AOS - 26 - KERNEL TASK MANAGEMENT V
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 5/7
Argomenti:
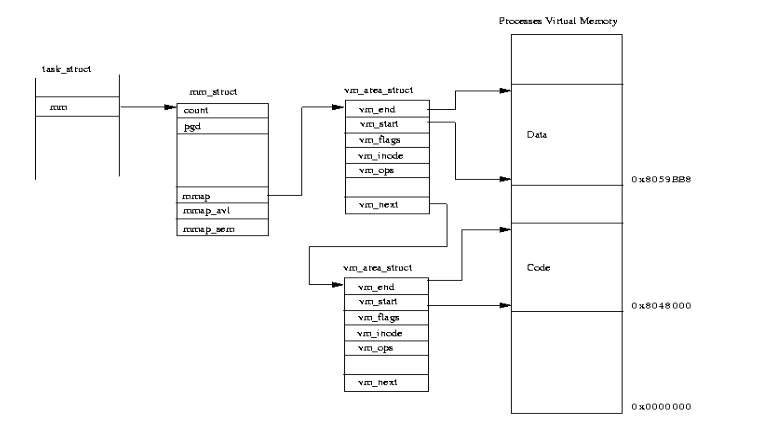
vm_area_struct
PID Namespaces Scheme
PID to task_struct Mapping
Creation of Processes/Threads
Introduzione:
1 TCB and Memory Management
Un thread vive in un address space. Di un thread sappiamo varie cose, tra cui l'indirizzo del TCB e, nel caso in cui è in esecuzione nella CPU, l'indirizzo della sua page table.
La page table però offre solamente una visione parziale dello stato
della memoria su cui il thread sta lavorando. Possono infatti
esistere delle pagine logiche mappate di cui però la page table non
sa nulla. Queste informazioni vengono salvate in una vm_area list
che contiene elementi di tipo vm_area_struct , ciascuno dei quali
rappresenta informazioni sull'utilizzo della memoria logica da parte
di thread livello user-space.
Tutte le informazioni relative al memory management di un dato
thread sono inserite in una tabella intermedia, che viene puntata
dal TCB. Questa tabella prende il nome di mm , ed è una mm_struct
definita in include/linux/sched.h o, nelle versioni più recenti
del kernel, in include/linux/mm_types.h .
I campi della struttura mm sono:
pgd: contiene l'indirizzo virtuale della page table. Se lavoriamo in modalità PTI, la tabella delle pagine è fatta da due pagine distinte: una per lato kernel, e una per lato user.
mmap: che punta alla lista di
vm_area_structe contiene le informazioni su ogni segmento di memoria logica valido per l'applicazione.
1.1 vm_area_struct
La struttura della vm_area_struct è la seguente
struct vm_area_struct { // address space we belong to struct mm_struct *vm_mm; // start address within vm_mm unsigned long vm_start; // first byte after end address within vm_mm unsigned long vm_end; // next item in the list struct vm_area_struct *vm_next; // access permission of this vma. pgprot_t vm_page_prot; // ... // function pointers to deal with this struct. Anytime we have to do // something regarding this memory segment, we use one of these // functions. // // For example, during a page fault, the page fault handler will use // one of these function to deal with this memory segment. struct vm_operations_struct *vm_ops; // ... };
Graficamente abbiamo il seguente schema
2 Threads Identification
Nella nostra visione comune del funzionamento dei sistemi operativi sappiamo che ad ogni thread è associato un identificativo, chiamato thread_id (tid), o process_id (pid). Questo identificativo può essere passato a delle API per effettuare delle operazioni sullo stato del thread identificato.
I moderni sistemi operativi offrono però anche la possibilità di
associare più di un identificativo ad un dato thread. Un
identificativo "reale" ( current->pid ), e un identificativo
"virtuale".
L'utilizzo degli identificativi virtuali permette la creazione di namespaces, ovvero spazi di nomi. Dato un namespace abbiamo la possibilità di definire delle API che lavorano solamente su quel namespace. Limitando la visibilità della API ad un particolare namespace, possiamo costruire dei "contenitori" per far in modo che il thread in esecuzione può utilizzare solamente determinate risorse.
Un esempio di API che lavorano su specifici namespaces è la chiamata
di sistema ppid() , che ritorna l'ID del thread genitore che si trova
all'interno dello stesso namespace del thread che ha invocato la sys
call.
2.1 PID Namespaces Scheme
Il namespace basico viene utilizzato per settare il valore di
current->pid durante la creazione del thread. Quando creiamo un
thread però possiamo anche specificare di muovere il thread creato
in un'altro PID namespace, che diventa il PID namespace figlio
rispetto al PID namespace in cui il thread è stato inizialmente
creato.
Linux offre al più 32 livelli di namespaces.
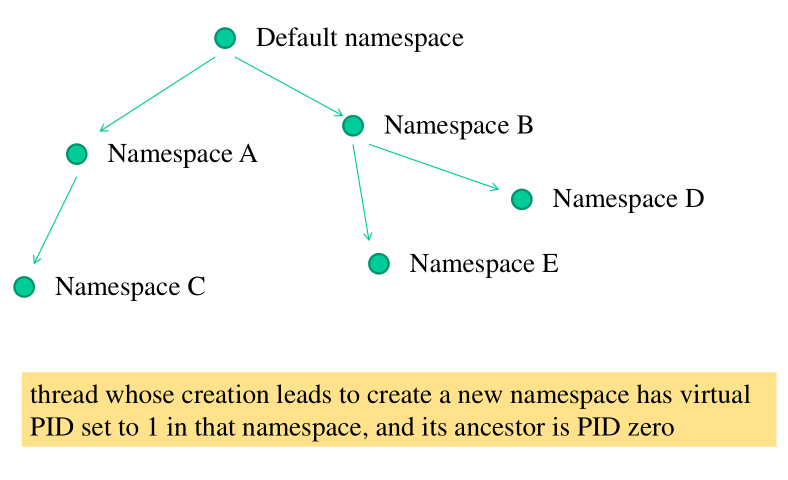
Ai thread che vengono creati in nuovi namespaces associamo quindi due identificativi:
un thread_id tradizionale
un virtual thread_id all'interno del nuovo namespace in cui il thread si andrà a muovere.
Per la creazione di un nuovo namespace necessitiamo di privilegi root.
2.1.1 Namespace Visibility
Un thread che viene creato in un namespace non può accedere alle informazioni che identificano i thread che vivono in un namespace ancestrale rispetto al nostro. Un thread che vive in un namespace può quindi mandare segnali ad altri thread che vivono nello stesso namespace, ma non può inviare dei segnali a thread che vivono in namespaces ancestrali.
Dato che i namespaces sono separati, può succedere di avere lo stesso id in due namespaces diversi. Non ci possono essere confusioni in quanto l'identificativo effettivo è namespace + id.
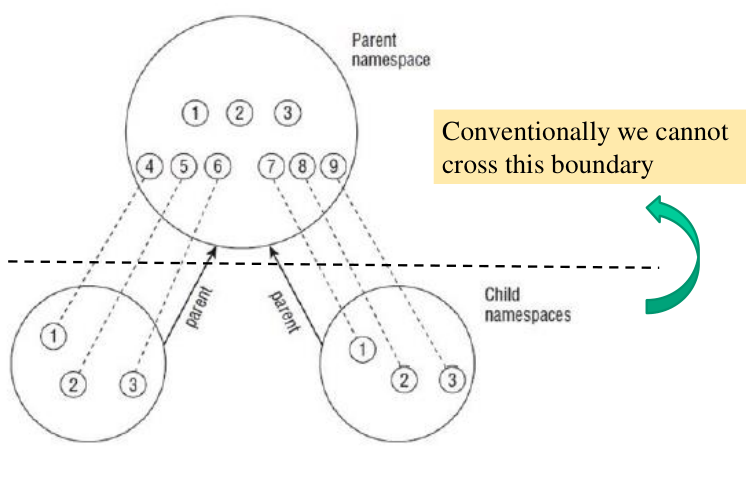
Esistono dei processi root che girano nel namespace ancestrale e che sono in grado di vedere tutti i thread, anche quelli che vivono in namespace figli.
Questo comportamento può ovviamente essere modificato se andiamo ad hackerare la logica del kernel.
2.1.2 Namespace Implementation
L'implementazione di questo sistema è stata fatta inserendo un
puntatore all'interno del TCB dei vari thread. Il puntatore
inserito è un puntatore alla struttura struct nsproxy .
La struttura nsproxy (namespace proxy), definita nel file
include/linux/nsproxy.h , contiene tutte le informazioni riguardanti
l'identificatore del namespace del thread descritto da quel TCB.
2.2 PID to task_struct Mapping
Molti servizi del kernel, come ad esempio le sleep/wait queues, lavorano utilizzando l'indirizzo di memoria del TCB di un dato thread. Per poter utilizzare questi servizi in modo semplice dobbiamo quindi introdurre dei mappings tra i PIDs e gli indirizzi dei TCB.
In Linux questi mappings sono basati su strutture di hashing, che ci permettono di risalire velocemente all'indirizzo del TCB di un dato thread, dato il PID del thread. In particolare si ha una struttura di hashing per gestire il namespace ancestrale, e poi per ogni nuovo namespace che viene creato esiste una associata struttura di hashing che permette di gestire gli identificatori che vivono in quel namespace.
2.2.1 find_task_by_pid (old way)
Per la gestione della hash table associata al namespace ancestrale
abbiamo il seguente codice, presente in include/linux/sched.h .
#define PIDHASH_SZ (4096 >> 2) extern struct task_struct *pidhash[PIDHASH_SZ]; // hashing rule #define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1)) // function which allows the retrieval of the memory address of a TCB // using the pid. static inline struct task_struct *find_task_by_pid(int pid) { struct task_struct *p; struct task_struct **htable = &pidhash[pid_hashfn(pid)]; // iterate the bucket list for the particular hash table entry. for(p = *htable; p && p->pid != pid; p = p->pidhash_next); return p; }
2.2.2 find_task_by_vpid (new way)
Nei sistemi moderni con l'introduzione dei namespaces virtuali e
degli identificatori virtuali non viene più utilizza la funzione
find_task_by_pid() . Le nuove versioni del kernel (>= 2.6)
supportano infatti la funzione
struct task_struct *find_task_by_vpid(pit_t vpid);
che utilizza il concetto di virtual_pid, ovvero il pid associato al namespace in cui il thread sta lavorando.
Nel caso in cui un thread viva solamente nel namespace ancestrale, il suo virtual_pid corrisponde al suo pid. Per tutti gli altri invece il virtual_pid è diverso dal pid. Per effettuare l'hashing dei vPIDs all'interno dei namespaces si utilizza la struttura dati pid
struct pid { atomic_t count; unsigned int level; /* lists of tasks that use this pid */ struct hlist_head tasks[PIDTYPE_MAX]; struct rcu_read rcu; struct upid numbers[1]; };
Abbiamo poi le seguenti funzioni
// Used to obtain TCB of the thread associated with the vPID. struct task_struct *pid_task(struct pid *pid, enum pid_type); // querying the TCB address by the default PID // // find_vpid(pid) is used to determine the address of the pid // structure. // // pid_task(find_vpid(pid), PIDTYPE_PID);
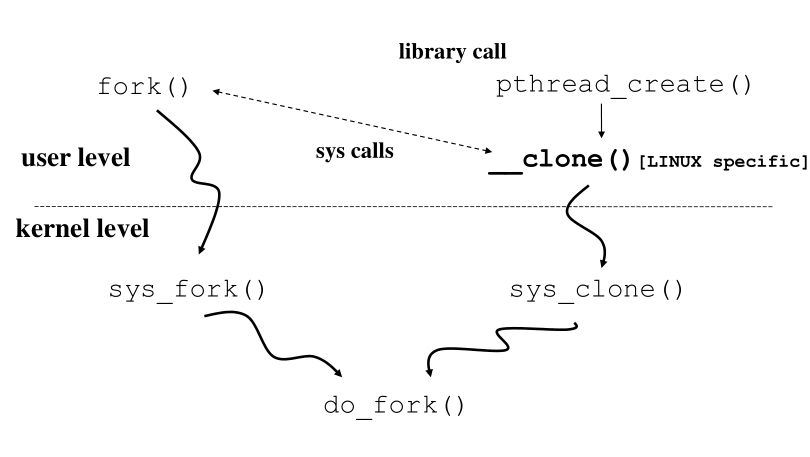
3 Creation of Processes/Threads
Sappiamo che lato user abbiamo la funzione fork() per la creazione
di un nuovo processo, e la funzione pthread_create() per la
creazione di un nuovo thread. La funzione pthread_create() poi
chiama una funzione specifica per LINUX chiamata __clone() , che a
sua volta chiama la sys call sys_clone() . La funzione fork() invece
chiama la sys call sys_fork() . Sia la sys_clone() che la sys_fork()
internamente chiamano la funzione do_fork() .
3.1 clone()
La libreria glibc offre il seguente prototipo
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ... /* pid_t *pid, void *newtls, pid_t *ctid */);
Che in x86-64 diventa
long clone(unsigned long flags, void *child_stack, int *ptid, int *ctid, unsigned long newtls);
Mentre in x86-32 diventa
long clone(unsigned long flas, void *child_stack, int *ptid, unsigned long newtls, int *ctid);
I flags principali necessari per la creazione di un nuovo processo/threads sono i seguenti
CLONE_VM: VM shared between processes.
CLONE_NEWPID: Create process/thread in a new PID namespace.
CLONE_THREAD: Child is placed in same thread group as calling process.
3.2 do_fork()
La do_fork() farà quindi lavoro differenziato a seconda dei
parametri passati. Questi parametri devono specificare le operazioni
necessarie per settare il nuovo processo o il nuovo thread. Ad
esempio la pthread_create() dovrà dire alla do_fork() che l'address
space non deve essere clonato, ma deve essere condiviso con il
processo chiamante.
In particolare la funzione do_fork() effettua le seguenti
operazioni:
Alloca il TCB per il nuovo thread;
Alloca la stack area per il nuovo thread;
Ottiene il proper PID (real/virtual) per il nuovo thread.
Collega alla parent memory map (optional)
Collega alla parent FS view (optional)
Collega alla parent files view (optional)
Condividi una frazione dei ticks del parent.
Notiamo che se dovessimo assegnare ad un child una quantità di tick indipendente da quella del parent, ci sarebbe la possibilità per una applicazione di prendere il controllo della CPU semplicemente continuando a creare nuovi threads.
4 RUNNING EXAMPLES
4.1 O1-SLEEP-WAKEUP-QUEUE
In questo running example andiamo a risolvere il problema trovato in sleep-wakeup-queue introducendo un ulteriore campo per verificare se un elemento della lista è già stato visto da un altro thread oppure no. Così facendo risolviamo il problema della perdità dei risvegli.
Andiamo poi ad utilizzare il campo tail per mantenere informazioni
sia sulla head che sulla tail. Questo ci permette di avere una
inserzione alla fine di O(1) e una rimozione dalla lista
ammortizzata di O(*1) .
4.2 USLEEP
TODO.
4.3 VM-CHECKER
Questo running example inserisce una sys call che scorre la vm_area list per vedere se un dato indirizzo logico è valido. Se un indirizzo logico valido viene trovato, la sys call ci dice anche quali sono le permissioni sul blocco di memoria in cui si trova quell'indirizzo.
Da questo running example è possibile notare come x86 non ci permette di distinguere se una zona di memoria è read-only o read/write. Possiamo solo verificare se una zona di memoria è accessibile in modalità read or write, e in modalità exec.
int sys_mm_inspect(unsigned long vaddr, int mode) { struct vm_area_struct *map; pgprot_t prot; int ret = 0; unsigned long mask; map = current->mm->mmap; while(map != NULL) { if((map->vm_start <= vaddr) && ((map->vm_end -1) >= vaddr)) { // Found correct block of memory printk("%s: target address found in entry for zone [%d, %d]\n", MODNAME, map->vm_start, map->vm_end); prot = map->vm_page_prot; mask = (unsigned long)pgprot_val(prot); switch(mode) { case 0: printk("%s: read only query\n", MODNAME); if( !(mask & 0x2)) ret = 1; break; case 1: printk("%s: read/write query\n", MODNAME); if( !(mask & 0x2)) ret = 1; break; case 2: printk("%s: exec query\n", MODNAME); // NOTE: 64-th bit of mask is 0 when the memory region is // executable. if (!mask & 0x8000000000000000) ret = 1; break; } return ret; } map = map->vm_next; } return -1; }
4.4 VIRTUAL-PIDS
Questo running example installa una nuova system call che prende in input un intero. Se l'intero in input è \(0\), allora la sys call ritorna il pid "reale", ovvero quello che vive nel namespace ancestrale. Altrimenti se l'input è \(1\), la sys call ritorna il pid "virtuale".
char *pr = "REAL"; char *pv = "VIRTUAL"; // NOTE: This example shows that when we run in kernel mode we can do // anything we want with the namespace architecture. We can even see // informations that we shoulnd't have access to. unsigned ing get_pid_service(int type) { char *p; unsigned int the_pid; p = type? pv : pr; printk("%s: get_pid_service asked to deliver PID type %s\n", MODNAME, p); if(type) { // get real pid // // IMPORTANT: moved to pid_allocated in latest kernel versions the_pid = current->nspoxy->pid_ns_for_children->last_pid; } else { // get virtual pid the_pid = current->pid; } // If the calling thread lives in a child namespace, and the // function is called with type = 0, then then the pid_task() will // return -1. printk("%s: adderss checking - current is %p - find task by (v)PID is %p\n", MODNAME, current_pid, pid_task(find_vpid(the_pid), PIDTYPE_PID)); return the_pid; }
4.5 NAMESPACES
In questo running example abbiamo due esempi di codici applicativi
lato user. Il codice new-namespace.c genera un thread in un nuovo
namespace. Possiamo utilizzare questo codice in combinazione con il
precedente running example (virtual-pids).
#define PAGE_SIZE 4096 #define STACK_SIZE 256 * PAGE_SIZE static char child_stack[STACK_SIZE]; // Prints PID and spawn a bash shell inside a new namespace. static int child_fn() { printf("PID: %ld\n", (long)getpid()); exelp("/bin/bash", "/bin/bash/", NULL); return 0; } int main() { // Clone thread/process into new namespace pid_t child_pid = clone(child_fn, child_stack + STACK_SIZE, CLONE_NEWPID | SIGCHLD, NULL); printf("clone returned %ld\n", (long) child_pid); // Wait for the thread with PID child_pid to exit. waitpid(child_pid, NULL, 0); return 0; }