ISTI - 01 - Concetti Base I
1 Lecture Info
Data:
In questa lezione abbiamo introdotto i concetti basilari relativi alla teoria della probabilità utilizzati durante il corso. Alla fine della lezione abbiamo brevemente discusso le principali distribuzioni a cui faremo riferimento nel corso.
2 Variabili Aleatorie
2.1 Variabili Aleatorie Discrete
Def: Dato uno spazio di probabilità \((\Omega, F, P)\), una variabile aleatoria è una funzione \(X: \Omega \to \mathbb{R}\) *tale che, per ogni \(t \in \mathbb{R}\), si ha che
\[\{w \in \Omega: \,\, X(\omega) \leq t\} \in F\]
Data una variabile aleatoria (v.a.) \(X\), diciamo che \(X\) è una variabile aleatoria discreta se può assumere al più una infinità numerable di valori, ovvero se il range di \(X\), definito come l'insieme dei possibili valori di \(X\), è un insieme numerabile.
Def: Data una v.a. discreta \(X\), chiamiamo densità di probabilità discreta la funzione \(p: \mathbb{R} \to \mathbb{R}^+\) definita come segue
\[\forall x \in \Omega: \,\,\,\, p(x) := P(X = x)\]
Notiamo che,
Per al più un numero finito o una infinità numerabile di valori \(x_1\), \(x_2\), ..., \(x_n\), ... si ha che \(p(x) \neq 0\).
Sommando la probabilità \(p(x)\) al variare di tutti i possibili valori di \(x\) otteniamo \(1\). In formula, \(\sum_n p(x_n) = 1\), dove \(\sum_n p(x_n)\) può essere una somma finita o una serie.
La conoscenza della densità discreta \(p\) ci permette di determinare la legge di \(X\). Infatti, fissato un sottoinsieme \(A \subset \mathbb{R}\), allora otteniamo
\[\begin{split} P(X \in A) &= P(\{\bigcup\limits_{x_i \in A} X = x_i\}) \\ &= \sum\limits_{x_i \in A} P(X = x_i) \\ &= \sum\limits_{x_i \in A} p(x_i) \end{split}\]
Def: Data una v.a. discreta \(X\), chiamiamo funzione di ripartizione la funzione \(F_X: \mathbb{R} \to [0, 1]\) definita come segue
\[\forall t \in \mathbb{R}: \,\,\,\, F_X(t) := P(X \leq t)\]
dove con \(\{X \leq t\}\) intendiamo l'evento \(\{w \in \Omega: \,\, X(w) \leq t\}\).
2.2 Variabili Aleatorie Continue
Data una v.a. \(X\), diciamo che \(X\) è una variabile aleatoria continua se l'insieme dei valori assunti dalla v.a. è un qualsiasi sottoinsieme di \(\mathbb{R}\).
Come nel caso discreto, data una v.a. continua \(X\), possiamo considerare la sua funzione di ripartizione \(F_X: \mathbb{R} \to [0,1]\). Una volta che conosciamo \(F_X(\cdot)\) possiamo calcolare la seguente probabilità
\[P(a < x \leq b) = P(x \leq b) - P(X \leq a) = F(b) - F(a)\]
Def: Data una v.a. continua \(X\), sia \(F_X\) la sua funzione di ripartizione. Diciamo che la funzione \(f: \mathbb{R} \to \mathbb{R}\) è la funzione densità della v.a. \(X\) se, per ogni \(x \in \mathbb{R}\), si ha che
\[F_X(x) = \int\limits_{-\infty}^{\infty} f(t) \,\, dt\]
Una v.a. continua che ha una densità viene anche chiamata assolutamente continua.
Dalla definizione appena data si ha che se \(f(\cdot)\) è la densità di una v.a. \(X\) continua, allora valgono le seguenti proprietà
\(f: \mathbb{R} \to \mathbb{R}^+\), ovvero \(f\) assume solo valori positivi.
\(\int_{-\infty}^{\infty} f(x) \,\, dx = 1\)
Osservazione: La densità \(f\) associata ad una v.a. \(X\) non è unica. Infatti, se \(g\) è un'altra funzione che differisce da \(f\) per un insieme di punti di misura nula, allora gli integrali non cambiano, e dunque anche \(g\) è una densità per \(X\).
Dalla definizione di densità appena data, segue che per ogni \(a, b \in mathbb{R}\) con \(a \leq b\), si ha che
\[P(a \leq x \leq b) = F_X(b) - F_X(a) = \int\limits_a^b f(t) \,\, dt\]
questo significa che, per v.a. continue, il calcolo di eventi del tipo \(\{a \leq x \leq b\}\) può essere ridotto al calcolo di integrali.
Per terminare, notiamo che dalla definizione di densità, se conosciamo la densità \(f_X(\cdot)\) della nostra v.a., possiamo calcolare la funzione di ripartizione tramite il calcolo di un integrale. Viceversa, se conosciamo la funzione di ripartizione \(F_X(\cdot)\), possiamo calcolare la densità \(f_x(\cdot)\) utilizzando il teorema fondamentale del calcolo integrale, che ci dice che se \(F\) è derivabile con derivata continua su tutto \(\mathbb{R}\), allora \(F\) è la funzione integrale della sua derivata \(F'\). Nel nostro caso in particolare significa che
\[f_X(x) = \frac{d F_X(x)}{dx}\]
2.3 Funzioni di Variabili Aleatorie
Molto spesso vogliamo studiare funzioni di variabili aleatorie. Data \(X\) v.a., consideriamo \(Y = g(X)\). Al fine di studiare \(Y\) è utile studiare la sua distribuzione, ovvero la funzione \(F_y(t) := P(Y \leq t)\). Per studiare la distribuzione di \(Y\) può essere molto utile considerare la funzione inversa di \(g(\cdot)\).
A seconda della natura della funzione \(g(\cdot)\), lo studio di \(F_y(t)\) può essere più o meno difficile. Ad esempio, se assumiamo che la funzione \(g(\cdot)\) è una funzione invertibile e non-decrescente, allora le cose si semplificano, in quanto troviamo il seguente risultato
\[\begin{split} P(Y \leq t) &\iff P(g(X) \leq t) \\ &\iff P(X \leq g^{-1}(t)) \\ \end{split}\]
e dunque \(F_y(t) = F_x(g^{-1}(t))\). Sempre nel caso in cui \(g(\cdot)\) è invertibile e non-decrescente ho anche che la densità di \(Y\) è data da
\[f_y(t) = f_x(g^{-1}(t)) \cdot \frac{1}{g^{'}(g^{-1}(t))}\]
Infatti, dato che \(g^{-1}\) è la funzione inversa di \(g\), si ha che \(g(g^{-1}(t)) = t\). Ma allora, prendendo la derivata rispetto a \(t\) da entrambi i lati, otteniamo il seguente risultato
\[\begin{cases} \frac{d}{dt} (g(g^{-1}(t))) &= g^{'}(g^{-1}(t)) \cdot (g^{-1}(t))^{'} \\ \frac{d}{dt} t &= 1 \end{cases}\]
e mettendo insieme i due pezzi otteniamo
\[g^{'}(g^{-1}(t)) \cdot (g^{-1}(t))^{'} = 1 \iff (g^{-1}(t))^{'} = \frac{1}{g^{'}(g^{-1}(t))}\]
3 Formule Standard
Andiamo adesso a presentare una serie di definizioni e risultati standard ripresi dalla teoria della probabilità.
3.1 Valore Atteso
Ricordiamo che se abbiamo una v.a. continua \(X\), il suo valore atteso, se converge, è definito nel seguente modo
\[\mathbb{E}[X] := \int_{-\infty}^{\infty} {x \cdot f_x(x) \,\,\, dx}\]
dove \(f_x(x)\) è la densità della v.a. \(X\).
3.1.1 Formula per \(\mathbb{E}[g(X)]\)
Consideriamo ora la seguente v.a. \(Y = g(X)\). Il valore atteso di \(Y\), utilizzando la definizione appena data, è dato dal seguente integrale
\[\mathbb{E}[Y] = \int_{-\infty}^{\infty}{y \cdot f_y(y) \,\,\, dy}\]
al fine di calcolare tale integrale effettuiamo il cambio di variabili \(y = g(x)\), che ci permette di ottenere
\[\frac{g(x)}{dx} = \frac{dy}{dx} \iff g'(x) = \frac{dy}{dx} \iff dy = g'(x) \,\, dx\]
sostituendo nell'integrale di prima otteniamo quindi
\[\begin{split} \mathbb{E}[Y] &= \int_{-\infty}^{\infty}{y \cdot f_y(y) \,\, dy} \\ &= \int_{-\infty}^{\infty} {g(x) \cdot f_y(g(x)) \cdot g'(x) \,\, dx} \\ \end{split}\]
utilizzando la formula precedentemente dimostrata troviamo che
\[f_y(g(x)) = \frac{f_x(g^{-1}(g(x)))}{g^{'}(g^{-1}(g(x)))} = \frac{f_x(x)}{g^{'}(x)}\]
continuando quindi il calcolo dell'integrale otteniamo
\[\begin{split} \mathbb{E}[Y] &= \int_{-\infty}^{\infty} {g(x) \cdot f_y(g(x)) \cdot g'(x) \,\, dx} \\ &= \int_{-\infty}^{\infty} {g(x) \cdot \frac{f_x(x)}{g^{'}(x)} \cdot g^{'}(x) \,\, dx} \\ &= \int_{-\infty}^{\infty} {g(x) \cdot f_x(x) d_x} \\ &= \mathbb{E}[g(X)] \\ \end{split}\]
Riassumendo, abbiamo dimostrato che se \(Y = g(X)\), allora
\[\mathbb{E}[Y] = \mathbb{E}[g(X)]\]
e quindi ci basta conoscere la densità di \(X\) per poter calcolare la media di una funzione di \(X\), come \(Y = g(X)\).
3.1.2 Formula per \(\mathbb{E}[X^2]\)
Un'altra formula utile nel calcolo dei momenti, ovvero delle media, è la seguente
\[\mathbb{E}[X^2] = \int_{-\infty}^{\infty} x^2 f_x(f) \,\, dx\]
3.2 Varianza e Deviazione Standard
Oltre il valore atteso, una quantità fondamentale di ogni variabile aleatoria è la sua varianza, che intuitivamente ci dice quanto si discostano dal valore atteso i valori effettivi assunti dalla variabile aleatoria che stiamo studiando.
Idealmente la varianza dovrebbe essere definita come il valore atteso delle distanze tra i valori assunti dalla v.a. e il valore atteso di quest'ultima. In formula vorremmo
\[Var[X] = \mathbb{E}[\,\,|X - \mathbb{E}[X] |\,\,]\]
Notiamo però che la funzione \(|\cdot|\), spesso chiamata funzione valore assoluto e definita come segue
\[ |x| := \begin{cases} x & x \geq 0 \\ -x & x < 0 \end{cases}\]
è molto difficile da trattare analiticamente. Necessitiamo dunque di una funzione che non ci darà il valore ideale da noi cercato, ma che è più facile da gestire. Questa funzione è la funzione quadratica \(x^2\). Per questa ragione la varianza viene formalmente definita nel seguente modo
\[Var[X] := \mathbb{E}[(X - \mathbb{E}[X])^2]\]
Notiamo che la varianza è sempre positiva. Infatti, dalla definizione di varianza e di valore atteso, abbiamo che
\[Var[X] = \mathbb{E}[ (X - \mathbb{E}[X])^2 ] = \int\limits_{-\infty}^{\infty} \Big(X - \mathbb{E}[X]\Big)^2 \cdot f_x(X) \,\, dx\]
e dato che la funzione da integrare è sempre \(\geq 0\), abbiamo che l'integrale è sempre \(\geq 0\).
Per finire, notiamo che \(Var[X] = 0\) se e solo se \(X\) è una costante. Dunque, una costante può anche essere vista come una v.a. con varianza \(0\).
A questo punto, per ottenere l'effettiva quantità da noi ricercata, definiamo la deviazione standard, o standard deviation, come la radice quadrata della varianza. Formalmente,
\[SD(X) := \sqrt{Var[X]}\]
La devizione standard è molto simile al valore che vorremmo idealmente, anche se non è completamente uguale a tale valore in quanto \(\sqrt{a^2 + b^2} \neq a + b\).
3.2.1 Formula \(Var[X] = \mathbb{E}[X^2] - \mathbb{E}[X]^2\)
Esiste un modo alternativo per calcolare la varianza, che è ottenuto utilizzando la proprietà di linearità del valore atteso nel seguente modo
\[ \begin{split} Var[X] &= \mathbb{E}[ (X - \mathbb{E}[X]) ^2 ] \\ &= \mathbb{E}[ X^2 - 2X\mathbb{E}[X] + \mathbb{E}[X]^2 ] \\ &= \mathbb{E}[X^2] - \mathbb{E}[2X\mathbb{E}[X]] + \mathbb{E}[\mathbb{E}[X]^2] \\ &= \mathbb{E}[X^2] - 2\mathbb{E}[X]^2 + \mathbb{E}[X]^2 \\ &= \mathbb{E}[X^2] - \mathbb{E}[X]^2 \\ \end{split}\]
3.3 Disuguaglianza di Jensen
Se \(g(\cdot)\) è una funzione convessa, ovvero se la seconda derivata di \(g(\cdot)\) è positiva, allora abbiamo che
\[\mathbb{E}[g(X)] \geq g(\mathbb{E}[X])\]
4 Distribuzioni Standard
4.1 Distribuzioni Discrete
4.1.1 Funzione Indicatrice
Sia \((\Omega, F, P)\) uno spazio di probabilità, e sia \(A \in F\) un particolare evento. Indichiamo con \(1_A\) la funzione indicatrice dell'evento \(A\), ovvero la funzione \(1_A: \Omega \to \Omega\) definita come segue
\[\forall \omega \in \Omega: \,\, 1_A(\omega) = \begin{cases} 1 \,&,\, \omega \in A \\ 0 \,&,\, \omega \not \in A \\ \end{cases}\]
Notiamo che la densità discreta di \(1_A\) è data da
\[p(x) = \begin{cases} P(1_A = 0) = 1 - P(A) \,\,&,\,\, x = 0 \\ P(1_A = 1) = P(A) \,\,&,\,\, x = 1 \\ P(1_A = x) = 0 \,\,&,\,\, x \neq 0, 1 \\ \end{cases}\]
4.1.2 Distribuzione Binomiale
La distribuzione binomiale viene utilizzata per contare il numero di successi in uno schema di Bernoulli in cui si effettuano \(n\) prove indipendenti, ciascuna delle quali ha probabilità di successo \(p\) e probabilità di insuccesso \(1-p\).
Formalmente indichiamo una v.a. con distribuzione binomale con \(X \sim Bin(n, p)\). La densità di una v.a. con distribuzione binomiale è quindi la seguente
\[\forall k \in \{0, ..., n\}: \,\, p(k) = P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}\]
Per quanto riguarda valore atteso e varianza, abbiamo che
\(\mathbb{E}[X] = n \cdot p\)
\(Var[X] = n \cdot p \cdot (1-p)\)
4.1.3 Distribuzione Geometrica
La distribuzione geometrica viene utilizzata per contare il numero di fallimenti necessari per ottenere il primo successo, assumendo di poter fare infinite prove di un esperimento in cui la probabilità di successo è \(p\) e la probabilità di insuccesso è \(1-p\).
Formalmente indichiamo una v.a. con distribuzione geometrica con \(X \sim Ge(p)\). La densità di tale v.a. è data da
\[p(k) = \begin{cases} p\cdot(1-p)^k \,\,&,\,\, k \geq 0 \\ 0 \,\,&,\,\, \text{ altrimenti } \\ \end{cases}\]
Per quanto riguarda valore atteso e varianza, abbiamo che
\(\mathbb{E}[X] = \displaystyle{\frac{1}{p}}\)
\(Var[X] = \displaystyle{\frac{1-p}{p^2}}\)
4.1.4 Distribuzione di Poisson
Una v.a. che segue la distribuzione di Poisson è indicata con \(X \sim Poisson(\lambda)\), con \(\lambda > 0\) parametro della distribuzione. Tale v.a. ha la seguente densità
\[p(k)=\begin{cases} \displaystyle{e^{-\lambda} \cdot \frac{\lambda^k}{k!}} \,\,&,\,\, k = 0,1,2,... \\ 0 \,\,&,\,\, \text{ altrimenti } \end{cases}\]
Notiamo che si tratta di una densità di probabilità in quanto, dallo sviluppo di Taylor, segue che
\[e^{\lambda} = \sum\limits_{k = 0}^{\infty} \frac{\lambda^k}{k!}\]
Per quanto riguarda valore atteso e varianza, abbiamo che
\(\mathbb{E}[X] = \lambda\)
\(Var[X] = \lambda\)
4.2 Distribuzioni Continue
4.2.1 Distribuzione Uniforme
Una v.a. continua \(X\) è detta uniforme in \([a, b]\), in simboli \(X \sim U[a, b]\), se la probabilità che \(X\) assuma valori in un sottointervallo \([c, d]\) di \([a, b]\) dipende solamente dall'ampiezza del sottointervallo, e non da dove esso è collocato.
Tale variabile aletoria ha la seguente funzione di ripartizione
\[F_X(t) = \begin{cases} 0 \,&,\,\, t < a \\ \\ \displaystyle{\frac{t-a}{b-a}} \,&,\,\, a \leq t \leq b \\ \\ 1 \,&,\,\, t > b \\ \end{cases}\]
Dato che \(F_X(t)\) è continua e derivabile con derivata continua in tutto l'intervallo tranne che in \(0\) e \(1\), abbiamo che è possibile ottenere una densità di \(X\) andando a derivare \(F_X(t)\) e ottenendo
\[f_X(t) = \begin{cases} \displaystyle{\frac{1}{b-a}} \,&,\,\, a < t < b \\ \\ 0 \,&,\,\, \text{ altrimenti } \\ \end{cases}\]
Notiamo che, dati \(U \sim U[0,1]\) e \(a,b \in \mathbb{R}\), allora
\[Y = a + b \cdot U \sim U[a, a + b]\]
4.2.2 Distribuzione Esponenziale
Una v.a. continua \(X\) è detta esponenziale con parametro \(\lambda\), in simboli \(X \sim Exp(\lambda)\), se ha la seguente densità
\[f_X(t) = \begin{cases} \lambda e^{-\lambda t} \,&,\,\, t > 0 \\ 0 \,&,\,\, \text{ altrimenti } \\ \end{cases}\]
La funzione di ripartizione è invece la seguente
\[F_X(t) = \begin{cases} 1 - e^{-\lambda t} \,&,\,\, t \geq 0 \\ 0 \,&,\,\, \text{ altrimenti } \\ \end{cases}\]
4.2.3 Distribuzione Normale
Una v.a. continua \(X\) è detta normale con parametri \(\mu, \sigma\), in simboli \(X \sim \mathcal{N}(\mu, \sigma^2)\), se ha la seguente densità
\[f_X(t) = \phi(t) = \frac{1}{\sigma \sqrt{2\pi}} \cdot e^{\displaystyle{-\frac12 \Big( \frac{x - \mu}{\sigma} \Big)^2}}\]
Graficamente quindi la densità normale è rappresentata come segue
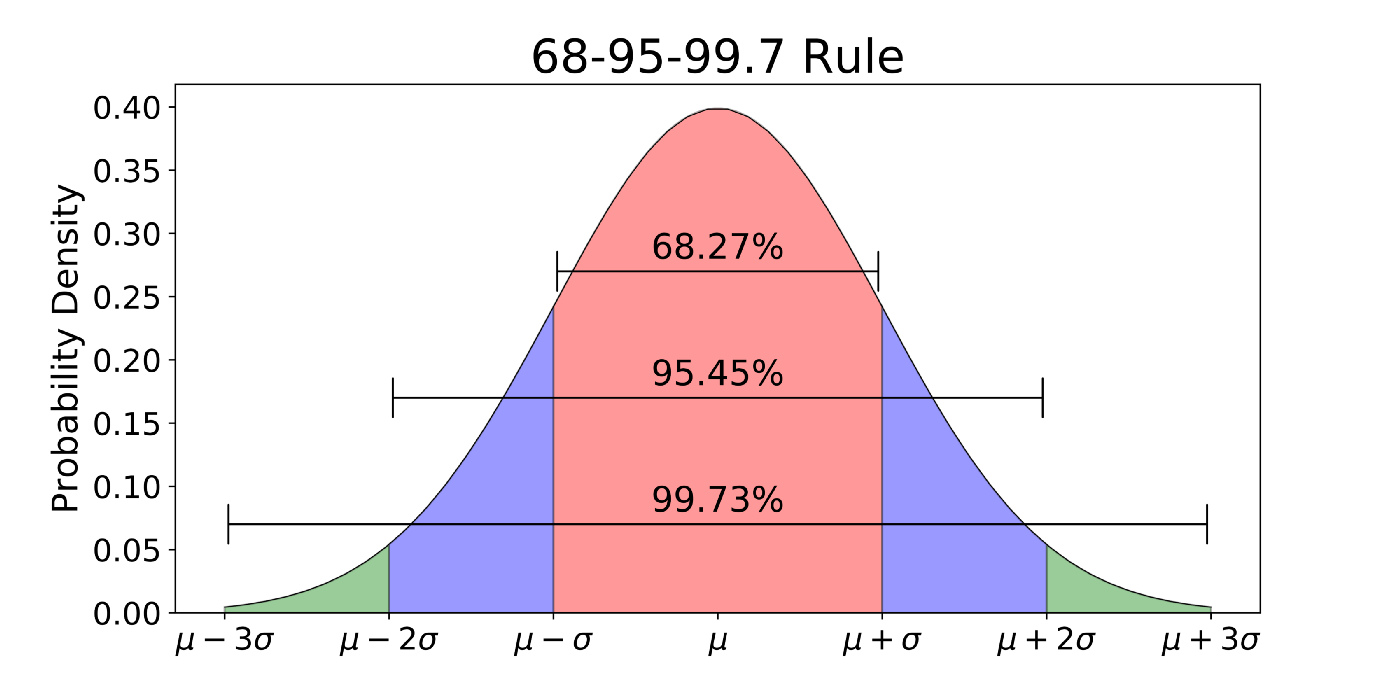
Notiamo che non è possibile esprimere la funzione di ripartizione per una v.a. normale con una funzione primitiva, in quanto è definita come segue
\[\Phi(t) := \int\limits_{-\infty}^t \phi(t) \, dt\]
Nel caso in cui \(\mu = 1\) e \(\sigma^2 = 0\), allora abbiamo a che fare con una v.a. normale standard.
4.2.4 Distribuzione Gamma
La densità della distribuzione gamma è denotata con \(\Gamma(k, \lambda)\), dove \(k\) e \(\lambda\) sono i parametri della distribuzione, ed è definita dalla seguente formula
\[f(x) := \begin{cases} \displaystyle{\frac{\lambda^k x^{k-1} e^{-\lambda x}}{\Gamma(k)}} &, x > 0 \\ 0 &, x \leq 0 \\ \end{cases}\]
dove con \(\Gamma(k)\) si intende la funzione gamma, definita da
\[\Gamma(k) := \int\limits_{0}^{\infty} s^{x-1}e^{-x} ds\]
Graficamente otteniamo la seguente forma

Le origini della funzione gamma sono molto interessanti. Inizialmente la funzione gamma è stata definita per estendere la funzione fattoriale \(n!\) all'insieme dei valori reali. Notiamo infatti che utilizzando la tecnica di integrazione per parti
\[\int fg = F g - \int F g^{'} \,\,\, \text{, con } F \text{ primitiva di } f\]
è possibile far vedere che \(\forall x \in \mathbb{N}\)
\[\Gamma(x) = (x-1)!\]
Andiamo adesso a calcolare il valore atteso della distribuzione Gamma. Data la v.a. \(X \sim \Gamma(k, \lambda)\), troviamo che
\[\begin{split} \mathbb{E}[X] &= \int\limits_{0}^{\infty} x \cdot \frac{\lambda^k x^{k-1} e^{-\lambda x}}{\Gamma(k)} dx \\ &= \int\limits_{0}^{\infty} \frac{\lambda^{k} x^{k} e^{-\lambda x}}{\Gamma(k)} dx \\ &= \frac{\Gamma(k+1)}{\Gamma(k+1)} \cdot \frac{\lambda}{\lambda} \cdot \int_{0}^{\infty} \frac{\lambda^{k} x^{k} e^{-\lambda x}}{\Gamma(k)} dx \\ &= \frac{\Gamma(k+1)}{\Gamma(k)} \cdot \frac{1}{\lambda} \cdot \int_{0}^{\infty} \frac{\lambda^{k+1} x^{k} e^{-\lambda x}}{\Gamma(k+1)} dx \\ &= \frac{\Gamma(k+1)}{\Gamma(k)} \cdot \frac{1}{\lambda} \cdot 1 \\ &= \frac{k!}{(k-1)!} \cdot \frac{1}{\lambda} \\ &= \frac{k}{\lambda} \\ \end{split}\]
notiamo infatti che \(\displaystyle{\frac{\lambda^{k+1} x^{k} e^{-\lambda x}}{\Gamma(k+1)}}\) è la densità di una \(\Gamma(k+1, \lambda)\), e dunque integrandola da \(0\) a \(\infty\) otteniamo \(1\) per definizione di densità di probabilità.
Il calcolo appena mostrato è un esempio di un fenomeno più generale. Molto spesso infatti troviamo delle formule che inizialmente ci possono sembrare difficili da calcolare, ma che alla fine si riducono ad essere densità di distribuzioni di probabilità. Utilizzando il fatto fondamentale che, se \(f(x)\) è una densità di probabilità, allora
\[\int\limits_{-\infty}^{\infty} x \cdot f(x) \,\,dx = 1\]
possiamo semplificare enormemente il calcolo di tali formule, per ottenere il risultato cercato.
4.2.5 Distribuzione Chi-Quadro
La distribuzione chi-quadro è ottenuta prendendo delle normali standard e elevandole al quadrato. Quindi, se \(Z \sim \mathcal{N}(0, 1)\), allora \(Z^2 \sim \chi^2(1)\).
La somma di \(k\) v.a. indipendenti con distribuzione \(\chi^2(1)\), ovvero la distribuzione di \(k\) quadrati di normali standard \(\mathcal{N}(0,1)\) indipendenti si rappresenta con \(\chi^2(k)\), e viene chiamata distribuzione chi-quadro con k parametri di libertà.
Nel seguente esercizio abbiamo dimostrato che \(\chi^2(k)\) è una gamma di parametri \(\Gamma(k/2, 1/2)\). In particolare la sua pmf (probability mass function) è la seguente
\[\begin{split} F_Y(t) = 2\Phi(\sqrt{t}) - 1 \end{split}\]
mentre la sua pdf (probability density function) è la seguente
\[f_Y(t) = \frac{1}{\sqrt{2\pi}}t^{-1/2}e^{-t/2}\]
Seguono alcune informazioni sulla distribuzione chi-quadro: