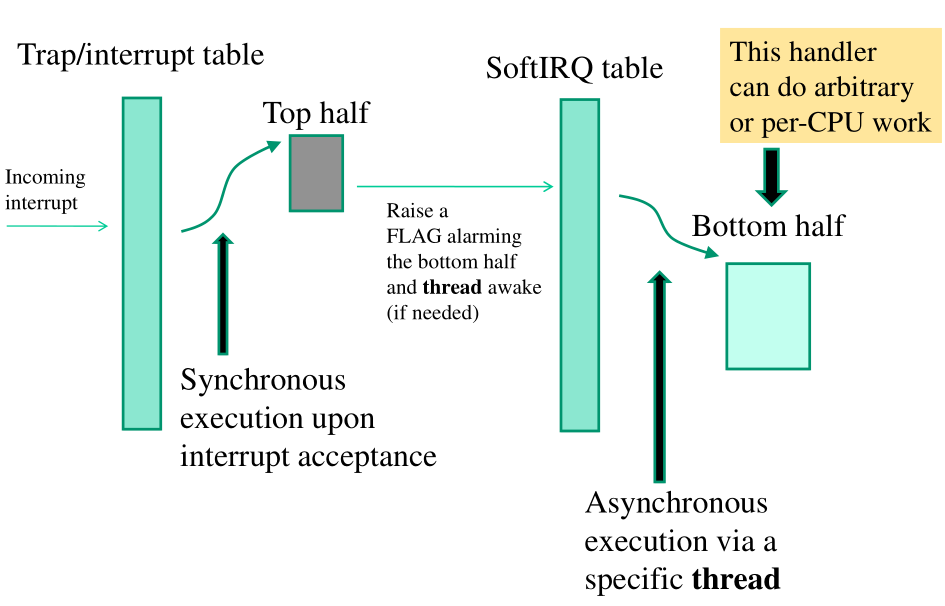
così descritto:
La trap/interrupt table viene modificata per associare a determinati interrupt (o software traps), determinati top-halves.
I top-half fanno un lavoro ancora più minimale rispetto all'architettura con le task queues. Il loro compito è quello di attivare un FLAG di allarme all'interno di una entry della SoftIRQ tabel. Oltre a settare il FLAG della SoftIRQ vanno anche a svegliare un particolare demon del kernel, il softirq-demon, che si occupa di andare a vedere se ci sono bottom-halves da eseguire.
La SoftIRQ table contiene i bottom-half da processare. Questi bottom-halves sono stati già pre-registrati all'interno della tabella.
Utilizzando questa architettura riusciamo a minimizzare ancora di più il lavoro svolto dalla parte top-half di un interrupt. Possiamo inoltre avere un numero arbitrario di softirq-demons, anche se in genere abbiamo un softirq-demon per CPU.
6.1 Tasklets
Per come è stata introdotta, l'architettura softIRQ sta perdendo una cosa fondamentale: la possiblità di avere del deferred work accodato uno dopo l'altro. Questa mancanza però può immediatamente essere risolta notando il fatto che ci basta assegnare ad uno specifico bottom-half il compito di guardare in una coda e di eseguire i task all'interno di questa coda.
Questa coda nell'implementazione Linux dell'architettura softIRQ è detta tasklet. Un particolare bottom-half della softIRQ table ha quindi il compito di andare ad eseguire i task salvati nella tasklet.
Per rendere questo meccanismo più efficiente e scalabile possibile, possiamo poi rendere la tasklet una PER-CPU variable. Così facendo ogni cpu ha la propria tasklet e il proprio softirq-demon.