AOS - 32 - VIRTUAL FILE SYSTEM II
1 Lecture Info
Data:
Sito corso: link
Slides: AOS - 8 VIRTUAL FILE SYSTEM
Progresso unità: 2/4
La lezione passata avevamo introdotto le varie strutture dati e gli associati drivers necessari per gestire il VFS. Avevamo poi iniziato a descrivere il collegamento tra i thread e il vfs tramite il concetto di mount list, che implementa un meccanismo di namespacing.
2 Threads e VFS
2.1 Isolamento a grana fine
La mount list associata ad un thread definisce quali sono i file system visibili da quel thread. Come facciamo però a escludere solamente una parte di un filesystem dalla visione di un thread?
Per escludere gli oggetti intermedi si utilizza il concetto di root_directory. Ogni thread infatti ha due informazioni fondamentali: la process_working_directory, ovvero la cartella in cui sta attualmente lavorando il thread, e la root_directory, che indica il punto del VFS a partire dalla quale il thread può scendere e visitare gli oggetti di I/O a lui visibili.
La root_directory è quindi specifica per ogni thread. Quando un thread crea un altro thread, la root_directory può essere ereditata. Ovviamente queste proprietà sono garantite solamente se lavoriamo con le API offerte dal kernel.
2.2 struct fs_struct
Le informazioni relative al VFS viste da un singolo thread sono
memorizzate nel campo struct fs_struct *fs (file system struct)
presente nel TCB del thread. La versione classica della tabella è
definita nel file include/fs_struct.h , ed è la seguente
struct fs_struct { // Numero di threads che stanno utilizzando questa tabella. atomic_t count; // Questa tabella può essere condivisa tra vari threads. Dobbiamo // quindi sincronizzare l'accesso tramite un read/write // lock. Ricordiamo che il read/write lock offre un accesso // concorrente a più readers, ma quando un writer prende il lock, // sia gli altri writers che gli altri readers sono bloccati. rwlock_t lock; int umask; // Identifica le dentry relative a noi per la visibilità e la // costruzione di path relativi. struct dentry *root, *pwd, *altroot; // struct vfsmount *rootmnt, *pwdmnt, *altrootmnt; }
Andando nelle versioni più recenti le varie informazioni sono state compattate. In particolare non abbiamo più dentry e vfsmount seperati per la root e la pwd, ma bbiamo un'unica struttura chiamata struct path.
struct fs_struct { int users; spinlock_t lock; seqcount_t seq; int umask; int in_exec; struct path root, pwd; } __randomize_layout;
3 File Descriptor Table
Una file descriptor table è tipicamente strutturato un array di pointers. Questa struttura serve per associare un canale di I/O, identificato da un codice numerico, all'oggetto di I/O con cui stiamo lavorando in quel canale. Tramite la file descriptor table è possibile utilizzare le system call tramite i codici numerici per identificare particolari sessioni di I/O.
La sessione identificata dall'id e puntata dalla tabella è a sua volta una tabella che rappresenta la sessione e da cui possiamo poi risalire alla dentry e all'i-node dell'oggetto di I/O con cui stiamo interagendo.
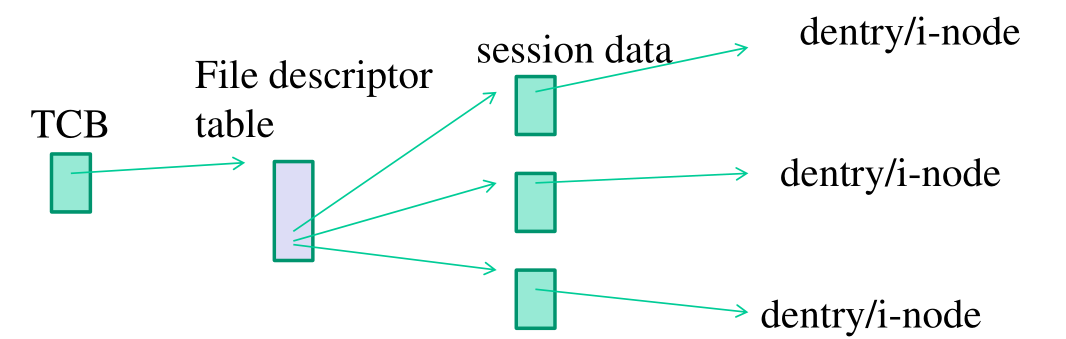
La struttura dati che la file descriptor table è strutturata come segue
struct files_struct { // Tutti i thread in un processo condividono la stessa file // descriptor table. // // Conta il numero di thread che la stanno utilizzando. atomic_t count; rwlock_t file_lock; int next_fd; // Puntatore all'array che contiene puntatori a oggetti esterni di // tipo struct file. Le struct file sono le strutture dati che // rappresentano le sessioni di I/O. // // Di default questo puntatore punta al campo fd_array. Ovvero di // default il numero di sessioni massimo è limitato dal valore di // NR_OPEN_DEFAULT. // // Se voglio avere più sessioni di I/O posso utilizzare fd per // puntare ad un altro array, di una taglia più grande. // // Tramite la facility ulimit() dalla shell possiamo aumentare il // numero di default di sessioni attive. struct file **fd; fd_set *close_on_exec; // Pointer ad una bitmap che ci dice quali sessioni sono occupate e // quali sono libere. fd_set *open_fds; // Array delle sessioni di I/O di default. struct file *fd_array[NR_OPEN_DEFAULT]; };
Per rappresentare una specifica sessione di I/O invece utilizziamo
la struct file , che tipicamente ha la seguente forma
// 2.4 version struct file { // ... // metadati dell'oggetto di I/O che stiamo gestendo. struct dentry *f_dentry; // Driver da utilizzare per operare sull'oggetto all'interno di // questa sessione. struct file_operations *f_op; // Numero di thread che hanno aperta la sessione. atomic_t f_count; // Modo in cui abbiamo aperto la sessione: read/write. mode_t f_mode; // Indica in che posizione dell'oggetto di I/O attualmente stiamo // lavorando. In particolare ci dice in che punto dello stream di // bytes dovremmo leggere o scrivere all'oggetto di I/O. loff_t f_pos; // ... };
4 VFS API Layering
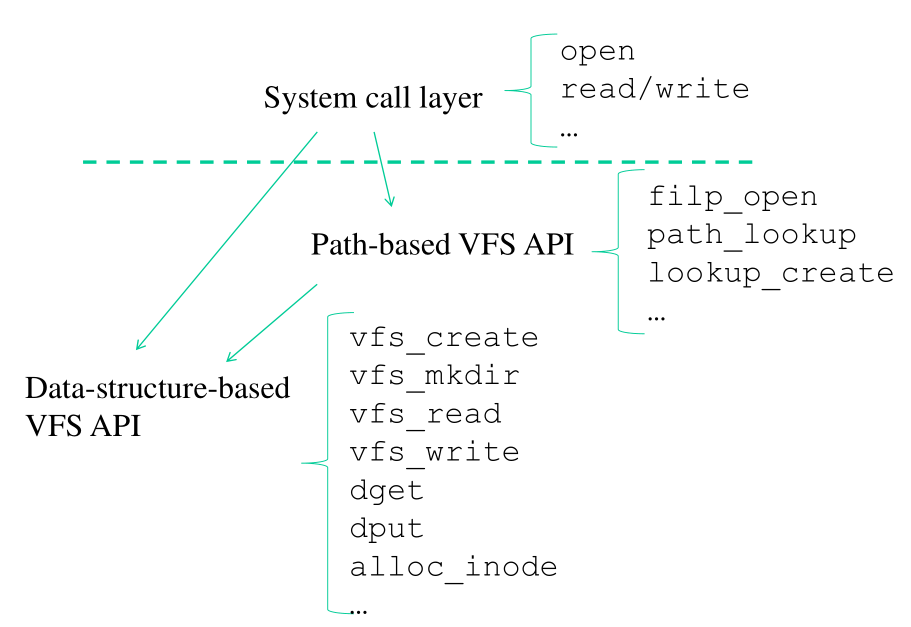
All'interno dell'architettura del virtual file system (VFS) abbiamo varie entità in gioco. Per ogni entità necessitiamo dunque di particolari API. Possiamo dividere le API relative al VFS in tre classi, a seconda del parametro di input:
System call layer (codici numerici): API che prendono come parametri gli identificativi della sessione di I/O con cui stiamo lavorando.
Path-based VFS layer (stringhe): API che prendono come parametro una path passata come stringa.
Data structure based VFS layer (indirizzi logici): API che utilizzano i puntatori alle strutture dati per la gestione del VFS.
Le relazioni tra i vari layer sono le seguenti
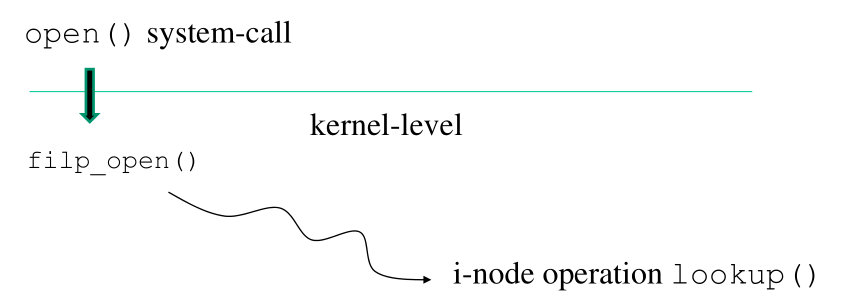
4.1 Example #1: Path-based API
Per aprire una sessione di I/O all'interno del kernel è presente la funzione
struct file *filp_open(const char *filename, int flags, int mode);
che ritorna l'indirizzo della struttura dati che rappresenta la
sessione di I/O appena creata. Il compito principale della
filp_open() è capire se esiste un oggetto di I/O con quel
particolare nome. In particolare quindi deve andare a vedere la
stuttura dell'archivio presente per vedere se è presente un oggetto
con quel nome. Dato però che l'archivio può essere rappresentato
solo parzialmente in memoria, per tirare dentro tutte le
informazioni dell'archivio di interesse la filp_open() dovrà
utilizzare l'operazione lookup() offerta dal driver degli i-nodes.
4.2 Example #2: Data-structure based API
L'API che invece lavora con gli indirizzi logici definisce le seguenti funzioni:
vfs_mkdir(): Crea un i-node e lo associa alla dentry passata. Il parametro dir viene utilizzato per linkare sull'i-node parent. Viene Utilizzata per creare una directory.
int vfs_mkdir(struct inode *dir, struct dentry *dentry, int mode);
vfs_create(): Utilizzata per creare un oggetto di I/O generico.
int vfs_create(struct inode *dir, struct dentry *dentry, int mode);
dget(): Permette di prendere il possesso di una dentry.
static __inline__ struct dentry *dget(struct dentry *dentry);
dput(): Rilascia il possesso di una dentry.
void dput(struct dentry *dentry);
vfs_read(): qui
__uservuol dire che stiamo puntando ad un buffer user-space.ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos);
5 Device-Drivers Table
All'interno di molte delle strutture dati viste per gestire il VFS abbiamo trovato più e più volte dei puntatori a delle tabelle di funzioni, ovvero a dei drivers. A seconda della tipologia dell'oggetto in questione abbiamo poi detto che possiamo avere drivers diversi. Come facciamo quindi ad associare ad una determinata tipologia di oggetto di I/O un particolare driver?
Per risolvere questo problema si utilizza una device-drivers table, ovvero una tabella che registra tutti i driver offerti dal sistema.
È possibile avere più device-drivers tables in un sistema. Tipicamente ne abbiamo almeno due: una che registra tutti i char-device drivers, e una che registra tutti i block-device drivers.
Per quanto riguarda i drivers relativi a strutture dati interne del kernel, come ad esempio i drivers delle dentry, o degli i-nodes, o dei superblocchi, non abbiamo delle tabelle separate in quanto abbiamo per ogni struttura dati un solo possibile driver, in quanto le operazioni contenute nel driver sono FS indpendent.
I drivers possono essere ereditati nel caso in cui creiamo un nuovo oggetto di I/O che si trova nello stesso file system del parent che è omogeneo al parent.
5.1 Major Numbers
Oltre all'utilizzo della device-drivers table, ad ogni driver si associa un unico identificativo, che prende il nome di major number.
Il major number all'interno di una architettura VFS è il codice numerico che associamo ad una specifica istanza di driver. L'indirizzo specifico del driver associato ad un major number viene ottenuto utilizzando la device-drivers table.
In modo dinamico è poi possibile modificare la struttura della device-drivers table, andando ad aggiungere o rimuovere drivers dal sistema.
5.2 Drivers a Istanza Multipla
Notiamo che i drivers devono essere progammati internamente per gestire eventuali situazioni di concorrenza.
Nel caso in cui ho due oggetti diversi di I/O che però vivono nello stesso file system e che sono omegenei, allora questi oggetti di I/O faranno riferimento allo stesso driver. Se ho due thread concorrenti che lavorano su questi oggetti, il driver deve quindi gestire questa situazione di concorrenza.
Possiamo anche avere situazioni in cui il driver è a istanza singola, e quindi non permette di essere utilizzato da più threads. Questa tipologia di drivers però non è scalabile, e quindi viene utilizzata solo nei casi in cui è strettamente necessasrio. Tipicamente i dati che i driver devono toccato sono identificati dall'oggetto di I/O che ha chiamato il driver. A tale fine viene utilizzato il concetto di minor number
5.3 Minor Numbers
Il minor number viene utilizzato dal driver per identificare oggetti di I/O omogenei tra loro. Tramite questo identificativo il driver è poi in grado di capire qual è la sessione di I/O con cui si sta lavorando, e da quella è in grado di scendere e processare i metadati del particolare oggetto con cui stiamo lavorando.
6 Oggetti di I/O
Il VFS di LINUX ci permette di gestire le seguenti tipologie di oggetti di I/O:
Directory
File
Char Device
Block Device
(named) Pipe
A seconda della tipologia di oggetto può essere facile capire il driver da utilizzare per gestire l'oggetto. In particolare per le directories, i files, e le (named) pipes, è molto semplice capire qual è la tipologia di driver da utilizzare.
Per quanto riguarda i char devices e i block devices invece, non è sempre facile capire quali sono i drivers da utilizzare per interagire con il particolare device. Notiamo infatti che un char device è semplicemente visto come uno stream di bytes da cui possiamo leggere o scrivere, mentre un block device è visto come un dispositivo da cui possiamo leggere e scrivere con la granularità del blocco.
6.1 mknod() system call
Tramite il comando shell mknod siamo in grado di creare un oggetto
di I/O in un punto arbitrario dell'architettura del VFS. La system
call relativa è la seguente
int mknod(const char *pathname, mode_t mode, dev_t dev);
dove,
mode_t mode: specifica i permessi da utilizzare e il tipo di nodo da creare. Possibili valori sono:
S_IFREG, regular file.
S_IFCHR, char device.
S_IFBLK, block device.
S_IFIFO, x.
pathname: specifica il nome dell'oggetto di I/O che sto creando.
dev_t dev: viene visto solamente se specifichiamo S_IFCHR o S_IFBLK nel parametro mode. In questo caso dev viene utilizzato per passare la combinazione i MAJOR e MINOR numbers.
6.2 Device Numbers in x86
In x86 i device numbers sono rappresentati da bit masks, dove MAJOR corrisponde al least significant byte, e MINOR corrisponde al second least significant byte.
Grazie alla macro MKDEV(ma, mi) siamo in grado di compattare le informazioni sul MAJOR/MINOR number in modo corretto all'interno di una struttura dati. Possiamo quindi avere al più 256 MAJOR numbers e 256 MINOR numbers.
L'utilizzo di MAJOR e MINOR numbers è utile solamente nel caso in cui abbiamo oggetti eterogenei ad altri. Nel caso di file normali non ci interessano i MINOR numbers. In generale la gestione dei MINOR numbers viene gestita a descrizione completa del driver.
6.3 Block-device drivers
Le operazioni offerte dai block-device drivers sono molto poche e basilari. Ciascun block-device driver è registrato da un nome e da una tabella di operazioni. Tutti questi block-device drivers sono poi inseriti in un array.
static struct { const char *name; struct block_device_operations *bdops; } blkdevs[MAX_BLKDEV];
Nel file fs/block_devices.c troviamo le funzioni per registrare e
de-registrare un block device driver
int register_blkdev(unsigned int major, const char *name, struct block_device_operations *bdops); int unregister_blkdev(unsigned int major, const char *name);
La struttura vera e propria dei block-device drivers invece è la seguente
struct block_device_operations { int (*open) (struct inode *, struct file *); int (*release) (struct inode *, struct file *); int (*ioctl) (struct inode *, struct file *, unsigned, unsigned long); int (*check_media_change) (kdev_t); int (*revalidate) (kdev_t); struct module *owner; }
6.4 Char-device drivers
La tabella delle operazioni per i char-device driver è invece molto più ampia e flessibile.
struct device_struct { const char *name; struct file_operation *fops; }; static struct device_struct chrdevs[MAX_CHRDEV];
Nel file fs/devices.c troviamo le funzioni per registrare e
de-registrare i drivers
int register_chredv(unsigned int major, const char *name, struct file_operations *fops); int unregister_chredv(unsigned int major, const char *name);
La struttura vera e propria dei char drivers è la seguente
struct file_operations { struct module *owner; // .... ssize_t (*read) (struct file *, char *, size_t, loff_t *); ssize_t (*write) (struct file *, const char *, size_t, loff_t *); // ... int (*open) (struct inode *, struct file *); // ... };
La open() è la reale operazione che viene chiamata per il setup dei dati dell'oggetto di I/O che voglio utilizzare dopo che i layer superiori hanno già verificato che quel particolare oggetto esiste.
7 MAJOR-MINOR-MANAGEMENT/baseline-char-dev.c
In questo running example vediamo la definizione di un semplice
driver a singola istanza, che non fa altro che stampare dei messaggi
nella console dmesg . Iniziamo quindi definendo le variabili globali
di interesse
MODULE_LICENSE("GPL"); MODULE_AUTHOR("Francesco Quaglia"); #define MODNAME "CHAR DEV" static int dev_open(struct inode *, struct file *); static int dev_release(struct inode *, struct file *); static ssize_t dev_write(struct file *, const char *, size_t, loff_t *); static ssize_t dev_read(struct file *, const char *, size_t, loff_t *); #define DEVICE_NAME "my-new-dev" /* Device file name in /dev/ - not mandatory */ static int Major; /* Major number assigned to broadcast device driver */ static DEFINE_MUTEX(device_state);
Segue quindi l'implementazione delle varie funzioni offerte dal driver
dev_open: Questa funziona viene eseguita per aprire la sessione con il driver. Non fa altro che controllare se il mutex è libero, e se il mutex non è libero ritorna l'errore
EBUSY.static int dev_open(struct inode *, struct file *); static int dev_open(struct inode *inode, struct file *file) { // this device file is single instance if (!mutex_trylock(&device_state)) { return -EBUSY; } printk("%s: device file successfully opened\n",MODNAME); //device opened by a default nop return 0; }
dev_release: Questa funzione viene eseguita per chiudere la sessione con il driver, e non fa altro che liberare il mutex precedentemente occupato.
static int dev_release(struct inode *inode, struct file *file) { mutex_unlock(&device_state); printk("%s: device file closed\n",MODNAME); //device closed by default nop return 0; }
dev_write: Questa funzione viene chiamata ogni volta che si prova a scrivere utilizzando il driver. La funzione non fa altro che stampare la coppia (Major, Minor) relativi all'oggeto con cui stiamo lavorando.
static ssize_t dev_write(struct file *filp, const char *buff, size_t len, loff_t *off) { #if LINUX_VERSION_CODE >= KERNEL_VERSION(4, 0, 0) printk("%s: somebody called a write on dev with [major,minor] number [%d,%d]\n", MODNAME,MAJOR(filp->f_inode->i_rdev), MINOR(filp->f_inode->i_rdev)); #else printk("%s: somebody called a write on dev with [major,minor] number [%d,%d]\n", MODNAME,MAJOR(filp->f_dentry->d_inode->i_rdev), MINOR(filp->f_dentry->d_inode->i_rdev)); #endif // return len; return 1; }
dev_read: Questa funzione è uguale alla dev_write.
static ssize_t dev_read(struct file *filp, char *buff, size_t len, loff_t *off) { #if LINUX_VERSION_CODE >= KERNEL_VERSION(4, 0, 0) printk("%s: somebody called a read on dev with [major,minor] number [%d,%d]\n", MODNAME,MAJOR(filp->f_inode->i_rdev), MINOR(filp->f_inode->i_rdev)); #else printk("%s: somebody called a read on dev with [major,minor] number [%d,%d]\n", MODNAME,MAJOR(filp->f_dentry->d_inode->i_rdev), MINOR(filp->f_dentry->d_inode->i_rdev)); #endif return 0; }
Per poter effettivamente registrare il driver dobbiamo incapsulare
le nostre funzioni nella struttura struct file_operations e
registrare il driver al montaggio del modulo tramite la funzione
__register_chrdev , che una volta eseguita ci ritornerà il Major
number assegnato dal kernel al nostro driver.
static struct file_operations fops = { .owner = THIS_MODULE, .write = dev_write, .read = dev_read, .open = dev_open, .release = dev_release }; int init_module(void) { Major = __register_chrdev(0, 0, 256, DEVICE_NAME, &fops); if (Major < 0) { printk("%s: registering device failed\n", MODNAME); return Major; } printk(KERN_INFO "%s: new device registered, it is assigned major number %d\n",MODNAME, Major); return 0; }
Infine, quando togliamo il modulo dal kernel dobbiamo togliere il
driver dalla tabella dei driver. A tale fine eseguiamo la funzione
unregister_chrdev .
void cleanup_module(void) { unregister_chrdev(Major, DEVICE_NAME); printk(KERN_INFO "%s: new device unregistered, it was assigned major number %d\n",MODNAME, Major); return; }
Per utilizzare questo modulo possiamo procedere come segue
make # build kernel object (.ko) sudo insmod insmod baseline-char-dev.ko # insert module
una volta che inseriamo il modulo utilizzando dmesg dovremmo leggere
un messaggio come il seguente
[25258.329217] CHAR DEV: new device registered, it is assigned major number 235
Utilizzando il major number assegnato possiamo quindi creare un nuovo oggetto di I/O con quel particolare major number, in modo da utilizzare il driver creato da noi.
cd /dev/
mknod my-dev c 235 7
Infine, una volta creato l'oggetto di I/O possiamo scrivere e leggere, e il kernel utilizzerà il nostro driver per gestire questi eventi.
echo "Hello" > /dev/my-dev
In dmesg troviamo quindi
[25988.410447] CHAR DEV: device file successfully opened [25988.410467] CHAR DEV: somebody called a write on dev with [major,minor] number [235,7] [25988.410470] CHAR DEV: somebody called a write on dev with [major,minor] number [235,7] [25988.410473] CHAR DEV: somebody called a write on dev with [major,minor] number [235,7] [25988.410476] CHAR DEV: somebody called a write on dev with [major,minor] number [235,7] [25988.410478] CHAR DEV: somebody called a write on dev with [major,minor] number [235,7] [25988.410483] CHAR DEV: device file closed
NOTA BENE: Il fatto che abbiamo una scrittura per ogni carattere
della nostra stringa "Hello" deriva dal fatto che nella funzione
dev_write() del driver ritorniamo sempre 1 .