AOS - 23 - KERNEL TASK MANAGEMENT II
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 2/7
Argomenti:
SoftIRQ Entries
Tasklet API
Work Queues
Concurrency Managed Work Queues
container_of() macro
Introduzione: Nella scorsa lezione avevamo introdotto il concetto di top/bottom half programming per gestire al meglio gli interrupts. Avevamo poi discusso dell'architettura delle task queues, e delle sue limitazione. Infine, per cercare di mgliorare le problematiche delle task queues, avevamo introdotto l'architettura softIRQ.
1 SoftIRQ (Kernels > 2.5)
Nella softIRQ architecture i bottom-half sono pre-registrati, e quindi, il relativo top-half non deve scorrere la coda per inserire il task alla fine, ma può semplicemente attivare il flag della softIRQ table.
Dato che i bottom-half sono pezzi di codice, il fatto che siano unici e pre-registrati non causa un bottleneck, in quanto più CPU-cores possono eseguire lo stesso bottom-half in modo parallelo, lavorando ciascuno su diversi dati.
Quando arriva un segnale di interrupt, il thread che sta eseguendo fa le seguenti cose:
Utilizza la interrupt table per vedere come gestire l'interrupt, ovvero per vedere il top-half dell'interrupt handler associato a quel particolare interrupt.
Attiva una particolare FLAG nella softIRQ table.
Risveglia il thread che si occupa di eseguire i bottom-halves per il relativo CPU-core.
Tramite delle bitmask è poi possibile implementare un meccanismo di affinità per far gestire gli interrupt a diversi CPU-core. É anche possibile che a linee diverse di interrupt andiamo ad associare lo stesso bottom-half.
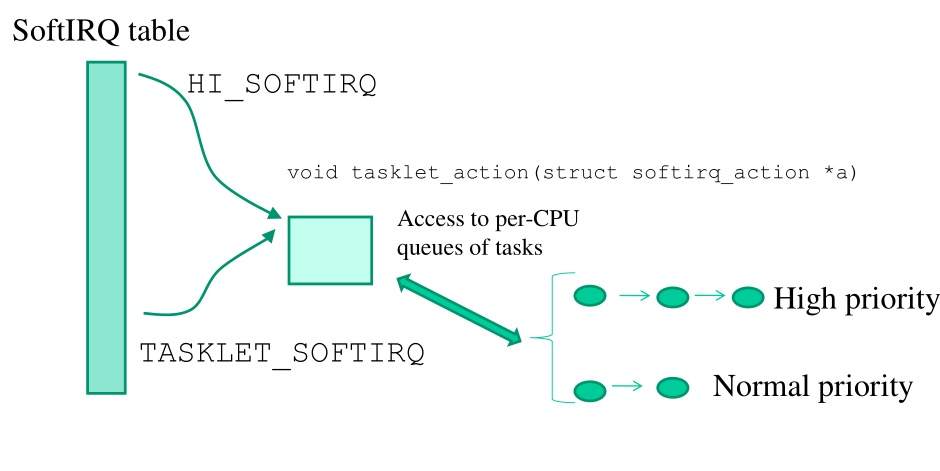
1.1 SoftIRQ Entries
La softIRQ table è un array di NR_SOFTIRQS . Ciascuna entrata
dell'array identifica una particolare struct softirq_action , che
rappresenta uno specifico bottom-half.
Alle entrate della tabella sono associati diverse tipologie con diverse priorità di handlers. L'insieme dei bottom-half presenti sono i seguenti
enum { // high priority queued stuff HI_SOFTIRQ = 0, // Stuff to do on timers or reschedules TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, BLOCK_IOPOLL_SOFTIRQ, // normal priority queued stuff TASKLET_SOFTIRQ, SCHED_SOFTIRQ, // Stuff to do on timers or reschedules HRTIME_SOFTIRQ, RCU_SOFTIRQ, NR_SOFTIRQS }
Notiamo che nell'architettura SOFTIRQs gli ogetti che vengono accodati non sono i bottom-half, dato che questi sono fissati (1 per ogni entry della tabella). Le cose che vengono accodate vengono memorizzate in determinate strutture dati che poi i bottom-half vanno a leggere e processare.
Tramite i bottom half TIMER_SOFTIRQ e HRTIME_SOFTIRQ siamo in grado
di implementare i timers offerti dal kernel e utilizzati dal
software.
1.2 SoftIRQ Workers
I lavoro deferred viene eseguito da specifici kernel thread. Questi demon sono chiamati ksoftirq, e tendenzialmente ne abbiamo uno per CPU-core.
Una volta svegliato, il softirq daemon comincia a leggere e processare le entry della softIRQ table per vedere se qualche entry è stata flaggata. Per ogni entry flaggata il daemon eseguire il relativo softIRQ handler, che rappresenta uno specifico bottom-half.
Abbiamo anche la possibilità di costruire una maschera di bit che ci permette di stabilire se un softirq demon che si sveglia nella CPU X può o non può esegurie una data entry della softIRQ table, anche se quest'ultima è stata flaggata. Così facendo siamo in grado di creare affinità tra le softIRQs e i CPU-cores.
1.3 Tasklet
Per ottenere un funzionamento di accodamento di deferred work
simile a quello presente nelle task queues, l'architettura softIRQs
ci offre due bottom-halves, che sono HI_SOFTIRQ e TASKLET_SOFTIRQ ,
che ci permettono di eseguire del lavoro che è stato accodato in
particolari strutture dati.
Le strutture dati che rappresentano del deferred work da eseguire
prendono il nome di tasklet, e sono definite nel file
include/linux/interrupt.h
struct tasklet_struct { struct tasklet_struct *next; unsigned long state; atomic_t count; bool use_callback; union { void (*func)(unsigned long data); void (*callback)(struct tasklet_struct *t); }; unsigned long data; };
Per avere un sistema efficiente e scalabile all'aumentare dei CPU-cores, queste tasklet vengono accodate in liste di tasklets, che possono poi essere rese per-CPU variables. Così facendo ogni CPU-core ha due list di tasklets: una associata alle tasklet con normal priority, e l'altra associata alle tasklet con high priority. Queste per-cpu liste di tasklets vengono gestite dal softirq demon associato a quel CPU-core.
Per non occupare troppo tempo alla CPU-core in cui un softirq demon sta eseguendo, Il kernel, tramite la modifica di alcuni dati condivisi, può dire ad un softirq demon di andare in PREEMPTION. Il softIRQ demon in determinati momenti della sua esecuzione (i.e. printk()), può scegliere di andare a dormire, a seconda dello stato del sistema, anche se rimane ancora del deferred work da fare.
1.4 Tasklet API
Le tasklet possono essere istanziate utilizzando le seguenti macro,
presenti in include/linux/interrupt.h . Generalmente una tasklet è
definita da tre cose: un nome, un puntatore a funzione, e un
parametero.
DECLARE_TASKLET():
DECLARE_TASKLET(tasklet, function, data)DECLARE_TASKLET_DISABLED(): In questo caso la tasklet non viene eseguita fino a quando non viene esplicitamente attivata. Quando il softirq-daemon trova una tasklet disabilitata, non la esegue e non la elimina nemmeno, ma semplicemente la ignora. Questo meccanismo è utilizzato in determinate situazioni per aumentare le performance del sistema.
DECLARE_TASKLET_DISABLED(tasklet, function, data)
Le API di utilizzo delle tasklet sono invece le seguenti:
tasklet_enable():
tasklet_enable(struct tasklet_struct *tasklet);
tasklet_disable(): if the tasklet to be disabled has already begun its execution, wait for it to end.
tasklet_disable(struct tasklet_struct *tasklet);
tasklet_disable_nosynch(): if the tasklet to be disabled has already begun its execution, DO NOT wait for it to end.
tasklet_disable_nosynch(struct tasklet_struct *tasklet);
tasklet_schedule(): used to schedule the tasklet in the normal-priority tasklets queue.
void tasklet_schedule(struct tasklet_struct *tasklet);
tasklet_hi_schedule(): used to schedule the tasklet in the high-priority tasklets queue. This queues the tasklet at the end of the queue.
void tasklet_hi_schedule(struct tasklet_struct *tasklet);
tasklet_hi_schedule_first(): used to schedule the tasklet in the high-priority tasklets queue. This queues the tasklet at the start of the queue. This type of queueing is only available to the high-priority queue, for high-priority tasks.
void tasklet_hi_schedule_first(struct tasklet_struct *tasklet);
tasklet_init(): Utilizzata per inizializzare una struttura
struct tasklet_struct.void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data);
Notiamo che una volta inserita una tasklet tramite queste funzioni, non c'è un modo semplice per eliminare la tasklet dalla coda di tasklets. Non possiamo nemmeno specificare su quale coda di tasklets vogliamo accodare la nostra tasklet, in quanto la scelta si basa sullo specifico CPU-core in cui il nostro codice sta girando.
I tasklets hanno uno livello di schedule simile al livello offerto
da tq_schedule nella architettura delle task queues. É importante
programmare i tasklet in modo tale da non bloccare il thread in
esecuzione.
1.4.1 tasklet_init()
Il codice utilizzato per inizializzare una tasklet è il seguente
void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data) { t->next = NULL; t->state = 0; atomic_set(&t->count, 0); t->func = func; t->data = data; }
2 Work Queues
Anche se l'architettura softIRQ ci ha avvicinato molto ad avere un sistema scalabile per la gestione del deferred work, ci sono ancora una serie di problematiche relative al fatto che nell'architettura softIRQ le tasklet queues sono implicite, e non possono essere esplicitamente manipolate dal programmatore. L'idea è quindi quella di introdurre nuovamente il concetto di task queue esplicita.
Il kernel 2.5.41 ha completamente rimpiazzato l'architettura delle task queues con quella delle work queues.
users of tq_immediate -> tasklets users of tq_timer -> timers directly otherwise -> schedule_work()
Se non ci bastano questi due supporti, possiamo utilizzare il nuovo supporto delle work queues. Le work queues sono code di task che vengono eseguiti da determinati thread, chiamati kworkers. I kworkers sono molti di più dei softirq-demons.
Inizialmente per ogni work queue c'era un kworker associato a quella queue. Questa soluzione però non è scalabile in quanto:
Per ogni thread dobbiamo memorizzare dei meta-dati associati al thread.
Per processare più task su diverse work queues dobbiamo effettuare dei context-switch. Se abbiamo troppe work queues quindi dobbiamo pagare il costo di molti context-switches.
Se un task è bloccante, tutti i task successivi nella stessa work queue rimangono bloccati aspettando il task iniziale. Questo non permette di avere del deferred work bloccante.
2.1 Original Work Queues API
Le API originali offerte dal kernel per interagire con le work sono le seguenti
INIT_WORK(): Macro utilizzata per creare una
struct work_struct.INIT_WORK(&var_name, function-pointer, &data);
schedule_work(): Collega il task (work) ad una work queue di sistema predefinita. Ogni cpu-core ha la sua work queue.
schedule_work(struct work_struct *work);
schedule_work_on(): Collega il task (work) ad una work queue di sistema scelta da noi tramite il param cpu.
schedule_work_on(int cpu, struct work_struct *work);
workqueue_struct(): Crea una work queue. La work queue creata è in realtà una multi-queue, una per ogni CPU-core.
struct workqueue_struct *create_workqueue(const char *name);
create_singlethreaded_workqueue(): Permette di creare una workqueue_struct (one entry per processor) e permette inoltre di flushare la queue tramite un single worker thread. Viene utilizzata quando abbiamo del deferred-work che entra in conflitto per la gestione di risorse.
struct workqueue_struct *create_singlethreaded_workqueue(const char *name);
destroy_workqueue(): Elimina la queue.
void destroy_workqueue(struct workqueue_struct *queue);
queue_work(): Permette di accodare un work in una work queue specifica, e non solo quella predefinita.
int queue_work(struct workqueue_struct *queue, struct work_struct *work);
queue_delayed_work(): Permette di accodare un work in una work queue specifica con un delay di esecuzione specifico.
int queue_delayed_work(struct workqueue_struct *queue, struct work_struct *work, unsigned long delay);
cancel_delayed_work(): Cancella un pending job. Può fallire o no a seconda se il work è stato già runnato o se attualmente è in esecuzione.
int cancel_delayed_work(struct work_struct *work);
flush_workqueue(): Flusha una specifica work queue andando ad eseguire tutti i work all'interno di quella queue.
void flush_workqueue(struct workqueue_struct *queue);
2.2 Work Queue Issues
Le problematiche principali dall'utilizzo delle work queues sono le seguenti:
Proliferation of kernel threads: La prima implementazione delle work queues associata ad ogni work queue un particolare thread. Questo portava ad una serie di problematiche.
Deadlocks: Se il deferred work eseguito non è ben strutturato, ci possono essere problematiche di deadlocks tra diversi work.
Unnecessary context switches: Workqueue threads si contendono tra loro la CPU, andando a creare dei context switch superflui.
2.3 Concurrency Managed Work Queues
Per cercare di risolvere le problematiche delle work queues è stato introdotto un particolare metodo di gestione delle work queues. Con il concurrency managed work queues abbiamo una worker pool di threads che gestistono le work queues.
Quando un thread entra a lavorare su una particolare work queue, aggiorna dei metadati associati alla work queue per indicare che lui sta processando quella particolare work queues. Quando finisce di processare la work queues aggiorna nuovamente i metadati per indicare che è uscito.
Questi metadati vengono utilizzati da ulteriori demoni per capire quanti thread sono disponibili per processare del nuovo deferred work. Così facendo il pool di demoni viene gestito in modo dinamico rispetto al load del deferred work da eseguire.
Il deferred work tramite concurrency managed workqueues deve anche essere gestito bene da parte del programmatore. In particolare, se devo eseguire due task, in cui in un task prendo una risorsa e in un'altro task la rilascio, è meglio inserire la funzione di acquisizione della risorsa in una coda, e quella di rilascio in un'altra.
Possiamo inoltre chiedere che ci sia sempre un thread in grado di eseguire deferred work posto in work queues.
Il mapping tra le vecchie API e le nuove API è il seguente
create_workqueue(name) -> alloc_workqueue(name, WQ_MEM_RECLAIM, 1) create_singlethread_workqueue(name) -> alloc_ordered_workqueue(name, WQ_MEM_RECLAIM)
3 container_of() macro
La container_of() macro viene utilizzata quando lavoriamo con le
tasklets o le workqueues. In generale viene utilizzata ogni volta
che riceviamo pointer di strutture contenute in strutture ancora più
grandi e complesse e vogliamo sapere qual'è il pointer alla
struttura originale.
Consideriamo la seguente struttura
struct object { char first_member; char second_member; char third_member; struct list_head list; };
e supponiamo di avere un pointer all'elemento list . Tramite
l'utilizzo della macro container_of(ptr, type, member) siamo in
grado di ottenere l'indirizzo di base della struttura contenitore.
struct object testObject = {}; unsigned long list_ptr = &testObject.list; unsigned long base_ptr = container_of(list_ptr, struct object, list);
4 Running Examples
4.1 RE: TASKLET
In questo esempio vediamo l'utilizzo delle tasklet tramite la softIRQ architecture.
Il codice a seguire installa la system call sys_put_work() nella
syscall table. Ogni volta che viene chiamata, tale funzione prende
in input un codice numerico e crea una packed_task che wrappa una
tasklet insieme ad altri dati. La tasklet viene creata tramite la
funzione tasklet_init() , e ha come bottom-half la funzione
audit() . La tasklet viene poi inserita in una apposita tasklet
queue tramite la funzione tasklet_schedule.
La struttura dati utilizzata è la seguente
typedef struct _packed_struct { void* buffer; long code; struct tasklet_struct the_tasklet; } packed_struct;
Il codice top-half invece è il seguente
// Sys call that represents the top-half code for managing an // interrupt. asmlinkage long sys_put_work(int request_code) { packed_trask *the_task; // IMPORTANT: We need to lock this module in memory, since the // bottom-half code that will be put in the tasklet queue is found // in the module itself. if(!try_module_get(THIS_MODULE)) return -1; // Non blocking memory allocation the_task = kzalloc(sizeof(packed_struct), GFP_ATOMIC); if(the_task == NULL) { module_put(THIS_MODULE); return -1; } the_task->buffer = the_task; the_task->code = request_code; // Create and schedule the tasklet in the tasklet queue of the // CPU-core we're running on. tasklet_init(&the_task->the_tasklet, audit, (unsigned long)the_task); tasklet_schedule(&the_task->the_tasklet); return 0; }
Infine, il codice bottom-up non fa altro che stampare il codice numerico contenuto nella struttura dati creata dal top-half ed è il seguente
void audit(unsigned long data) { // Bottom-half code packed_struct *the_task = (_packed_struct*)data; printk("%s: Bottom-half executed with numerical code: %d\n", MODNAME, (int)the_task->code); printk("%s: Container of task is at %p\n", container_of(data, packed_task, buffer)); kfree((void*) data); // No more locking for this syscall execution module_put(THIS_MODULE); }
4.2 RE: WORK-QUEUS
Questo esempio è simile a quello precedente, ma al posto di utilizzare le tasklet utilizzamo le work_queues. Questo ci permette di scegliere il CPU-core in cui andiamo a inserire il task da eseguire.
Sia la struttura dati che il bottom-half è la stesso di prima. L'unica cosa che cambia è il top-half, che questa volta utilizza una work queue piuttosto che una tasklet.
asmlinkage long sys_put_work(int core, int request_code) { packed_work *the_task; // IMPORTANT: We need to lock this module in memory, since the // bottom-half code that will be put in the tasklet queue is found // in the module itself. if(!try_module_get(THIS_MODULE)) return -1; // Non-blocking memory allocation. the_task = kzalloc(sizeof(packed_struct), GFP_ATOMIC); if(the_task == NULL) { module_put(THIS_MODULE); return -1 } the_task->buffer = the_task; the_task->code = request_code; __INIT_WORK(&(the_task->the_work), (void*)audit, &(the_task->the_work)); schedule_work_on(core, &the_task->the_work); return 0; }