AOS - 25 - KERNEL TASK MANAGEMENT IV
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 4/7
Argomenti:
TCB Structure
TCB Allocation
Virtually Mapped Stacks
Run Queues
Wait Queues
Wait Event Queues
Introduzione: Nella scorsa lezione avevamo introddo gli sleep/wait services, ovvero i servizi bloccanti. Questi servizi utilizzano le wait-queues per bloccare i thread. In questa lezione vediamo più in dettaglio la gestione del TCB da parte del kernel e il funzionamento delle wait queues.
1 Thread Control Block (TCB)
Nel kernel non c'è un meccanismo di TLS . Per avere della memoria per
thread dobbiamo quindi utilizzare delle strutture dati allocate per
ogni thread, come il Thread Control Block ( TCB ).
L'utilizzo principale del TCB è quello di salvare lo stato della CPU quando il thread viene rimosso dalla CPU per passare ad un'altra CPU o andare in wait/sleep. Quando il thread riprende il controllo in CPU, le informazioni sullo stato della CPU per il particolare thread vengono ripescate dal TCB del thread.
Le operazioni necessarie per eseguire un context-switch non sono atomiche. Possiamo però individuare un singolo punto in cui passiamo dall'esecuzione di un thread all'esecuzione di un altro thread. Questo singolo punto è individuato dal cambio della stack area livello kernel per il particolare thread. Lo stack switch rappresenta quindi il momento in cui cambiamo il contesto di esecuzione.
L'idea è quindi quella di accoppiare il cambiamento dello stack livello kernel al cambiamento del TCB.
1.1 TCB Structure
La struttura del thread control block è definita nel file
include/linux/sched.h . I campi più importanti sono riportati a
seguire, anche se notiamo che nelle versioni più recenti sono state
modificati qualche campi e aggiunti degli altri.
struct task_struct { // Variabile che può essere modificata sia in modo sincrono sia in // modo asincrono. volatile long state; // Pointer to the memory view of the thread. struct mm_struct *mm; pid_t pid; // Thread ID // Process group, all thread's of a process share the same group. In // recent version its called tgid. pid_t pgrp; //... // Modified by top-half of timer interrupts. Checked by the thread // at given conciliation points during execution. // // In modern releases this has become // a bit inside a bitmask. volatile long need_resched; //... // Number of residual LAPIC-T ticks. long counter; // niceness: higher level means less ticks. long nice; unsigned long policy; }
1.2 TCB Allocation
Per gestire un thread necessitiamo di due buffer: un TCB e una stack area livello kernel. A seconda della versione del kernel abbiamo una gestione diversa del TCB.
1.2.1 TCB in kernel < 2.6
Per i kernel fino al 2.6 i buffer necessari per la gestione di un thread erano rappresentati da due pagine fisiche (frames), allocate da un buddy system, e quindi continue sia in memoria fisica che in memoria logica tramite il direct mapping. In questo schema il TCB era embeddato nella parte iniziale dello stack.
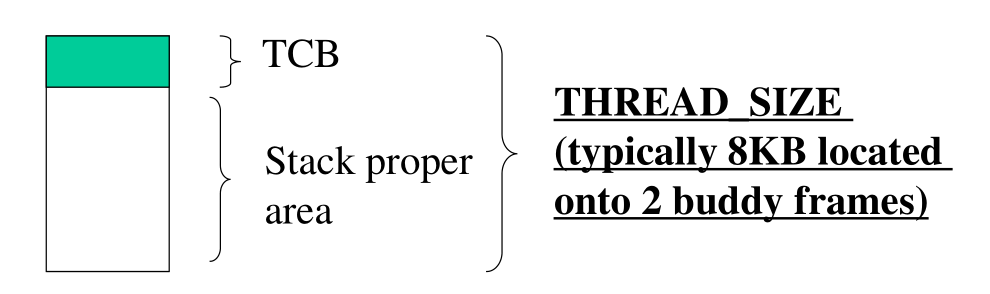
I vantaggi di questo schema sono:
Con un'unica chiamata al buddy allocator, sono in grado di allocare sia il TCB che lo stack.
Ho una regola molto stretta tra gli indirizzi di memoria dello stack e l'indirizzo iniziale del TCB. Infatti, dato che mi muovo in una zona di memoria allocata dal buddy system, e quindi allineata agli 8KB, mi basta mascherare gli ultimi 13 bit dello stack pointer per ottenere l'indirizzo del TCB. Questo segue dal fatto che con 13 bits sono in grado di rappresentare 8KB in quanto
\[8 \text{KB} = 2^3 \cdot 2^{10} \text{B} = 2^{13} \text{B}\]
Addr of TCB | xxxx10000000000000 ... | addr on stack | xxxx1_____________ ... | end stack | addr | xxxx20000000000000
Gli svantaggi di questo schema arivano quando cerchiamo di aggiungere campi alla struttura del TCB. In questo approccio infatti per aumentare il size del TCB dobbiamo necessariamente diminuire il size della stack area. Chiedere più pagine al buddy system poi potrebbe creare dei problemi di frammentazione, in quanto andremmo a raddoppiare la memoria già presente.
La dichiarazione della task area nel kernel 2.4.37 è la seguente.
union task_union { struct task_struct task; unsigned long stack[INIT_TASK_SIZE/sizeof(long)]; }
Notiamo l'utilizzo della union , che ci permette di vedere lo
stesso segmento di memoria in due modi differenti.
1.2.2 TCB in 2.6 <= kernel <= 4.8
Per risolvere i problemi menzionati prima si è quindi pensato di offrire una maggiore separazione in memoria tra il TCB e la kernel stack area del thread. Per fare questo si procede in due passi:
Si alloca una zona di memoria separata per il TCB;
Si inserisce in cima alla stack area per il thread un puntatore alla zona di memoria contenente il TCB. Questa zona di memoria prende il nome di
thread_info.

Questo modo di procedere offre una flessibilità maggiore nell'espandere la TCB o la stack area, mantenendo comunque i vantaggi menzionati prima di poter accedere facilmente alla TCB. Detto questo, si ha la necessità di effettuare due allocazioni diverse.
La struttura della thread_info nel kernel 3.19 è riportata a
seguire:
struct thread_info { struct task_struct *task; // pointer to TCB //... int saved_preempt_count; // preemption counter per thread // ... }
La taglia che definisce la grandezza della stack area per il
thread può essere gestita tramite delle macro definita in
arch/x86/include/asm/page_64_types.h
#define THREAD_SIZE_ORDER 2 #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
1.3 Current Macro
La macro current è utilizzata per ritornare l'indirizzo di memoria
del TCB attualmente in esecuzione sul CPU-core. Questa macro si
basa sul fatto che le pagine di memoria del kernel in cui sono
collocate le informazioni relative alla TCB sono allineate in
memoria tramite il buddy allocator. Dato che il calcolo della macro
current dipende dallo stack pointer del thread, un cambiamento di
stack pointer porta anche al cambiamento nella risoluzione della
macro current.
Il modo in cui viene calcolato l'indirizzo dipende dalla versione del kernel utilizzata:
kernel <= 2.6 (old style): Si mascherano i primi \(13\) bit per ottenere l'indirizzo iniziale delle pagine allocate, in cui è presente il TCB.
2.6 < kernel < 4.9 (new style): Si mascherano i primi 13 bit per ottenere l'indirizzo iniziale delle pagine allocate, in cui è presente la struttura
thread_info. Si utilizza il puntatore salvato nel campo task della struttura thread_info per accedere al TCB.kernel >= 4.9 (very new style): current non è più una macro ma è un puntatore che punta ad una per-CPU memory. Il puntatore viene aggiornato ogni volta che un CPU-reschedule viene eseguito. In questo modo non necessitiamo di allineare in memoria la stack kernel utilizzata per il thread.
struct task_struct; DECLARE_PER_CPU(struct task_struct *, current_task); static __always_inline struct task_struct *get_current(void) { return this_cpu_read_stable(current_task) } #define current get_current()
1.4 Thread States
Il campo state della struttura TCB mantiene informazioni sullo
stato corrent del processo/thread. I valori del campo state sono
definiti in include/linux/sched.h e sono i seguenti
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define TASK_ZOMBIE 4
Tutti i TCB che sono memorizzati nella run-queue devono mantenere
il valore TASK_RUNNING .
2 Virtually Mapped Stacks
Questo tipo di modalità di allocazione dello stack offre maggiore
flessibilità e protezione nei casi di stack overflow. L'idea in
particolare è quella di utilizzare una vmalloc() per allocare la
memoria da utilizzare per lo stack.
Le pagine logiche che circondano le pagine in cui è stata allocata la stack vengono poi de-mappate, per cercare di bloccare eventuali buffer overflows.
3 Run Queue (kernel 2.4)
Nel kernel 2.4 la run queue è un array di pointers, un pointer per
ogni CPU. Tale struttura è definita nel file kernel/sched.c
struct task_struct * init_tasks[NR_CPUS] = {&init_task, }
Anche se abbiamo un pointer per ogni CPU però, nel kernel 2.4 questi pointers puntano tutti alla stessa lista. La run queue contiene quindi una lista di TCBs. Il TCB dell'idle process è rappresentato dalla variabile init_task. Esistono poi delle variabili statiche che puntano al primo e ultimo elemento della runqueue.
La funzione schedule() viene utilizzata per decidere il prossimo
thread da mandare in esecuzione. Per fare questo viene scansionata
la runqueue.
4 Wait Queues (kernel 2.4)
I TCBs dei vari threads possono essere memorizzati in delle liste chiamate waitqueues. Quando il TCB di un thread è inserito in una di queste waitqueues, e non nella runqueue, lo scheduler non lo guarda, e quindi il thread non andrà mai in esecuzione.
4.1 Wait Queues APIs
É possibile definire una wait queue tramite la seguente macro,
definita in include/linux/wait.h
DECLARE_WAIT_QUEUE_HEAD(queue)
Per utilizazare le wait queues il kernel poi offre le seguenti APIs
Sleep APIs:
interruptible_sleep_on(): The TCB of the calling thread is no more scanned by the scheduler untill it is dequeued or a signal kills the process/thread. Being sleep interruptible means that the TCB can be hit by a signal, and thus can be woken up by a signal.
void interruptible_sleep_on(wait_queue_head_t *q);
sleep_on(): In this case we go to sleep and signals are don't care events.
void sleep_on(wait_queue_head_t *q);
interruptible_sleep_on_timeout():
void interruptible_sleep_on_timeout(wait_queue_head_t *q, long timeout);
sleep_on_timeout(): time here is measured in
jiffies.void sleep_on_timeout(wait_queue_head_t *q, long timeout);
Wake APIs:
wake_up(): wake up all process that were sleeping in a given wait-queue
void wake_up(wait_queue_head_t *q);
wake_up_interruptible(): wake up all process that were sleeping in a given wait-queue and that were marked as interruptible.
void wake_up_interruptible(wait_queue_head_t *q);
wake_up(): wake up a specific thread whose TCB is pointed by p.
void wake_up(struct task_struct *p);
Notiamo che le API per la gestione del wake-up o è poco selettiva, o è estremamente selettiva.
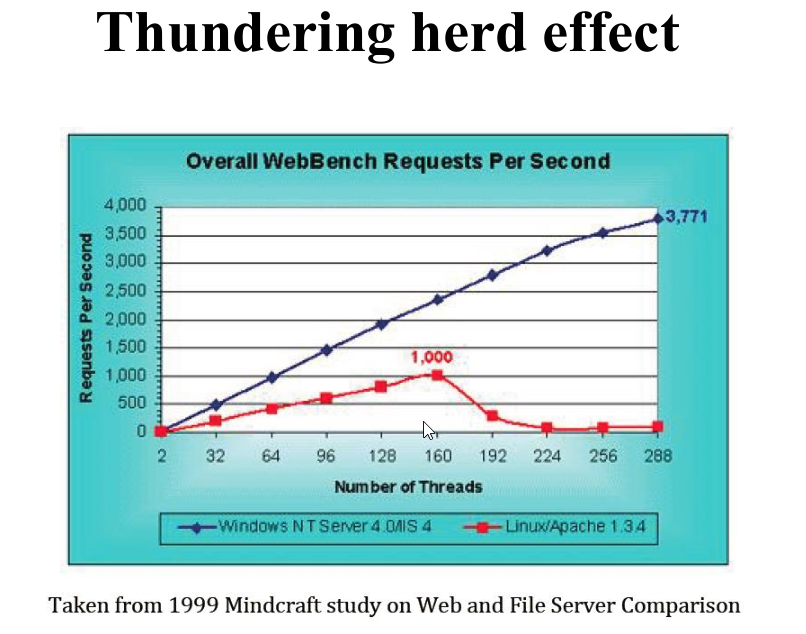
4.2 Thundering Herd Effect
Il thundering herd effect succede quando devo risvegliare tutti i thread che si trovano in una data wait queue solo per farne accedere uno alla risorsa e far bloccare nuovamente tutti gli altri. In questo caso molto tempo della CPU viene investito solo per risvegliare e addormentare i vari thread.
Un esempio documentato di questo effetto è stato studiato da Mindcraft sul comportamento del Web servers.
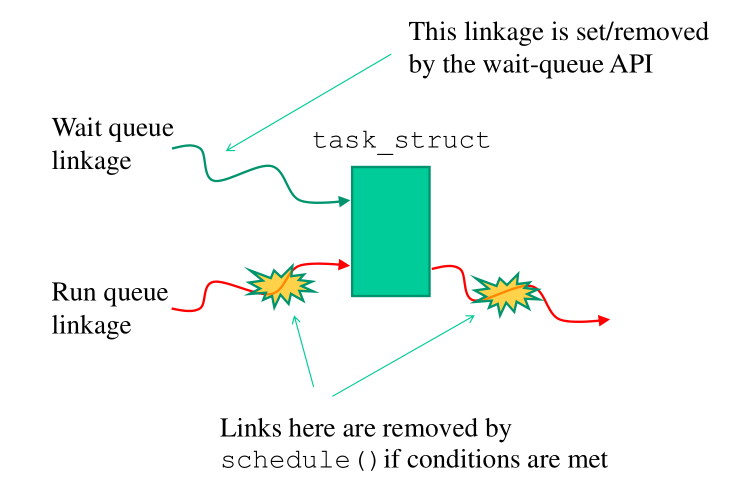
4.3 Wait Queues and TCB Linkage Dynamics
Le APIs delle waitqueues devono anche preoccuparsi di togliere il TCB dalla runqueue una volta che si è ritornati dalla funzione di schedule().
In particolare abbiamo la seguent dinamica per il linking/unlinking dei TCB nella runqueue e nelle varie waitqueues.
5 Wait Event Queues (5.x style)
Per risolvere il thundering effect provocato dall'utilizzo delle wait queues sono state introdotte le wait event queues, che permettono di specificare sia in quale wait queue vogliamo andare a dormire, e sia la condizione da verificare per poterci risvegliare.
Tramite le wait event queues due thread diversi possono andare a dormire nella stessa wait queues andando però a specificare due condizioni di risveglio diverse. Così facendo possiamo avere che uno si risveglia mentre l'altro no.
Le APIs per la gestione delle wait event queues sono le seguenti:
wait_event():
wait_event(wq, condition);wait_event_timeout(): can wake-up either for condition or for timer interrupt based on jiffies.
wait_event_timeout(wq, condition, timeout);wait_event_freezable():
wait_event_freezable(wq, condition);wait_event_command():
wait_event_command(wq, condition, pre-command, post-command);wait_on_bit(): Here the wait queue is created internally. Can also happen to have 1 wait queue per thread. The condition is given by checking a bit inside a bit-mask.
wait_on_bit(unsigned long *word, int bit, unsigned mode);
wait_on_bit_timeout():
wait_on_bit_timeout(unsigned long *word, int bit, unsigned mode, unsigned mode, unsigned long timeout);
wake_up_bit():
wake_up_bit(void *word, int bit);
Notiamo che per permettere di passare delle condizioni, queste API non sono API tradizionali ma bensì delle macro.
5.1 Scheme for Interruptible Waits
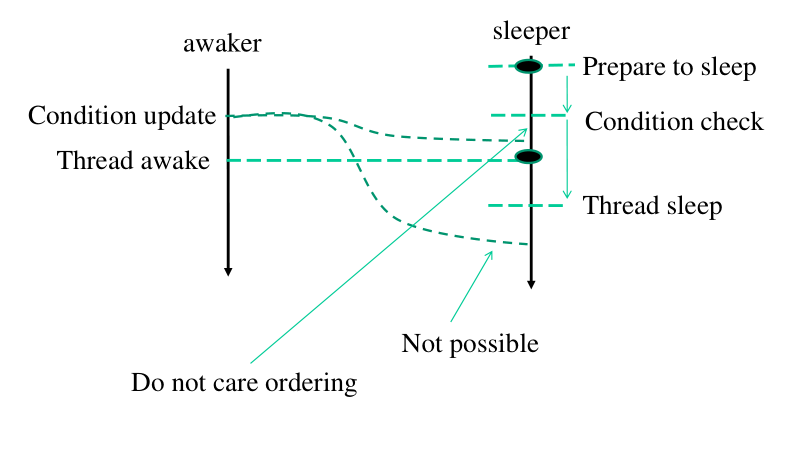
Lo schema che viene implementato dalle wait event queues è il seguente:
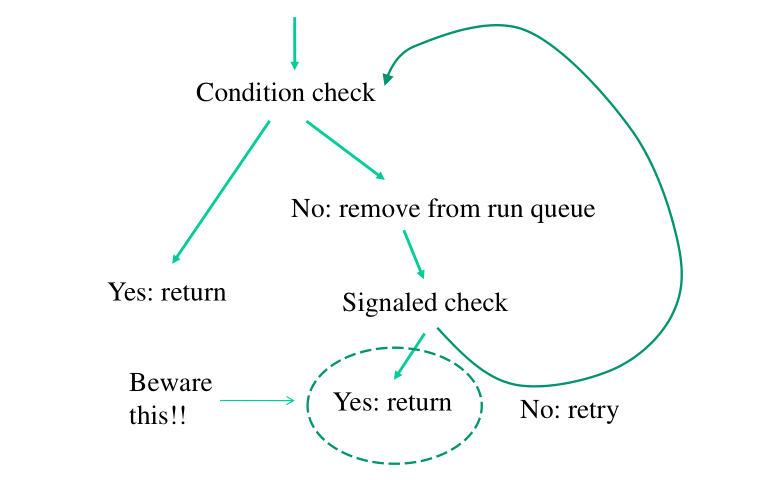
Più in dettaglio:
Entriamo e facciamo il check della condizione.
Se il check è vero ritorniamo subito.
Altrimenti ci togliamo dalla run-queue e ci mettiamo a dormire.
Ad un certo punto torno sulla run queue. Se sono tornato sulla run queue perché qualcuno mi ha segnalato, allora ritorno.
Se non sono stato segnalato, devo verificare se la condizione è verificata.
Notiamo che con questo schema non è possibile perdere dei risvegli.
Supponiamo infatti di trovarci nella seguente situazione: qualcuno cerca di fare una update su una condizione, e poi porta il TCB del thread che sta in wait su quella condizione nella run-queue. É possibile che queste attività possano essere invertite? Ovvero, è possibile che l'update della condizione non sia osservabile quando eseguo la sezione critica che porta il TCB del thread interessato nella run queue?
La risposta a questa domanda è no, non è possibile, in quanto la sezione critica utilizzata delle istruzioni read-modify-and-write che serializzano gli accessi alla memoria.
6 RUNNING EXAMPLES
6.1 CPU-POSITIONING-SWITCHING-SERVICE
In questo esempio si implementa un servizio che stampa informazioni sul CPU-core in cui il servizio sta girando e sul numero di context-switch effettuati fino a quel momento.
Per implementare questo servizio dobbiamo associare ad ogni
thread dei metadati. Questi metadati devono essere utilizzati da
due system calls: una system call che fa il setup dei metadati, e
un'altra che gli legge. Abbiamo poi bisogno di inserire una
k-prob-ret nello scheduler() .
Il problema fondamentale da risolvere per implementare questo servizio è capire dove andare a memorizzare questi metadati per ogni thread. A tale fine notiamo che non è possibile inserire i dati nel TCB, in quanto il TCB è una struttura molto compatta, e quindi dovrei cambiare la sua definizione e ricompilare il kernel per implementare una soluzione del genere.
L'idea è quella di inserire questi metadati sullo stack del kernel
associato al thread, subito dopo la zona associata alla
thread_info .
6.1.1 module #1
Il primo modulo che andiamo a montare si occupa del reset e del retrieval per i metadati che associato ad ogni thread.
A tale fine definiamo la seguente struttura dati, che contiene le informazioni di interesse per ogni thread. Questa struttura sarà poi embeddata subito dopo thread_info.
typedef struct _monitor { int cpu_id; int switches; } monitor;
La funzione che resetta tale struttura è la seguente
asmlinkage long sys_monitor_reset(void) { monitor *p; printk("%s: sys_monitor_reset has been called - current is %d\n", MODNAME, current->pid); // NOTE: the monitor struct is embedded in the stack zone of the // thread, right after the thread_info structure. p = (monitor *)current->stack + sizeof(struct thread_info); p->cpu_id = -1; p->switches = 0; return 0; }
La funzione che invece estrae le informazioni e le passa allo user space è la seguente
asmlinkage long sys_get_cpu_id(monitor *buff) { monitor *p; int ret; printk("%s: sys_get_cpu_id has been called - current is %d\n", MODNAME, current->pid); p = (monitor*)current->stack + sizeof(struct thread_info); printk("%s: cpuid info is: %d\n", MODNAME, p->cpu_id); // do the copy copy_to_user((char*)buff, (char*)p, sizeof(monitor)); return 0; }
6.1.2 module #2
Il secondo modulo da montare si occupa di inserire un hook alla
funzione schedule() in modo tale che ogni volta che cambiamo
thread possiamo eseguire il nostro codice.
Definiamo come prima cosa un parametro del nostro modulo che conta il numero di volte in cui la hook function viene eseguita
unsigned long audit_counter = 0; module_param(audit_counter, ulong, S_IRUSR | S_IRGRP | S_IROTH);
Andiamo poi a definire un tail hook da mettere alla funzione
schedule() . Tale funzione deve aggiornare le informazioni
associate al thread in esecuzione.
static int tail_hook(struct kretprobe_instance *ri, struct pt_regs *regs) { monitor *p; int cpu_id; atomic_inc((atomic_t)* &audit_counter); p = (monitor*) current->stack + sizeof(struct thread_info); cpu_id = smp_processor_id(); if(p->cpu_id != cpu_id) { p->switches++; } p->cpu_id = cpu_id; return 0; }
Definiamo la struct kretprobe utilizzata per indicare l'handler da hookare.
static struct kretprobe krp = { .handler = tail_hook, };
E per finire definiamo le funzioni hook_init() , che setta l'hook,
e hook_exit() , che toglie l'hook.
static int __init hook_init(void) { int ret; krp.kp.symbol_name = "finish_task_switch" ret = register_kretprobe(&krp); if (ret < 0) { pr_info("hook init failed, returned %d\n", ret); return ret; } printk("hook module correctly loaded\n"); return 0; }
static void __exit hook_exit(void) { unregister_kretprobe(&krp); printk("Hook invoked %lu times\n", audit_counter); printk("hook module unloaded\n"); }
E rendiamo queste due funzioni rispettivamente la funzione di inizializzazione e di cleanup del modulo
module_init(hook_init); module_exit(hook_exit);
6.2 SLEEP-WAKEUP-QUEUE
Vogliamo implementare un servizio di sincronizzazione tra thread. In particolare abbiamo dei thread che possono chiamare una sys call per andare a dormire e dei thread che possono chiamare un'altra sys call per risvegliare i thread andati a dormire.
Più thread possono andare a dormire ma solo uno si risveglia quando chiamiamo la apposita system call. Il thread che si risveglia è il thread che è andato a dormire per primo.
Per implementare questo servizio possiamo scegliere due possibili strade:
Abbiamo una wait queue condivisa da ogni thread. La chiamata bloccante non fa altro che prendere il riferimento a questa wait queue e accodare il TCB del thread chiamante, mentre la chiamata sbloccante prende il primo elemento della coda e lo sveglia. Questa soluzione però necessita l'allocazione di memoria esterna. Inoltre, chi alloca la wait queue?
Utilizziamo sempre la zona di memoria nello stack del thread subito dopo la zona del thread_info. Qui inseriamo una wait queue per ogni thread, e colleghiamo le wait queues tra loro per formare una lista. Abbiamo poi un puntatore condiviso tra tutti i thread che punta all'inizio di questa coda.
Anche se questa soluzione non richiede l'allocazione di memoria esterna, potrebbe però portare alla perdità degli wake-ups. Queste segue dal fatto che, dopo aver risvegliato un thread tramite la wake_up(), anche se il thread svegliato viene riportato nella run-queue, non sappiamo quando quest'ultimo verrà eseguito, e quindi quando rimuoverà se stesso dalla nostra lista di sleeping threads. Nella concorrenza quindi un altro thread potrebbe effettuare la wake_up(), e, in questo caso, è possibile che trovi la stessa entry di prima.
Andiamo quindi a mostrare una implementazione della seconda soluzione.
Per iniziare definiamo quindi i parametri del modulo
// param to choose if threads can sleep or not static int enable_sleep = 1; module_param(enable_sleep,int,0660); // param to show how many threads are still sleeping unsigned long count __attribute__ ((aligned (8)));; module_param(count,long,0660);
La struct che vogliamo embeddare nella zona del kernel stack del thread invece è la seguente
typedef struct _elem{ struct task_struct *task; int pid; int awake; struct _elem * next; } elem;
Inoltre abbiamo le seguenti variabili globali
elem head = {NULL, -1, -1, NULL}; elem *list = &head; spinlock_t queue_lock;
Segue quindi una discussione delle due syscall implementate dal modulo.
6.2.1 sys_goto_sleep()
asmlinkage long sys_goto_sleep(void) { volatile elem me; elem *aux = list; // private queue for given thread. wakeup is done selectively using // the wake_up_process. DECLARE_WAIT_QUEUE_HEAD(the_queue); // add in our stack area information about the fact that we want to // sleep. me.next = NULL; me.task = current; me.pid = current->pid; me.awake = 0; if(!enable_sleep) { return -1; } // lock the list and put my record on the tail spin_lock(&queue_lock); if(aux == NULL) { // badly formed wait-queue spin_unlock(&list); return 0; } // go to the end of the list and link ouselves to the list. while(aux->next != NULL) { aux = aux->next; } aux->next = &me; // unlock the list spin_unlock(&queue_lock); // add new sleeper to the count atomic_inc((atomic_t*) &count); // go to sleep, waiting for the condition me.awake to be set to YES. wait_event_interruptible(the-queue, me.awake == YES); // now that we are awake, we have to remove ourselves from the list // of sleeping threads. aux = list; spin_lock(&queue_lock); if(aux == NULL) { spin_unlock(&queue_lock); return -1; } while(aux->next != NULL) { if(aux->next->pid == current->pid) { aux->next = me.next; break; } aux = aux->next; } spin_unlock(&queue_lock); // remove sleeper to the count atomic_dec((atomic_t*) &count); if(me.awake == NO) { // we exited sleep for signal, and not for condition. } return 0; }
6.2.2 sys_awake()
// awake first thread that went to sleep. asmlinkage long sys_awake(void) { struct task_struct *the_task; int its_pid = -1; elem *aux = list; // get lock on list // // NOTE: preempt_disable() is redudant, since spin_lock already // increments the pree-emption counter. preempt_disable(); spin_lock(&queue_lock); // wake up first element of the list if(aux == NULL) { spin_unlock(&queue_lock); } if(aux->next) { the_task = aux->next->task; aux->next->awake = 1; its_pid = aux->next->pid; wake_up_process(the_task); } // free lock on list // // NOTE: preempt_enable() is redundant, since spin_unlock already // decrements the pree-emption counter. spin_unlock(&queue_lock); preempt_enable(); return 0; }