AOS - 30 - TRAP/INTERRUPT ARCHITECTURE II
Lecture Info
Data:
Sito corso: link
Progresso unità: 2/2
Argomenti:
IPI in Linux
IPI API
Sequentialization of IPIs
Preemption Effects of IPIs
Introduzione: Nella lezione scorsa avevamo descritto la struttura e le funzioni principali dell'handler registrato nell'IDT. In particolare avevamo descritto come questo handler viene utilizzato per allineare la stack in qualsiasi tipo di situazione, sia nei casi in cui il firmware passa un error code, sia nei casi in cui il firmware non passa l'error code. Questo handler poi, ad un certo punto della sua esecuzione, deve chiamare il gestore effettivo della trap/interrupt, tipicamente scritto in tecnologia C.
1 IPI Usage
Come abbiamo già visto, gli IPI ci permettono di inviare interrupts tra CPU-cores diversi tramite il bus offerto dall'architettura APIC. Andiamo adesso a vedere con maggior dettaglio cosa succede a livello software per la gestione degli IPI.
La prima domanda che ci possiamo porre è la seguente: è possibile inviare un IPI senza verificare lo stato del sistema? La risposta è si, nei seguenti casi:
La gestione dell'IPI da parte dei vari CPU-cores non richiede l'utilizzo di strutture dati condivise.
Kernel panics.
Altri utilizzi degli IPI sono invece gestiti in modo più complesso. Questi utilizzi tipicamente sono:
Esecuzione di una stessa funzione a tutte le CPU-cores.
Cambiamento dello stato di componenti dell'hardware, come il TLB, su multiple CPU-cores.
Richieste ad un CPU-core di flaggare il thread corrente di andare in preemption.
In generale quindi gli IPIs permettono di fare tante cose, ma devono essere utilizzati solamente quando sono strettamente necessari perché non hanno una buona scalabilità rispetto all'architettura hardware.
1.1 IPI in Linux
In LINUX i più importanti IPI sono i seguenti:
CALL_FUNCTION_VECTOR: Inviato a tutte le CPUs tranne il sender, permette di forzare le CPU a girare una funzione inviata dal sender. L'interrupt handler è chiamato
call_function_interrupt(). Tipicamente questa funzione è wrappata nella API di più alto livellosmp_call_function(), che permette di eseguire una funzione a tutte le CPUs tranne quella chiamante.RESCHEDULE_VECTOR: Quando ricevuta da un CPU-core, il CPU-core flagga il thread che sta eseguendo in quel momento per dire che deve andare in preemption il prima possibile. Il rispettivo handler è chiamato
reschedule_interrupt().INVALIDATE_TLB_VECTOR: Inviata a tutti i CPU-cores tranne il sender, verifica se i CPU-cores stanno eseguendo un thread presente nello stesso spazio di indirizzamento del thread chiamante e, in caso, forza l'invalidazione della TLB. Il rispettivo handler è chiamato
invalidate_interrupt().
1.2 IPI API
A seguire l'API offerta del kernel LINUX per la gestione degli IPIs:
send_IPI_all(): Invia un IPI a tutte le CPUs (anche il sender)
send_IPI_all();send_IPI_allbutself(): Invia un IPI a tutte le CPUs tranne il sender
send_IPI_allbutself();send_IPI_self(): Invia un IPI al sender
send_IPI_self();send_IPI_mask(): Invia un IPI ad un gruppo di CPU specificate da una bitmask.
send_IPI_mask();
1.3 Sequentialization of IPIs
Andiamo adesso a considerare il problema di come accordare le richieste di IPI che dipendono in modo non-deterministico da una zona di memoria condivisa. Un esempio di questo tipo di IPI è il CALL_FUNCTION_VECTOR, in quanto l'indirizzo della memoria da chiamare può essere arbitrario, e dunque i CPU che ricevono l'interrupt devono andare a leggere l'indirizzo della funzione da eseguire in qualche zona di memoria condivisa tra i vari CPU-cores.
In generale per passare i parametri relativi ad un IPI si utilizzano delle locazioni di memoria condivisa pre-determinate.
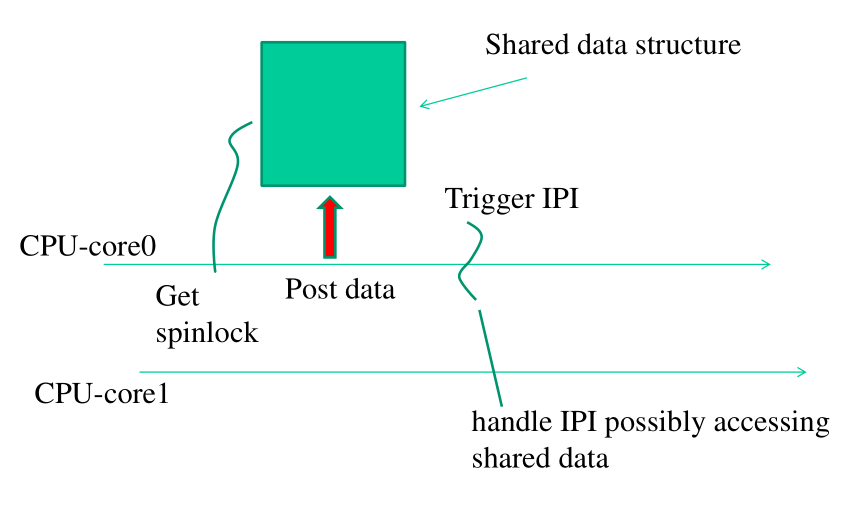
Dato però che abbiamo una sola zona di memoria condivisa per passare i parametri tra CPU-cores, non possiamo gestire più di una richiesta di CALL_FUNCTION_VECTOR. Gli IPI devono quindi essere sequenzializzati.
Per ottenere questo si utilizzano degli spin-locks. In particolare, il primo CPU-core che accede alla zona di memoria condivisa prende uno spin_lock sulla memoria, posta i parametri necessari per soddisfare la sua richiesta, e poi comincia ad inviare richieste IPI. Tutti gli altri CPU-cores saranno quindi bloccati nel momento in cui provano a prendere il lock.
int smp_call_function(void (*_func)(void *info), void* _info, int wait) { WARN_ONN(irqs_disabled()); spin_lock_bh(&call_lock); atomic_set(&scf_started, 0); // count cpu-cores that started // handling the IPI atomic_set(&scf_finished, 0); // count cpu-cores that terminated // handling the IPI func = _func; info = _info; for_each_online_cpu(i) os_write_file(cpu_data[i].ipi_pipe[1], "C"; 1); // Wait for all cpus to start handling the IPI while(atomic_read(&scf_started) != cpus) barrier(); // If wait is enabled then we have a syncronous handling of the IPI, // that is have to wait all cpus to finish handling the IPI. if(wait) while(atomic_read(&scf_finished) != cpus) barrier(); spin_unlock_bh(&call_lock); return 0; }
1.4 Preemption Effects of IPIs
L'utilizzo degli IPI relativi alla può avere degli effetti sulla correttezza/consistenza, e sulla performance.
Per quanto riguarda la correttezza in particolare, potremmo avere dei problemi con blocchi di codice che fanno riferimento a della memoria CPU-specific. Se durante l'esecuzione di questi blocchi di codice il CPU-core riceve richieste di preemption da parte di altri CPU-core infatti, quando il thread riprendere la sua esecuzione, potrebbe aver cambiato CPU, e questo potrebbe portare a problematiche varie nella logica di indirizzamento del programma.
Problemi relativi alla performance possono invece essere
conseguenza dell'utilizzo della funzione
smp_call_function() . Notiamo infatti che la smp_call_function()
deve necessariamente girare con gli interrupts abilitati per
evitare situazioni di deadlock. Ovviamente non possiamo rischiare
di avere un context-switch mentre il thread esecuzione sta
eseguendo la funzione smp_call_function() . Dunque, per far si di
non disabilitare gli interrupts, ma di disabilitare la preemption,
vengono utilizzati i per-cpu preemption counter.