AOS - 24 - KERNEL TASK MANAGEMENT III
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 3/7
Argomenti:
Timer Interrupts
LAPIC-T Timer Interrupts
High Resolution (HR) Timers
Preemption Requests
TCB (intro)
Runqueue and Waitqueues (intro)
Sleep/Wait Kernel Services (intro)
Introduzione: In questa lezione abbiamo discusso degli interrupts da timers, di come il tempo è misurato in x86, e abbiamo discusso del concetto di preemption request, e di quando un thread in esecuzione viene effettivamente tolto dalla CPU.
1 Timer Interrupts
La gestione del time-sharing nelle macchine moderne viene effettuato tramite l'utilizzo di timers e degli interrupt da timers. Gli interrupt da timers, come abbiamo visto nelle ultime due lezioni, non possono essere gestiti in modo asincrono per motivi di scalabilità in ambienti multi-core.
Quando arriva un interrupt da timer nel contesto del time-sharing non viene quindi effettuato immediatamente il context-switch. Quello che viene effettuato immediatamente durante l'esecuzione del thread, ovvero in modo asincrono, è il cambiamento di una condizione all'interno del kernel che dice al thread di chiamare lo scheduler della CPU. Lo scheduler verrà poi effettivamente chiamato quando, in modo sincrono, il thread in esecuzione controlla la condizione per risvegliare lo scheduler, capisce che è cambiata, e lo va a chiamare.
Gli interrupt da timer vengono quindi gestiti sempre con uno schema top/bottom half, dove il top si fa carico di alterare la condizione di chiamata dello scheduler, e il bottom si fa carico di chiamare effettivamente lo scheduler.
Notiamo che lo schema top/bottom half nel contesto dei context-switch non vale se facciamo context-switch a causa di una preemption. La preemption è la situazione in cui il thread in esecuzione controlla metadati a lui associati e modificati da altri componenti del kernel che gli dicono che c'è una linea di preemption standing. La preemption permette quindi di gestire quei casi in cui c'è qualcosa di urgente da fare, e il thread in esecuzione sul CPU-core deve essere cambiato per qualcosa di diverso dal tempo passato in esecuzione. Nei casi di preemption lo scheduler è chiamato in modo diretto.
1.1 Timer Interrupts and CPU Reschedules
Se guardiamo una timeline di esecuzione di un thread, troviamo che ogni tot di tempo il thread riceve degli interrupt da timer. Questi interrupt da timer vanno a decrementare la variabile che indica il tempo residuo per il thread in esecuzione. Ad un certo punto la variabile assume il valore di \(0\), e dal quel momento, appena il thread esegue il prossimo controllo sul valore della variabile, si accorge che è \(0\) e chiama lo scheduler. Questi timer interrupts prendono il nome di ticks.
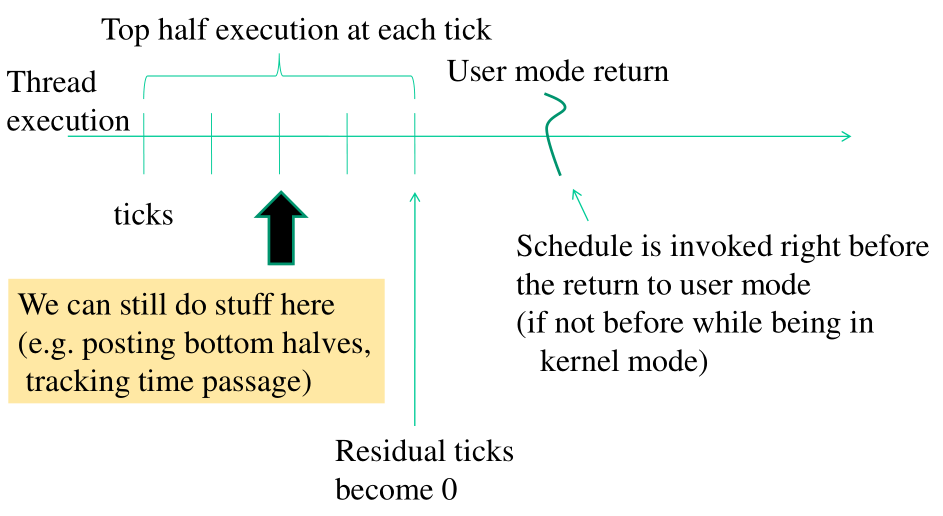
1.2 Disable Timer Interrupts on Demand
Notiamo che disattivare gli interrupt da timers non è una buona soluzione per eseguire una sezione critica di codice del kernel che non vogliamo sia de-schedulata. Se disabilitiamo gli interrupts da timer infatti come prima cosa non ci ricordiamo il passaggio del tempo, e questo ha le seguenti conseguenze:
Perdiamo la possibilità di schedulare bottom halves con il passare del tempo.
Perdiamo la possibilità di controllare l'avanzamento dal tempo a grana fine, e quindi incontriamo grosse difficoltà a coordinare CPU-cores diversi.
Avere la possibilità di conoscere il passaggio del tempo è quindi fondamentale in un sistema multi-core. L'unico caso in cui possiamo pensare di disattivare il timer è quando lavoriamo con sistemi con CPU a single-core.
2 Kernel Execution and Busy-Waiting
Quando lavoriamo in kernel mode, dobbiamo stare attenti a come facciamo del busy-waiting. Supponiamo di avere il seguente codice
while (!condition) { // do stuff }
Anche se è vero che quando questo codice gira il sistema riceverà gli interrupt da timer, e quindi il top-half verrà eseguito, e quindi la variabile che conta il tempo allocato per il thread ad un certo punto assume il valore \(0\), il bottom-half non viene mai eseguito: non controlliamo mai il valore della variabile, e quindi, finché la condizione non è verificata, non andiamo mai a chiamare lo scheduler. Se poi la condizione può essere soddisfatta solamente da altri thread tramite il time-sharing, allora il thread in esecuzione non lascerà mai la CPU.
Un esempio di questo lo abbiamo visto nel running example
CROSS-RING-DATA-MOVE/message-exchange-service-rcu . In particolare
avevamo che il singolo writer nello schema RCU doveva aspettare che
tutti i readers si muovevano dal vecchio buffer al nuovo buffer. Per
evitare le problematiche menzionate prima quindi andavamo a far
dormire il writer con una usleep() .
while(rcu_message->standing[old_epoch] > 0 ){ __sync_fetch_and_add(&rcu_wait_cycles,1); usleep_range(5,10); // call scheduler, if needed. }
Il busy-waiting viene comunque utilizzato all'interno del kernel quando utilizziamo tecniche di sincronizzazione basate su spin-lock. Le sezioni critiche che vengono protette da spin-lock sono però brevi, predicibili, e il thread in esecuzione non può essere de-schedulato.
Dobbiamo stare attenti a tutte quelle situazioni di busy-waiting in cui il thread che può rendere vera la condizione nel time-sharing viene portato fuori dalla CPU per via di operazioni bloccanti.
3 How Time is Measured in x86
Su x86 abbiamo tre principali componenti che vengono utilizzati per misurare il tempo. Alcuni di questi componenti mandano degli interrupt, mentre altri no. I componenti sono:
Time Stamp Counter (TSC): Conta il numero di cicli di clock della CPU, ed è accessibile tramite l'istruzione
rdtsc. Non manda interrupt.Local APIC TIMER (LAPTIC_T): Utilizzato per il time-sharing, ovvero per generare i timer interrupt che vanno a diminuire i ticks relativi al thread attualmente attivo sul processore. Può essere programmato per mandare interrupt one-shot o periodici, con la granularità dei millisecondi.
In Linux questo timer è configurato con la granularita che va da \(1\) (caso pochi CPU-core) a \(4\) millisecondi (caso tanti CPU-core). Il numero di cicli macchina per configurare un valore su questo timer è significativo. Tipicamente a start-up del sistema operativo questo timer viene configurato una volta per tutte e comincia a lavorare con cadenza periodica.
High Precision Event Timer (HPET): Suite di timers introdotta nelle più recenti versioni dell'architettura x86. Viene utilizzata per programmare timers con una elevata precisione, sulla granularità dei nanosecondi. Questo oggetto è facilmente programmabile, e quindi può anche essere utilizzato in modalità one-shot.
3.1 LAPIC-T Timer Interrupts
Abbiamo una gestione diversa di questo interrupt a seconda dell'architettura di gestione del deferred work per gli interrupts, dove
old style <-> task queue new style <-> softIRQ
3.1.1 old-style (task queus)
Se lavoriamo con le task queues, appena arriva un interrupt dal LAPIC-T timer vengono eseguite le seguenti operazioni:
Viene immediatamente flaggata la task-queue
tq_timerper dire che è pronta per essere flushata (ovvero eseguita).Incrementiamo il valore della variabile globale unsigned long
jiffies(dichiarata inkernel/timer.c), che tiene conto del numero di ticks che sono passati dal momento in cui abbiamo attivato la gestione dei timer interrupts.Lavoro minimale relativo al time-passage.
Controlla se lo scheduler della CPU deve essere attivato. Se deve essere attivato, flagga positivamente il bit
need_reschednella variabile presente nelTCB(Thread Control Block) del thread in esecuzione.
Ogni volta che finalizziamo qualche task all'interno del kernel
viene controllata la variabile/bit need_resched all'interno del
TCB del thread in esecuzione. Se il check è positivo, allora viene
chiamata la funzione schedule() , definito nel file kernel/sched.c
(o /kernel/sched/core.c ), che chiama l'effettivo scheduler.
Il pezzo di codice è il seguente, deifnito in linux/kernel/timer.c
// Top-half void do_timer(struct pt_regs *regs) { // Inizialmente si è trascurata la possibilità di perdere dei // jiffies nei sistemi multi-core. (*(unsigned long *)&jiffies)++; #ifndef CONFIG_SMP /* SMP process accounting uses the local APIC timer */ update_process_times(user_mode(regs)); #endif mark_bh(TIMER_BH); if (TQ_ACTIVE(tq_timer)) mark_bh(TQUEUE_BH); } // Bottom-half void timer_bh(void) { update_times(); run_timer_list(); // takes care of any timer-related action }
3.1.2 new-style (softIRQ)
__visible void __irq_entry smp_apic_timer_interrupt(struct pt_regs *regs) { struct pt_regs *old_regs = set_irq_regs(regs); /* * NOTE! We'd better ACK the irq immediately, * because timer handling can be slow. * * update_process_times() expects us to have done irq_enter(). * Besides, if we don't timer interrupts ignore the global * interrupt lock, which is the WrongThing (tm) to do. */ entering_ack_irq(); // Flags the current thread for reschedule, if needed. // // Raise the flag of TIMER_SOFTIRQ, thus waking up the softirq-demon // that will process the associated activities. // // NOTE: It can happen that even if the thread in execution does not // spend all of his ticks, by waking up the softirq-demon, since the // softirq-demon's priority should be high, we may raise a // preemption request and, by checking any standing preemption // lines, we may thus pass control to the softirq-demon. local_apic_timer_interrupt(); exiting_irq(); set_irq_regs(old_regs); }
3.2 High Resolution (HR) Timers
Tramite gli HR timers siamo in grado di mandare degli interrupt temporizzati, eventualmente aperiodici, durante l'evoluzione di uno specifico thread.
Quando ci arriva un interrupt da timer da un HR timer, andiamo a fare le seguenti cose:
Raise the
HRTIMER_SOFTIRQflag in the SOFTIRQ_table;Program the next HR timer interrupt based on a log of requests;
Wake up the relative demon and raise a preemption request;
3.2.1 usleep()
La usleep() ci permette di andare a dormire con una granularità
dei microsecondi (più bassa dei millisecondi). Per spingerci a
questa granularità necessitiamo quindi dell'utilizzo degli HR
timers.
In particolare, le azioni eseguite dalla usleep() sono le
seguenti:
Il thread chiamante esegue una software trap per andare lato kernel;
Il kernel mette una richiesta HR-timer all'interno del log ed eventualmente riprogramma l'HR-timer.
Lo scheduler viene chiamato per passare il controllo a qualche altro thread.
Quando scade la richiesta inserita e viene generato il relativo interrupt da HR-timer, il thread in esecuzione viene tolto il prima possibile e viene rimesso il thread chiamante originario.
Per implementare un nostro servizio di usleep() necessitiamo di
sapere come bloccare l'esecuzione di un thread all'interno del
kernel.
3.2.2 HR-Timer Kernel API
Le API offernte dal kernel per gestire gli high-resolution timers sono le seguenti
hrtimer_init(): Permette di creare una hrtimer struct specificando una struttura hrtimer (che contiene a sua volta un function poiner e dei dati), il meccanismo di clocking, e come viene misurato il tempo (in modo relativo o assoluto).
void hrtimer_init(struct hrtimer *timer, clockid_t which_clock, enum hrtimer_mode mode);
hrtimer_start(): Used to start the timer by inserting the HR-timer request in the appropriate log. Se il valore di ritorno è HRTIMER_RESTART, allora la richiesta viene effettuta una sola volta. Se invece il valore è HRTIMER_NORESTART, allora la richiesta viene mantenuta dal log e viene eseguita in modo periodico.
int hrtimer_start(struct hrtimer *timer, ktime_t time, enum hrtimer_mode mode);
hrtimer_cancel(): Waits if the target function is already running.
int hrtimer_cancel(struct hrtimer *timer);
hrtimer_try_to_cancel(): Does not wait if the target function is already running.
int hrtimer_try_to_cancel(struct hrtimer *timer);
Per quanto riguarda la funzione hrtimer_start() , notiamo che essa
necessita di passare una struct ktimer_t . Questa struct serve per
specificare il tempo del timer, e può essere inizializzata come segue
ktime_t kt; kt = ktime_set(secs, nanosecs);
4 Preemption Request
Durante l'esecuzione di un thread vengono gestiti i top-half degli
interrupt. Questi top-half possono fare varie cose, tra cui indicare
il fatto che il thread in esecuzione deve andare in preemption
tramite il flag di una variabile del TCB. Il flag di preemption
viene poi controllato in determinati punti dell'esecuzione del
thread, come print() e ret_from_sys_call() , che poossono
eventualmente chiamare lo scheduler.
Tramite l'utilizzo di determinate API è possibile in modo trasparente scrivere dei blocchi di codice che ci permettono di disabilitare la preemption. Così facendo quindi siamo sicuri che, quando facciamo il preemption-check, il thread non attiverà lo scheduler.
Per implementare questo meccanismo di disattivazione della preemption, ad ogni thread è associato un contatore, che prende il nome di preemption-counter, memorizzato nel TCB del thread. Se durante l'esecuzione del thread il valore del preemption counter relativo a quel thread non è 0, allora il controllo sulla preemption non porterà alla chiamata dello scheduler.
4.1 Preemption API
Le API offerte dal kernel per la configurazione della preemption sono le seguenti:
preempt_enable(): Decrement the preemmpt counter.
preempt_enable();preempt_disable(): Increment the preemmpt counter.
preempt_disable();preempt_enable_no_resched(): Decrement, but not immediately preempt.
preempt_enable_no_resched();preemt_check_resched(): If needed, reschedule
preemt_check_resched();preempt_count(): return the preempt counter
preempt_count();
4.2 Per-CPU Variables
Le attività che devono necessariamente essere non-preemptable sono tutte le attività in cui andiamo a fare cose specifiche al CPU-core in cui stiamo eseguendo. Se siamo preemptable infatti, possiamo essere deschedulati, e senza meccanismi di affinità, possiamo essere potenzialmente schedulati in CPU-core diversi.
Attività del genere sono quindi le attività che manipolano delle per-CPU variables.
Tramite l'utilizzo delle get_cpu_var() e put_cpu_var() eravamo in
grado di disabilitare e riabilitare la preemption. Da notare che la
macro read per leggere una per-CPU variable può essere utilizzata
solo se prima c'è stata una get_cpu_var() .
NOTA BENE: Questo meccanismo deve essere utilizzato in modo corretto dal programmatore. In particolare, se il programmatore chiama un servizio bloccante all'interno del blocco get/put, veniamo de-schedulati dalo scheduler, e quindi possiamo potenzialmente andare in esecuzione su un'altra CPU. Dobbiamo quindi essere sicuri che le funzioni presenti nel blocco get/put, siano funzioni non-bloccanti che fanno solamente il check sulla preemption.
5 Thread Control Block (TCB)
Il thread control block (TCB) è una struttura dati che contiene informazioni relative ad un dato thread. Nel TCB ci sono informazioni su:
Schedulability e controllo dell'execution flow: Le informazioni sulla schedulability sono rappresentate da flags che indicano se il thread può essere scelto per riprendere l'esecuzione.
Controllo dell'execution flow: Le informazioni sul controllo dell'execution flow sono rappresentate dai valori dei registri
CP,SP, etc.Collegamenti con altri sottosistemi di linux: Ogni TCB è collegato ad altri sottosistemi, tra cui la memory map, che rappresenta la visione della memoria, e il virtual file system.
Thread multipli possono condividere delle informazioni nei rispettivi TCB tramite l'utilizzo di pointers.
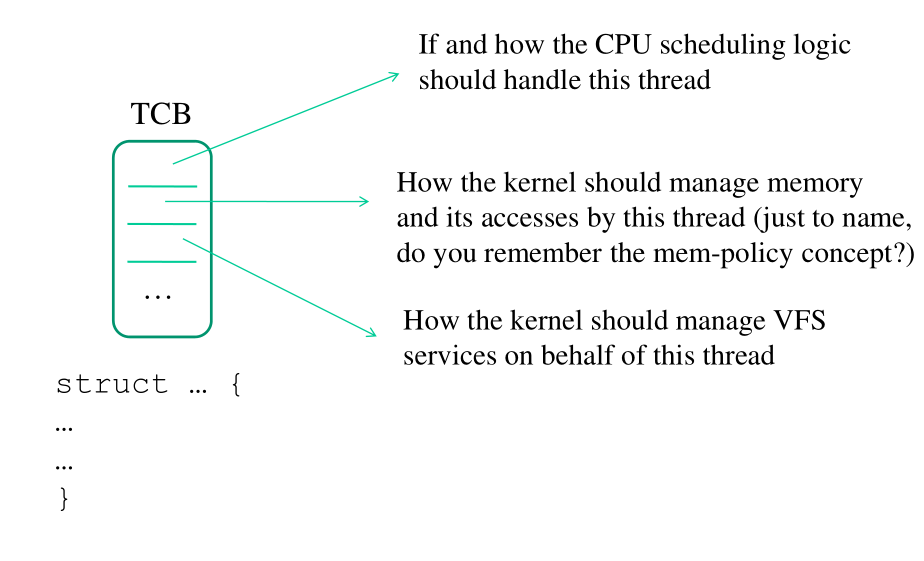
5.1 CPU-Dispatchability
Il concetto di CPU-dispatchability per un thread viene utilizzato per rappresentare il fatto che in un certo momento lo scheduler può prendere il TCB relativo al thread e portare il thread in esecuzione.
La CPU-dispatchability non viene gestita dalla logica dello scheduler. Esiste un altro meccanismo che ci permette di stabilire se un dato TCB può essere visibile (CPU-dispatchable), o non-visibile (not CPU-dispatchable) dallo scheduler.
La logica dello scheduler quindi permette solo di selezionare i thread che sono già CPU-dispatchable.
6 Runqueue and Waitqueues
Per definizione un thread è CPU-dispatchable se e solo se il suo TCB è incluso in una struttura dati, che generalmente è una lista. Questa struttura dati prende il nome di runqueue. Tutti i threads che non sono CPU-dispatchable sono memorizzati in strutture dati ulteriori, che prendono il nome di waitqueues.
Lo scheduler quindi si concentra solamente sulla runqueue, e non considera mai i TCB salvati nelle waitqueues. Tipicamente abbiamo una sola runqueue, mentre possiamo avere più waitqueues. Ad esempio possiamo avere una waitqueue per thread.
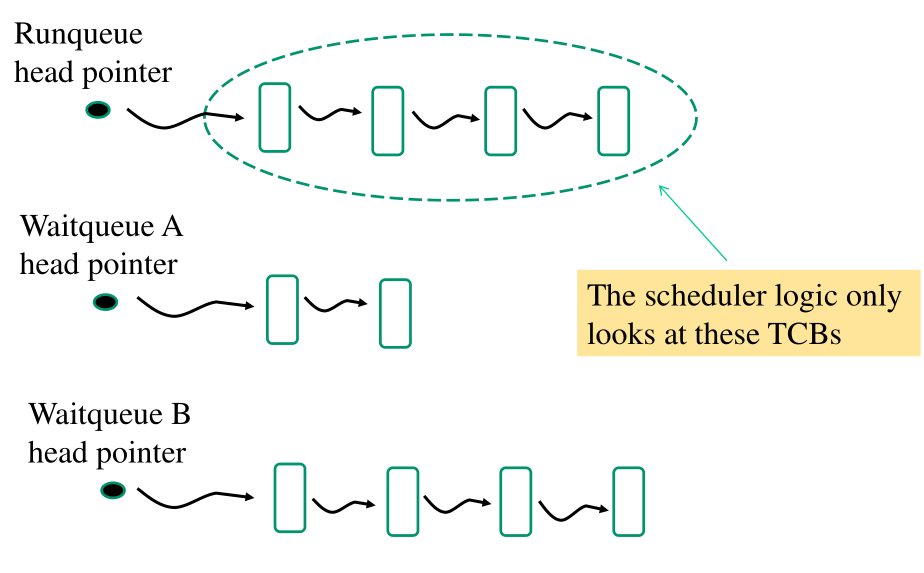
La manipolazione di queste code porta una serie di problemi di concorrenza, che sono risolti da funzioni di sincronizzazione estremamente efficienti. Per semplificare la vita ai programmatori di sistema, queste funzionalità sono nascoste tramite determinate API. Queste API permettono di far interagire tra loro la scheduler logic e i blocking services.
Quando un thread chiama un blocking service, il TCB a lui associato deve essere spostato dalla runqueue ad una wait queues, a seconda del particolare servizio bloccante. Come facciamo quindi ad escludere il TCB del thread che ha chiamato il servizio bloccante dalla logica di selezione dello scheduler? Per risolvere questa problematica un servizio bloccante necessita la presenza di un kernel level sleep/wait service.
7 Sleep/Wait Kernel Services
Gli sleep/wait services sono le API per gestire le sleep/wait queues. Questi servizi utilizzano le informazioni contenute nella TCB, assieme alla logica dello scheduler, per capire qual'è il comportamento reale che dovrà subire un thread che invoca un servizio bloccante.
Abbiamo due possibili outcome per l'invocazione di uno sleep/wait service:
Il TCB del thread che ha chiamato il servizio bloccante viene tolto dalla runqueue dallo scheduler prima dell'inizio del processo di selezione del prossimo thread da eseguire.
Il TCB del thread che ha chiamato il servizio bloccante non viene tolto dalla runqueue. Questo outcome può succedere quando, dopo aver chiamato uno sleep/wait service, asincronamente, un altro thread in esecuzione fa qualcosa per aggiornare il TCB del thread originale.
Notiamo che il TCB di un thread che ha chiamato uno sleep/wait service viene spostato comunque su una waitqueue, anche se poi lo sleep/wait service non porta il TCB ad essere eliminato dalla runqueue.
La timeline di uno sleep/wait service è quindi così composta:

In dettaglio:
Si linka il TCB dell'invoking thread su qualche waitqueue.
Si flagga il TCB del thread come "sleep".
Si chiama lo scheduler.
Dopo essere stati risvegliati, la tail dello sleep/wait service si preoccupa di eliminare il TCB dell'invoking thread dalla wait queue.