AOS - 31 - VIRTUAL FILE SYSTEM I
Lecture Info
Data:
Sito corso: link
Slides: AOS - 8 VIRTUAL FILE SYSTEM
Progresso unità: 1/4
Argomenti:
Introduzione:
1 File System Basics
Un file system, ovvero una collezione di oggetti di I/O con i relativi dati e meta-dati, può essere rappresentato in due modi diversi:
In RAM: Può essere una rappresentazione parziale o piena della struttura e del contenuto corrente del file system.
On device: È una rappresentazione completa della struttura e del contenuto del file system, ma può essere anche non aggiornata rispetto a quella salvata in RAM.
Le operazioni che possiamo effettuare su un file system si dividono in due gruppi:
Quelle FS (File System) independent: sono tutte le operazioni che non dipendono dal particolare file system utilizzato e che quindi manipolano principalmente meta-dati. Queste operazioni indipendenti formano un layer di interfacciamento verso altri sistemi più interni.
Quelle FS dependent: sono tutte le operazioni che codificano la particolare logica con cui accediamo e manipoliamo i dati contenuti nei vari dispositivi di I/O.
Per raccordare queste strutture diverse tra loro abbiamo che ogni oggetto di I/O è rappresentato da una struttura dati che incapsula riferimenti ai particolari moduli da utilizzare per interagire con il particolare oggetto di I/O. Così facendo è possibile avere due oggetti rappresentati dalla stessa struttura dati in RAM, ma che puntano ad operazioni diverse, e che quindi vengono gestiti in modo diverso.
I drivers sono implementati da tabelle di puntatori a funzioni che permettono di interagire con il particolare dispositivo gestito dal driver. Possiamo quindi avere più drivers in memoria, un driver per ogni dispositivo che vogliamo gestire.
1.1 Virtual File System
L'idea di un Virtual File System (VFS) è quella di gestire oggetti di I/O diversi da semplici file o cartelle come se fossero file.
Per ogni I/O device abbiamo un relativo driver che ci permette di modificare lo stato del device andando a manipolare le strutture dati associate al device. Eventualmente possiamo poi flushare il cambiamenti anche in altri dispositivi di memoria, come ad esempio un hard disk. I dispositivi possono essere sia software che hardware. Classici dispositivi software sono:
Pipes e FIFO
sockets
Lo schema generale si basa quindi sull'utilizzo di interfacce FS indipendent che puntano ad interfacce sempre più vicine al dispositivo che vogliamo manipolare.
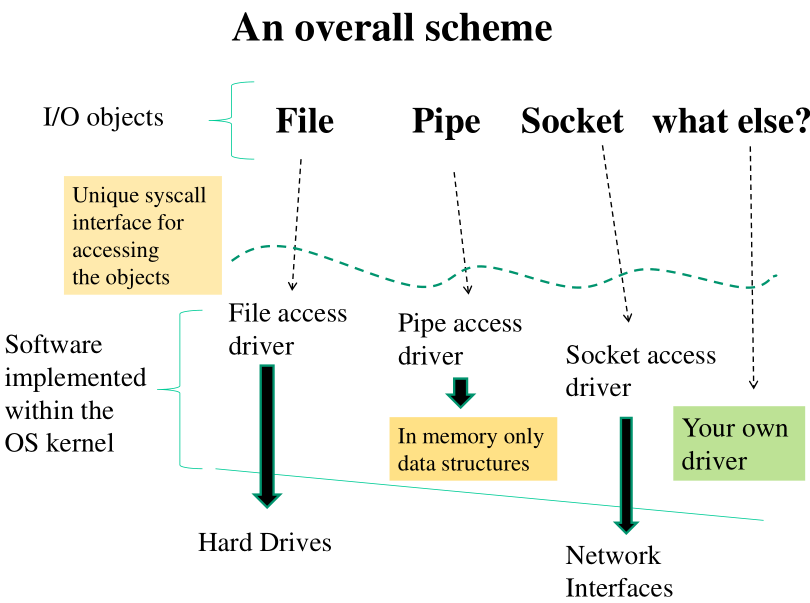
1.2 Example: True files
I files reali sono oggetti di I/O che hanno una rappresentazione, eventualmente non aggiornata, su un hard drive. Tra i moduli software utilizzati per gestire correttamente i files reali troviamo sicuramente i seguenti
Una funzione che legge il device superclock. Il device superblock contiene dei metadati relativi al filesystem utilizzato. In particolare ci dice quali file esistono e dove si trovano nel disco.
Una funzione che legge i singoli blocchi del dispositivo per portare i files all'interno di un buffer della memoria.
Funzione di scrittura per flushare il contenuto modificato nei file dalla memoria fisica alla memoria esterna.
Un insieme di funzioni per lavorare sul blocco di dati caricati nella memoria fisica.
1.3 Block Drivers and Char Drivers
All'interno di un file system abbiamo una separazione di drivers in due famiglie:
I block-device drivers, che permettono di pilotare block-devices, ovvero dispositivi che hanno una granularità a blocchi di una dimensione fissa di bytes.
Tipicamente un block-device driver viene utilizzato per pilotare un dispositivo fisico, anche se può comunque essere utilizzato per pilotare dispositivi virtuali (software).
I char-device drivers che permettono di pilotare char-devices, ovvero dispositivi che possono essere visti come flussi di bytes e lavorano con una granularità del singolo byte.
Osserviamo come questi due non sono gli unici device drivers che abbiamo in un sistema moderno, in quanto i meta-dati associati ai vari oggetti di I/O possono essere associati a dei particolari drivers. Il problema fondamentale da risolvere in questo contesto è quindi quello di far capire ad una system call che lavora con il VFS qual è l'effettivo driver da utilizzare a seconda dell'oggetto con cui stiamo lavorando.
2 superblock_read()
Per gestire un particolare file system necessitiamo di una funzione in grado di leggere il superblocco del file system che vogliamo supportare. Questa funzione può eventualmente fare riferimento ad un block-device driver, che non fa altro che interagire con il dispositivo e copiare il superblocco in memoria.
Quando la funzione superblock_read() viene chiamata, il suo compito
principale è quello di iniziare ad istanziare i metadati per la
gestione di quel particolare file system. Tale funzione può essere
altamente configurata per scegliere varie cose, tra cui:
Il driver da utilizzare,
L'hard drive che vogliamo leggere
Leggere il superblocco da un dispositivo fisico utilizzando un device driver descrive il caso più comune di file systems, ovvero quelli che sono rappresentati completamente su un dispositivo hardware. Esistono però altri file system, ovvero quelli che sono rappresentati in RAM.
Per gestire correttamente tutti i filesystem, il kernel necessita di almeno un filesystem che è rappresentato completamente in RAM. Abbiamo quindi una gerarchia di filesystems, che inizia da un file system che vive solo ed esclusivamente in RAM.
La funzione di lettura del superblocco relativo ad un filesystem rappresentato completamente in RAM non necessita l'interazione con nessun block-device driver. Quando viene invocata, la funzione alloca il superblocco con una struttura pre-determinata già presente nella memoria.
3 VFS Startup in LINUX
Il VFS viene inizalizzato in linux tramite l'esecuzione di
vfs_caches_init() , che a sua volta chiama init_roofs() e
init_moun_tree() .
vfs_caches_init()
mnt_init()
init_rootfs();
init_mount_tree()
Globalmente queste due funzioni (init_rootfs e init_mount_tree)
istanziano il file system in memory, che prende il nome di Rootfs e
che viene utilizzato come radice per tutti gli altri file
systems. Altri filesystems che vengono supportati, oltre a Rootfs,
sono i filesystems della famiglia Ext . Un filesystem è supportato
solamente quando ho una funzione che legge il superblocco per quel
particolare filesystem.
Notiamo che tramite l'opzione di compilazione ALL_NO_CONFIG=true è
possibile configurare Linux in modo da evitare la gestione del
VFS. In questo caso però tutte le attività che vorremmo fare con il
kernel devono essere necessariamente pre-codificate. Un possibile
caso d'uso sono le versioni embedded del kernel per motivi di
performance.
4 struct file_system_type
In LINUX abbiamo una lista che mantiene i puntatori alle funzioni in
grado di leggere i vari superblocchi supportati dal sistema. La
struttura dati che rappresenta la descrizione di un particolare file
system è la struttura file_system_type , definita in
include/linux/fs.h .
La struttura è codificata come segue:
struct file_system_type { // Identifica il tipo di file-system associato a // questi meta-dati. const char *name; inst fs_flags; // .... // Puntatore alla funzione di lettura del superblocco. struct super_block *(*read_super) (struct super_block *, void *, int); // Dato che è possibile sviluppare la logica per la gestione di un // filesystem all'interno di un modulo, possiamo puntare al modulo // che contiene tale logica. // // Questo viene utilizzato nel momento in cui vogliamo smontare il // modulo. Infatti, se vogliamo smontare il modulo ma il file system // è ancora utilizzato da altri thread del sistema, allora non // possiamo farlo. struct module *owner; // .... };
Nelle versioni più recenti del kernel la funzione di lettura del superblocco è chiamata mount.
struct file_system_type { const char *name; int fs_flags; struct dentry *(*mount) (struct file_system_type *, int, const char *, void *); // ... };
Oltre al nome, è stata anche cambiata l'interfaccia della funzione
di lettura del superblocco. In particolare il valore ritornato non è
più un super_block* , ma è una dentry * . Notiamo però che tramite la
dentry è possibile risalire al superblocco per il filesystem.
Il terzo argomento invece, const char *, è una stringa che identifica in modo univoco l'istanza di driver da utilizzare per leggere il superblocco.
5 Linking RootFS
Durante la fase di compilazione viene definita nel file
fs/ramfs/inode.c una istanza della struttura file_system_type che
contiene i meta-dati relativi al filesystem Rootfs. Inizialmente
però questa variabile non è collegata nella lista dei filesystem
supportati. Quando inizializziamo il sistema la andiamo a collegare
alla lista.
Esistono delle API apposite che ci permettono di linkare/rimuovere i meta-dati per la gestione di uno specifico tipo di filesystem. Ad esempio per gestire un nuovo file system abbiamo la seguente funzione
// linka i meta-dati per la gestione di un nuovo filesystem all'interno di LINUX. int register_filesystem(struct file_system_type *);
Questa lista viene utilizzata in vari casi, tra cui:
Quando inseriamo una pennetta.
Durante la fase di start-up, per vedere quali meta-dati sono compatibili con il root filesystem configurato durante l'installazione. Infatti, quando installiamo LINUX, ci viene chiesto quale filesystem utilizzare per il rootfs.
La funzione init_rootfs() non fa altro che linkare la tabella
presente all'interno del kernel (definita a compile time) per
supportare il filesystem rootfs.
int __init init_roofs(void) { // ... return register_filesystem(&rootfs_fs_type); }
La funzione init_rootfs() quindi non invoca la funzione di lettura
del superblocco, ma semplicemente indica al sistema che da quel
momento in poi è possibile supportare il relativo filesystem. La
creazione e il montaggio del RootFS viene poi fatto dalla funzione
init_mount_tree() .
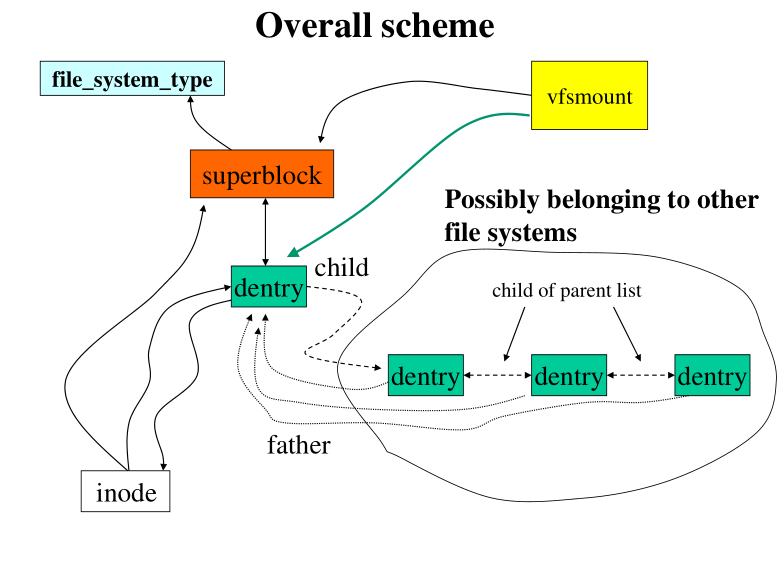
6 Data Structures for VFS
Le strutture dati necessarie per gestire un file system sono le seguenti:
struct vfsmount
struct super_block
struct inode
struct dentry
Le strutture dati vfsmount e super_block hanno una sola istanza in
memoria per file system che sto gestendo. Le altre invece, inode e
dentry , hanno una istanza in memoria per ogni oggetto di I/O
presente nel file system. Lo schema da avere in mente è il seguente
In particolare quindi init_mount_tree() alloca in memoria una
istanza di ogni struttura dati, in quanto stiamo dicendo che
possiamo supportare il rootFS, e inoltre che esiste almeno un
elemento di I/O relativo a tale file system, che è la root, ovvero
lo '/'.
6.1 struct vfsmount
Nella struttura vfsmount è presente un puntatore ad un altro
elemento vfsmount , che rappresenta il parent, ovvero il file system
da cui arriviamo. Abbiamo anche una lista sempre di puntatori a
vfsmount . In questo modo possiamo costruire delle gerachie tra file
systems.
struct vfsmount { struct list_head mnt_hash; // Points to the file system we are mounted on, that is the mount // point of the parent fs. struct vfsmount *mnt_parent; struct dentry *mnt_mountpoint; struct dentry *mnt_root; // Puntatore al superblocco del filesystem. struct super_block *mnt_sb; // Lista di childs che dipendono da me. struct list_head mnt_mounts; struct list_head mnt_child; // Conta il numero di thread che stanno lavorando sugli oggetti di // I/O all'interno del filesystem. atomic_t mnt_count; int mnt_flags; // Nome del dispositivo il cui driver è stato utilizzato per andare // a leggere il superblocco e istanziare in memoria questi // meta-dati. // // Esempio: /dev/dsk/hda1 char *mnt_devname; };
Nella versione più recente del kernel la struttura è stata molto compattata.
struct vfsmount { struct dentry *mnt_root; struct super_block *mnt_sb; int mnt_flags; } __randomize_layout;
6.2 struct super_block
struct super_block { // ... // puntatore al file system type all'interno della lista dei file // system gestiti. struct file_system_type *s_type; // puntatore alla tabella che contiene i riferimenti alle operazioni // che gestiscono il superblocco, ovvero al driver del superblocco. // // Il driver puntato permette di lavorare su questo file system // tramite un FS indipendent layer. struct super_operations *s_op; // ... // Punta alla dentry associata alla root del filesystem. struct dentry *s_root; // ... // Lista di dirty inodes, ovvero di inodes associati ad oggetti che // sono stati modificati e che devono quindi essere flushati // nell'hard drive. struct list_head s_dirt; // ... // Notiamo che la struttura del superblocco deve essere indipendente // dal particolare filesystem utilizzato. Sappiamo però anche che // filesystem diversi memorizzano diverse informazioni. Per mettere // d'accordo queste cose utilizziamo la union. union { struct minix_sb_info minix_sb; struct ext2_sb_info ext2_sb; struct ext3_sb_info ext3_sb; // ... void *generic_sbp; } u; // ... }
6.3 struct dentry
La dentry permette di associare un filename ad ogni oggetto di I/O presente nel nostro sistema.
struct dentry { // Puntiamo al nostro inode. struct inode * d_inode; // Puntiamo alla dentry associata al nostro parent. struct dentry *d_parent; // Puntatore al driver per gestire le dentry. A seconda del tipo di // elemento di I/O che questa struttura dati sta rappresentando, un // diverso driver verrà utilizzato. struct dentry_operations *d_op; // Root of the dentry tree. struct super_block *d_sb; // Buffer di caratteri. Contiene il nome dell'oggetto di I/O se // quest'ultimo è di lunghezza limitata. Altrimenti il nome viene // scritto in un buffer esterno, e questa tabella viene modificata // per puntare al buffer esterno. // // In ogni caso questo campo punta sempre al nome associato // all'oggetto di I/O. unsigned char d_iname[DNAME_INLINE_LEN}; };
6.4 struct inode
Quando stiamo arrivati all'i-node, non ci sono più ulteriori
meta-dati, ma rimangono solo i dati. Questo significa che a partire
da questa struttura dati devo essere in grado di identificare i
drivers che utilizzerò poi per lavorare con i dati effettivi. A
tale fine in questa struttura è presente un pointer alla struttura
struct file_operations .
struct inode { struct list_head i_dentry; // ... uid_t i_uid; gid_t i_gid; // ... // Punta al particolare driver di questo inode. Questo driver lavora // sui meta-dati dell'oggeto di I/O. struct inode_operations *i_op; // Riferimento al driver che lavora sull'oggetto di I/O. struct file_operations *i_fop; struct super_block *i_sb; wait_queue_head_t i_wait; // ... union { // ... struct ext2_inode_info ext2_i; struct ext3_inode_info ext3_i; // ... struct socket socket_i; // .... } u; };
7 Randomize Layout in Structs
A partire dal kernel 4.x, è stata introdotta la possibilità di
randomizzare i campi di una tabella tramite la keyword
__randomized_layout . Abbiamo visto un esempio di questo nella
definizione della struttura dati vfsmount
struct vfsmount { // ... } __randomized_layout;
Se non utilizziamo questa keyword, durante la compilazione sintassi della forma
<structure> -> <field> <structure> . <field>
viene risolta dal compilatore tramite delle regole determinate per generare del codice macchina in grado di ottenere il giusto displacement per accedere ai vari campi della struttura.
Tramite l'introduzione della keyword __randomized_layout , i campi
della tabella vengono mescolati tra loro, e la tabella viene
modificata andando ad aggiungere del padding. Questo re-shuffle
viene effettuato a tempo di compilazione secondo una regola
pseudo-randomica. Il layout randomizzato viene utilizzato nei
seguenti casi:
A richiesta, tramite la keyword
__randomized_layout.Di default, su tutte le strutture che contengono solo function pointers (a.k.a. i drivers). Tramite la keyword
__no_randomized_layoutè possibile disattivare il re-shuffle dei campi della tabella.
8 Initializing the RootFS instance
I tasks principali che vengono eseguiti dalla funzione
init_mount_tree() sono i seguenti:
Allocazione delle quattro strutture dati principali per Rootfs.
Linkaggio delle strutture dati allocate.
Settaggio del nome "/" per il root del file system.
Linkaggio tra l'IDLE_PROCESS e Rootfs.
I prime tre tasks vengono effettuati dalle funzione do_kern_mount() ,
mentre l'ultimo task viene effettuato tramite le funzioni
set_fs_pwd() e set_fs_root() .
Il codice effettivo è il seguente
static void __init init_mount_tree(void) { struct vfsmount *mnt; struct namespace *namespace; struct task_struct *p; mnt = do_kern_mount("rootfs", 0, "rootfs", NULL); if (IS_ERR(mnt)) panic("Can't create rootfs"); // ... set_fs_pwd(current->fs, namespace->root, namespace->root->mnt_root); set_fs_root(current->fs, namespace->root, namespace->root->mnt_root); }
8.1 Process Working Directory and Root Directory
Notiamo a questo punto che nei TCB (Thread Control Block) sono presenti dei puntatori che ci permettono di correlare le informazioni del thread alle informazioni relative ai vari file systems con cui il thread può interagire. In particolare abbiamo due informazioni cruciali:
process working directory (pwd): Questa directory viene utilizzata ogni volta che il thread chiama una system call utilizzando un path relativo. Per impostare questa cartella viene utilizzata la funzione
set_fs_pwd().root directory (root): Rappresenta il punto più alto del filesystem in cui il thread può lavorare. Viene settata con la funzione
set_fs_root().
9 FS Mounting and Namespaces
Nei kernel moderni possiamo eseguire dei collegamenti flessibili
rispetto alla visione che un thread ha dell'organizzazione
gerarchica dei file systems del sistema. In particolare possiamo far
vedere ad un thread solamente una parte della rappresentazione
globale del file system. Questo è il concetto di namespace che, come
per il namespace visto a livello di threads, è supportato anche a
livello di I/O.
I namespaces sono limitati all'istanza del particolare file system. Questo vuol dire che se un TCB vede un elemento all'interno dell'istanza di un file system gestita nel vfs, allora li vede tutti. Potrebbe comunque non vedere altri file systems che sono montati in altri punti del sistema.
Ad ogni thread associo la lista di mount points visibili dal thread. Le funzioni che operano sui file verificano quindi se il thread che ha chiamato la funzione è in grado di vedere quel particolare mounting point.
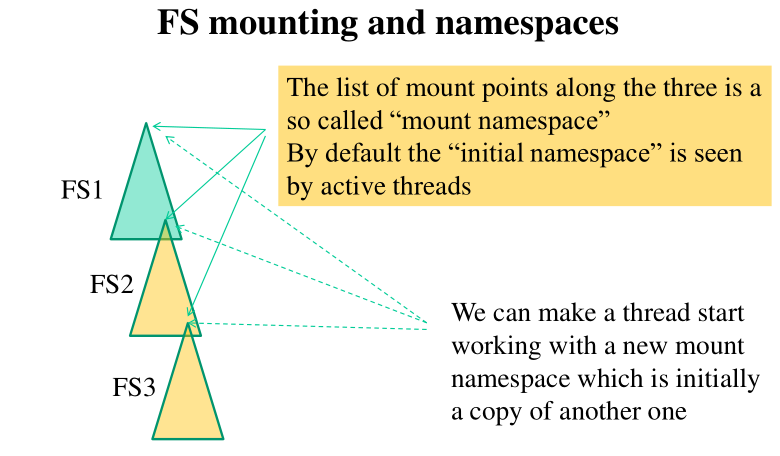
Tramite la system call clone() e il parametro CLONE_NEWNS possiamo
creare un nuovo thread che contiene come lista di montaggio la copia
di quella del parent. Se nel futuro il parent farà il montaggio di
altre porzioni del file system, il child non sarà in grado di vedere
queste porzioni.
La chiamata unshare(int flags) ci permette di cominciare a lavorare
con una copia della lista di montaggio che prima condividevamo con
altri thread. In questo modo siamo in grado di creare dei nuovi
namespace senza necessariamente creare nuovi thread.