AOS - 27 - KERNEL TASK MANAGEMENT VI
Lecture Info
Data:
Sito corso: link
Slides: AOS - 6 KERNEL TASK MANAGEMENT
Progresso unità: 6/7
Argomenti:
Semaphore APIs
Spinlock APIs
Read/Write Locks APIs
Linux Scheduler Logic
Perfect Load Sharing
Load Balancing
Introduzione: In questa lezione abbiamo visto le principali API offerte dal kernel per la sincronizzazione di threads/proessi, e abbiamo iniziato la discussione del linux scheduler, andando ad analizzare le prime due versioni dello scheduler che sono state implementate.
1 Thread Syncronization
Il kernel offre una serie di servizi per la sincronizzazione dei thread livello kernel. Questi servizi sono implementati tramite l'utilizzo delle sleep/wait queues. Abbiamo due tipologie di servizi: i semafori e gli spinlocks.
1.1 Semaphore API
DECLARE_MUTEX(): declares struct semaphor.
DECLARE_MUTEX(name);sema_init(): alternative to DECLARE_MUTEX to declare semaphor
void sema_init(struct semaphore *sem, int val);
down(): try to take a token from the semaphore. If there's no token, go to sleep.
int down(struct semaphore *sem);
down_interruptible(): try to take a token from the semaphore. If there's no token available, go to an interruptible sleep, which means that we can be awaken by external interrupts.
int down_interruptible(struct semaphore *sem);
down_trylock(): returns 0 if succeeded. If there is no token does not go to sleep.
int down_trylock(struct semaphore *sem);
up(): give back token to semaphore, thus possibly waking other threads awaiting their token.
void up(struct semaphore *sem);
1.2 Spinlock API
Quando lavoriamo modalità kernel dobbiamo stare attenti nell'utilizzo degli spinlock rispetto all'utilizzo lato applicativo. Infatti, mentre gli spinlock lato applicativo permettono solo di ottenere e rilasciare il lock sulla relativa porzione di memoria, lato kernel gli spinlocks possono anche interagire con lo stato del processore.
Per inizializzare uno spinlock possiamo utilizzare le seguenti
macro, definite in <linux/spinlock.h> .
spinlock_t m_lock = SPINLOCK_UNLOCKED; spin_lock_init(spinlock_t *lock);
Locking API (blocking):
spin_lock():
spin_lock(spinlock_t *lock);
spin_lock_irq(): takes a lock and makes the processor uninterruptible, which means that it should ingore all maskable interrupts for a time. In order to use this API we must know the state of the CPU we're running on, i.e. if its interruptible or not, in order to restore the CPU to its original state once we remove the lock.
spin_lock_irq(spinlock_t *lock);
spin_lock_irqsave(): takes a lock and makes the processor uninterruptible, which means that it should ingore all maskable interrupts for a time. We use the flags parameter to know the CPU-state before taking the spin-lock and thus possibly changing it. We are able to pass the value of flags and obtain the actual CPU-state on it later because this API is actually a macro.
spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
spin_lock_bh():
spin_lock_bh(spinlock_t *lock);
Locking API (non-blocking):
spin_is_locked():
spin_is_locked(spinlock_t *lock);
spin_try_lock():
spin_try_lock(spinlock_t *lock);
Unlocking API:
spin_unlock():
spin_unlock(spinlock_t *lock);
spin_unlock_irqrestore(): remove the lock and restores the CPU-state using the param flags.
spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
spin_unlock_irq(): remove the lock and possibly changes the CPU-state. This must be used when we already know the CPU-state.
spin_unlock_irq(spinlock_t *lock);
spin_unlock_bh():
spin_unlock_bh(spinlock_t *lock);
spin_unlock_wait():
spin_unlock_wait(spinlock_t *lock);
1.3 Read/Write Locks API
Il kernel offre anche dei meccanismi di sincronizzazione che permettono di avere readers concorrenti e writers esclusivi all'interno di sezioni critiche.
Queste API comunque non implementano un meccanismo RCU.
rwlock_t xxx_lock = __RW_LOCK_UNLOCKED(xxx_lock); unsigned long flags; read_lock_irqsave(&xxx_lock, flags); // ... // critical section that only reads the info // // here multiple readers can enter, but not the writer // ... read_unlock_irqrestore(&xxx_lock, flags); write_lock_irqsave(&xxx_lock, flags); // ... // read and write exclusive access to the info // // here only a single writer can enter // ... write_unlock_irqrestore(&xxx_lock, flags);
2 Linux Scheduler Logic
La scheduler logic è la logica utilizza per scegliere a quale thread presente nella runqueue bisogna assegnare la CPU. A seconda della versione abbiamo varie logiche utilizzate. Ciascuna logica ha le sue caratteristiche e i suoi costi.
Nell'evoluzione di Linux sono state utilizzate tre logiche per effettuare lo schedule, che sono
Perfect Load Sharing, \(O(N)\), kernel <= 2.6.
Load Balancing, \(O(1)\), 2.6 <= kernel <= 2.6.23 (2007).
Completely Fair, \(O(\log(N))\), kernel >= 2.6.23 (2007).
2.1 Schedule Baseline Aspect
In tutte le versioni dello schedule, l'idea è sempre quella di
assegnare ad ogni thread un numero di ticks, che vengono poi
consumati con l'utilizzo della risorsa CPU da parte del
thread. Quando un thread termina i suoi ticks, in determinati punti
della sua esecuzione va a chiamare la funzione scheduler() per
mandare un altro thread in esecuzione.
L'assegnazione dei ticks ai thread viene effettuato in base al concetto di epoca. All'inizio di epoca lo scheduler assegna ad ogni thread un numero di ticks. L'epoca finisce nel momento in cui tutti i thread che si trovano sulla runqueue hanno speso completamente i loro ticks. Al termine di una epoca ne inizia subito un'altra.
Durante una epoca i thread che si trovano nelle waitqueues potrebbero avere dei ticks da spendere. Quando l'epoca finisce, i nuovi ticks assegnati ai thread che si trovano sulla wait-queues devono prendenre in considerazione i ticks rimanenti nell'epoca precedente. Se così non fosse infatti potrei essere unfair per i thread bloccati sulle waitqueues.
La quantità di ticks assegnata ad un dato thread dipende anche dalla priorità del thread stesso.
2.2 POSIX Priority Scheme
Le priorità utilizzate nel Perfect Load Sharing erano allineate a quelle definite dallo standard POSIX classico, ovvero il seguente:
<--- higher priority -20, -19, -18, ..., 0, ...., +18, +19, +20
Abbiamo \(40\) livelli di priorità, in cui \(-20\) è il livello di priorità maggiore, e \(+20\) è il livello di priorità minore. Lo \(0\) è il livello di priorità di default.
Questa priorità è legata al concetto di niceness nei sistemi linux classici. Più è alta la niceness e più favorisco gli altri nell'utilizzo della CPU. La niceness può essere cambiata utilizzando delle system call. Per migliorare la niceness devo girare da root.
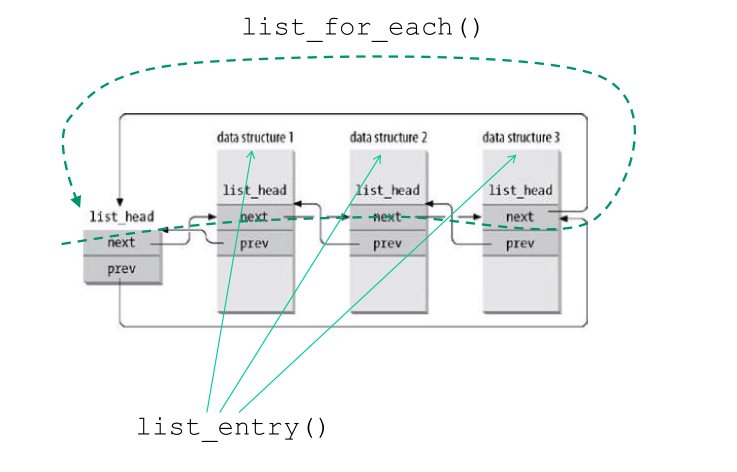
2.3 Lists Macro Facilities
La funzione schedule() è scritta utilizzando le seguenti facilities messe a disposizione dal kernel LINUX.
list_for_each(): Scans a circular list through a cusors. It assumes the element of the list have the field next
#define list_for_each(pos, head) \ for(pos = (head)->next; pos != (head); pos = pos->next)
list_entry(): Used when we embedd the elements of a list inside a wrapper structure. Given the element of the list, this macro returns the address of the container structure.
#define list_entry(ptr, type, member) \ container_of(ptr, type, member)
Graficamente abbiamo
3 Scheduler #1: Perfect Load Sharing
Il Perfect Load Sharing, come il nome suggerisce, vuole essere "perfetto" nella condivisione del carico di lavoro tra tutte le CPU.
Nel Perfect Load Sharing quando eseguiamo la schedule() si
analizzano tutti i TCB che non si trovano in qualche
waitqueue. Guardandoli tutti ci mettiamo nella condizione di
effettuare la scelta ideale (ogni thread può andare in ogni CPU)
per ottimizzare le performance dell'hardware. Questo però ha un
costo significativo.
Il valore N nel costo O(N) dello schedule() in realtà conta anche
tutti i TCB associati a thread che non sono più runnable ma che, per
qualche ragione, si trovano ancora nella runqueue.
3.1 scheduler()
L'esecuzione della funzione schedule() può essere suddivisa in tre fasi distinte, che sono:
Controlla lo stato del thread corrente: viene eseguito per capire se dobbiamo necessariamente fermare il thread corrente e toglierlo dalla runqueue.
// ... struct task_struct *prev = current; // ... switch(prev->state) { case TASK_INTERRUPTIBLE: // If there were any signals sent to the thread, do not remove the // thread from the run-queue. if(signal_pending(prev)) { prev->state = TASK_RUNNING; break; } default: // Remove the TCB of the currently executing thead from the // run-queue. del_from_runqueue(prev); case TASK_RUNNING:; // Do nothing } // Already executing schedule() call, no need to do it again. prev->need_resched = 0;
Analisi dello stato della unique-runqueue: eseguita per andare a selezionare il prossimo thread da mandare in esecuzione. L'affinità è presa in considerazione. In particolare, per ogni TCB presente nella run-queue è calcolato un valore che prende il nome di goodness value. Il thread con il TCB associato al migliore goodness value è quello viene scelto dallo scheduler. Il valore della goodness è calcolato utilizzando varie informazioni, tra cui la memory view del thread che sta lasciando la CPU.
repeat_schedule: next = idle_task(this_cpu); // idle process c = -1000; // initial best goodness value list_for_each(tmp, &runqueue_head) { p = list_entry(tmp, struct task_struct, run_list); if(can_schedule(p, this_cpu)) { // compute goodness using various info, // // see *goodness computation* int weight = goodness(p, this_cpu, prev->active_mm); if(weight > c) // update best goodness value so far c = weight, next = p; } }
Context switch: per iniziare ad eseguire il thread scelto.
3.2 Goodness Value
3.2.1 mm and active_mm
All'interno di un TCB sono presenti due memory view. Una è chiamata
mm , e l'altra è chiamata active_mm . Questa seconda memory view
viene utilizzata dalla logica dello scheduler per calcolare il
valore di goodness. In particolare, dato un TCB, l' active_mm di
quel TCB rappresenta la mappatura della memoria user-space
dell'ultimo thread attivo nella corrente CPU.
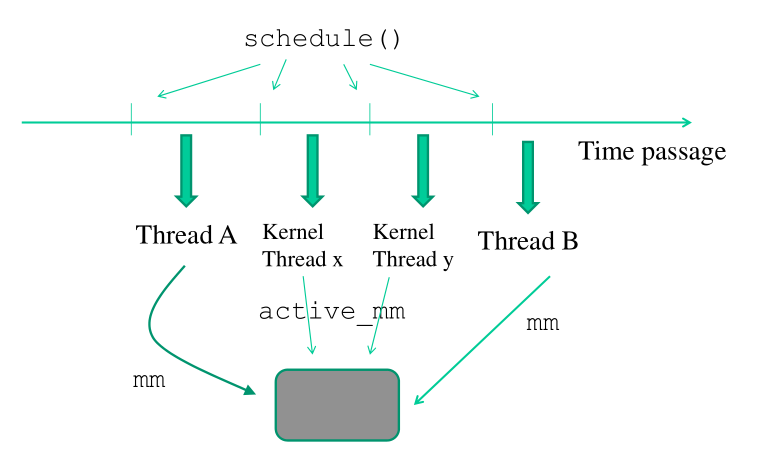
Notiamo che un kernel livello thread, dato che gira nello spazio di indirizzamento kernel, non ha bisogno di avere le informazioni sulla propria memory view all'interno del TCB. Dunque, per i kernel level thread, abbiamo che
mm == NULL active_mm == user space memory of last user level thread run on this same CPU
Per i thread lato user invece è importante avere le informazioni sulla propria memory view nella struct mm, in quanto ogni thread/processo può vivere nel suo spazio di indirizzamento. Quindi, per i thread lato user, si ha che
mm == active_mm
Tramite questo meccanismo posso relazionare la memory view di un thread livello user, con la memory view dell'ultimo thread livello user che è stato eseguito sulla CPU, anche se tra i due thread sono stati eseguiti altri thread livello kernel.
3.2.2 Formula Used
La formula per calcolare la goodness è la seguente
goodness(p) = 20 - p->nice (base time quantum)
+ p->counter (ticks left in time quantum)
+ 1 (if page table is shared with previous process)
+ 15 (in SMP, if p was last running on same CPU)
Se p->counter = 0, ovvero se il thread ha finito i suoi ticks, il valore della goodness del thread è forzato a 0.
Notiamo poi che il bonus +15 significa che con questa logica di scheduling l'idea è quella di assegnare sempre allo stesso thread la CPU fino a quando non finisce i ticks, o fino a quando si creano delle differenze sostanziali in termine di ticks tra il thread in esecuzione e gli altri thread nella runqueue. Questo bursting dei ticks in modo batch mi assicura che sto utilizzando le architetture di cache nel modo più efficiente possibile.
3.3 Epochs Management
Quando tutti i thread presenti nella runqueue terminano i loro ticks (p->counter = 0, for all p in runqueue), lo scheduler riassegna a ciascun thread attivo (sia nelle runqueue e sia nelle waitqueues) un determinato numero di ticks.
La formula utilizza per ri-assegnare il numero di ticks è la seguente:
p->counter = p->counter / 2 + 6 - p->nice / 4
Il codice che si occupa di fare questo è il seguente
// ... // Do we need to re-calculate counters? if(unlikely(!c)) { struct task_struct *p; spin_unlock_irq(&runqueue_lock); read_lock(&tasklist_lock); for_each_task(p) p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice); read_unlock(&tasklist_lock); spin_lock_irq(&runqueue_lock); goto repeat_schedule; } // ...
Notiamo che per il ricalcolo dei ticks non possiamo utilizzare solamente le wait queues, in quanto noi stessi possiamo definire delle wait queues senza dirlo al kernel. Per non complicare la registrazione di eventuali wait queues, per il ricalcolo dei ticks si utilizza il namespace ancestrale in cui si trovano tutti i thread.
3.4 Overview
Il perfect load sharing scheduler ha le seguenti caratteristiche:
Una task settata a NON-RUNNABLE viene comunque cercata per calcolare la sua goodness
I runnable e non-runnable task vengono inseriti in una singola run-queue in ogni data epoca.
In sistemi SMP/multi-core abbiamo delle possibili performance negative in caso di chiamate successive alla funzione
schedule()in caso di heavy system load. Infatti se un CPU-core ha chiamatoschedule(), gli altri CPU-cores non possono entrare inschedule(), e sono quindi costretti a fare busy-waiting.
4 Scheduler #2: Load Balancing
La logica Load Balancing permette di avere uno schedule in tempo costante \(O(1)\). Notiamo però che questo \(O(1)\) ci dice che siamo scalabili rispetto al carico, e non rispetto ad eventuali conflitti nella concorrenza tra vari CPU-cores. In ogni caso, il Load Balancing garantisce anche una frequenza molto bassa di collisioni tra CPU-cores per ispezionare una stessa run-queue.
L'obiettivo è quello di mantenere il carico bilanciato tra le CPU. Vogliamo quindi che ogni CPU-core abbia del lavoro da fare, e che tale lavoro sia bilanciato rispetto al lavoro assegnato alle agli altri CPU-core.
Anche nello schema Load Balancing devono essere in grado di distinguere le priorità dei task.
4.1 Main Characteristics
Nel load balancing non abbiamo una mistura tra runnable e non-runnable tasks all'interno della stessa runqueue. Abbiamo quindi una chiara separazione dei runnable tasks su multiple run queues. In questo schema abbiamo quindi una runqueue per CPU-core. Ciascun CPU-core accede alla propria runqueue quando esegue la logica dello scheduler. Eventualmente è possibile che un CPU-core accedere alla runqueue di un altro CPU-core. L'evento di cross-runqueue-access succede nei seguenti casi:
Il thread da mandare in esecuzione ha una una elevata affinità con un altro CPU-core.
Il carico del CPU-core corrente è troppo alto, e quindi una CPU che ha poco carico, oppure un demone che girà su una qualche CPU, sposta il carico per cercare di ribilanciare il carico di lavoro sui vari CPU cores.
Il lavoro di ribilanciamento viene effettuato andando a guardare i metadati memorizzati nella head della runqueue per ogni CPU-core.
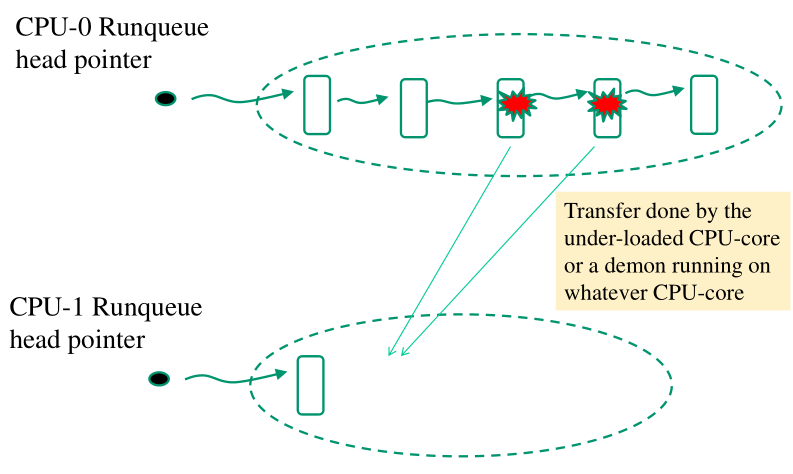
Un'altra caratteristica di questo scheduler è il fatto che le priorità non sono ottenute andando a guardare all'interno dei TCBs, ma sono conosciute a priori in base alla runqueue in cui quel TCB si trova. Non dobbiamo quindi scorrere la lista per calcolare il thread con la priorità maggiore.
4.2 Implementation Scheme
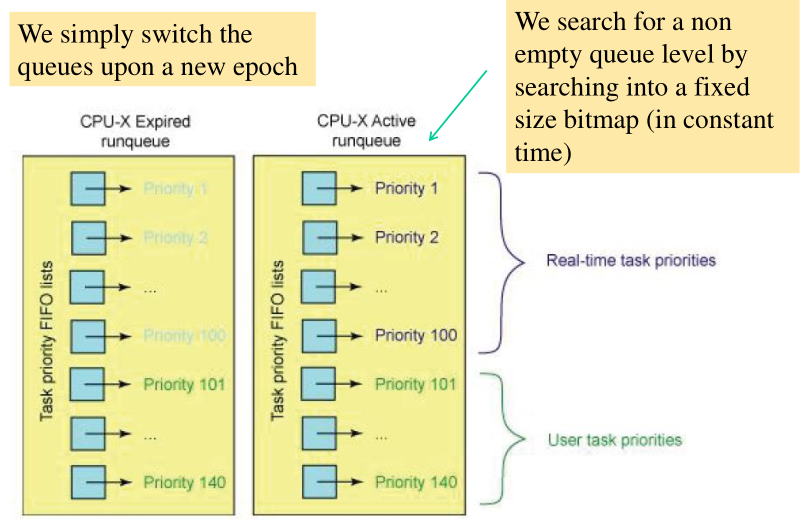
Nell'implementazione linux (kernel >= 2.6) del Load Balancing schedule abbiamo 140 livelli di priorità. A ciascun livello corrisponde una particolare runqueue. La priorità associata ai TCB è quindi assegnata in base al particolare livello in cui vengono inseriti. I 140 livello di priorità sono divisi nel seguente modo:
I 40 livelli dal 100 al 139 vengono mappati ai classici livelli di priorità UNIX-like.
I 100 livelli dal 0 al 99 vengono mappati a priorità di livello real-time.
Graficamente,

Per ogni livello in realtà abbiamo due runqueues: una attiva, in cui ci sono i thread da eseguire, e una expired, che contiene i thread che hanno utilizzato i loro ticks. Quando tutti i thread passano dalla active queue alla expired queue, i puntatori delle queue vengono scambiati e si ricomincia da capo.
Quando chiamiamo la funzione wake_up_process() si verifica se
l'affinità del thread che stiamo svegliando è compatibile con il
CPU-core in cui sta eseguendo. Se la verifica risulta essere
positiva, il thread viene messo nella run-queue del CPU-core
locale. Se invece la verifica fallisce, è possibile utilizzare la
funzione
void ttwu_queue(struct task_struct *p, int cpu, int wake_flags)
che permette di specificare che si vuole svegliare un thread in modo tale da inserire il relativo TCB nella runqueue associata ad uno specifico CPU-core. In questi casi, dopo aver inserito il TCB di un thread nella run-queue di un altro CPU-core, la CPU che ha inserito il TCB invia un interrupt alla CPU a cui è associata la runqueue in cui è stato inserito il TCB. Quest'ultima esegue un top-half minimale e flagga il thread per andare in pre-emption. Quando il thread prende il controllo, verifica se può andare in pre-emption e chiama la funzione dello scheduler. Così facendo è possibile passare il controllo ad un processo più prioritario.
4.3 Calcolo dei Ticks
Nel Load Balancing l'assegnazione dei ticks ai threads è effettuata sulla nozione di "load", ovvero di carico di lavoro.L'informazione sulla load è contenuta in un field all'interno della TCB, ed è strutturato nel seguente modo
struct sched_entity { struct load_weight load; }; struct load_weight { // value assigned on the basis of the niceness. // used in the calculation of ticks to spend. unsigned long weight; u32 inv_weight; }; // see slides pg 148 static const int prio_to_weight[40];
4.4 Static and Dynamic Priorities
Un thread non-real-time è caratterizzato da due valori di priorità:
Priorità statica: Definita dagli utenti (associata alla niceness), indica il livello iniziale in cui il thread apparirà nella runqeueu.
Priorità dinamica: Viene calcolata utilizzando dei meccanismi di reward o penalty sul valore di base della priorità statica. Essenzialmente più un thread è I/O bound, e più la sua priorità dinamica è alta.
Per i thread real-time invece esiste solo la priorità statica, e quindi il comportamento dei thread real-time non va ad influire nel tempo sul loro livello di priorità.
Il valore che viene visto dallo scheduler() è la priorità dinamica per i thread non-real-time e quella statica per i thread real-time.
L'effetto delle priorità dinamica è che, può succedere, che dati due thread A e B, con A avente priorità statica maggiore di B, può succedere che la priorità dinamica di B diventi più grande di quella di A, e quindi che lo scheduler scelga B al posto di A. Questo fatto poi diventa grave nel momento in cui B tenta di aumentare la sua priorità dinamica fingendo di essere I/O bound, o comunque andando a dormire per un determinato tempo.
Le priorità dinamiche presenti nel Load Balancing ci permettono di implementare dei meccanismi di feedback, in cui i tick assegnati ad un thread dipendono dal comportamento passato del thread stesso. In particolare più un thread è I/O-bound, e più ha una priorità dinamica maggiore.
4.5 CPU-Scheduling API
Il numero di ticks residui per un thread nell'epoca corrente è dato
dalla variabile p->time-slice . I kernel offre poi le seguenti APIs
per interagire con lo scheduler
schedule(): Main scheduler function. Schedules highest priority task for execution.
load_balance(): Check the CPU to see wheter an imbalance exists, and, if so, attempts to move tasks between CPU-cores.
effective_prio(): Returns effective priority, that is, the dynamic priority based on the static one + eventual rewards/penalties
recalc_task_prio(): Determines a task's bonus or penalty based on its idle time.
source_load(): Calculate load of source CPU from which a task could be migrated.
target_load(): Calculate load of target CPU where a task can be migrated to other CPUs.
4.6 Explicit Stack Refresh
Lavorando con delle runqueues che sono specifiche per i vari CPU
cores può succedere che un thread chiama la funzione schedule() e
viene de-schedulata. Ad un certo punto poi la funzione riprende il
controllo. Nel frattempo però potrebbe aver cambiato
CPU-core. Abbiamo quindi un thread che esegue una funzione, la
funzione schedule() , cross-cpu-cores. Dato che queste funzioni
possono avere delle variabili locali identificate dall'ID del
CPU-core in cui stiamo eseguendo, dobbiamo stare attenti a come
gestiamo il context-switch durante l'esecuzione di una funzione.
Per risolvere questa problematica il programmatore di sistema deve essere aware di questa problematica e deve utilizzare delle specifiche facility per effettuare lo stack refresh esplicito. In particolare le variabili locali vengono esplicitamente ripopolate nella stack dopo che si cambia lo stack per eseguire il nuovo thread nella nuova CPU.
// ... cpu = smp_processor_id(); rq = cpu_rq(cpu); rcu_qsctr_inc(cpu); prev = rq->curr; // ... /* the context switch might have flipped the stack from under us, hence refresh the local variables. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); // ...
4.7 Runqueue Structure
La runqueue ha la seguente struttura
strut rq { // runqueue lock spinlock-t lock; // nr_running and cpu_load should be in the same cacheline because // remote CPUs use both these fields when doing load calculation. unsigned long nr_running; #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU-LOAD_IDX_MAX}; //... struct task_struct *curr, *idle; //... struct mm_struct *prev_mm; //... };