ML - 01 - Introduction to ML
Date:
Lecturer: Giorgio Gambosi
Slides: (ml_01_introduction-slides.pdf)
Table of contents:
In questa prima lezione abbiamo introdotto sia i tipici problemi affrontati dal machine learning che l'approccio base generale per affrontare questi problemi.
Storicamente il machine learning nasce come un insieme di tecniche per risolvere il problema genereale del pattern recognition, ovvero della definizione di algoritmi che permettono l'identificazione automatica di un insieme di caratteristiche comuni a partire da un insieme di dati.
Casi particolari di pattern recognition sono:
Classificazione di un oggetto in un insieme di categorie.
Identificazione di associazioni tra elementi o tra valori, dove gli elementi sono caratterizzati da un insieme di variabili dette features che possono assumere vari valori presi da vari domini.
Costruzione di funzioni predittive, come i system di recommendation.
Raggruppare elementi in insiemi di elementi "simili" (clustering).
Un esempio di pattern recognition è quella di riconoscere automaticamente delle cifre scritte a mano a partire da delle immagini di esse.
In questo problema gli items sono rappresentati da una matrice di pixel
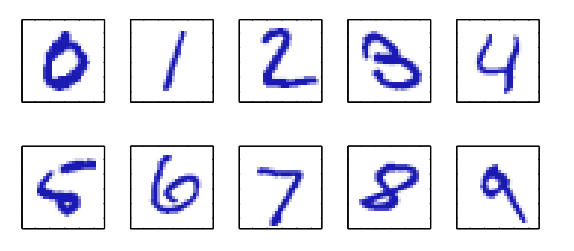
Per risolvere questa tipologia di problemi abbiamo due diversi approcci:
Uno di tipo deduttivo, che consiste nell'analizzare il problema e nel definire le caratteristiche più rilevanti di quest'ultimo, con il fine di definire un insieme di regole da applicare per riconoscere il particolare carattere.
L'altro di tipo induttivo, ovvero si parte da un insieme di esempi classificati correttamente e racchiusi in un training set, e si utilizzano questi ultimi per costruire un modello che può poi essere utilizzato per effettuare la classificazione.
L'approccio deduttivo molto spesso dimostra dei limiti, in quanto risulta difficile generalizzate in modo "dichiarativo" a partire dalle specifiche di un problema. Molto spesso è possibile utilizzare degli esperti di dominio, ma anche in questo caso l'approccio deduttivo risulta essere oneroso e limitato.
L'approccio adottato dal machine learning è principalmente quello induttivo.
In generale il processo di machine learning può essere schematizzato come segue
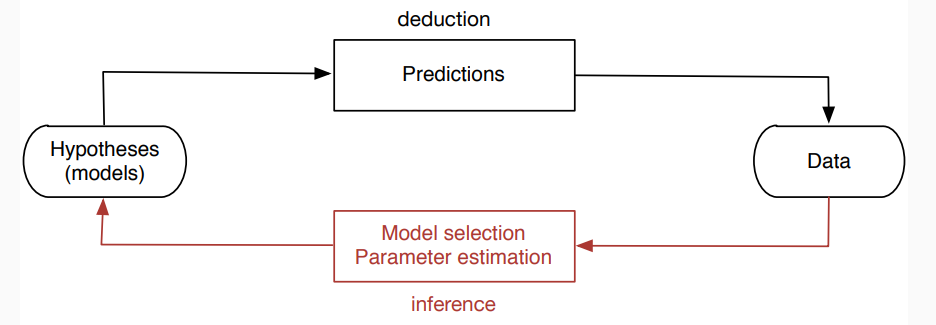
Come si può vedere, a partire dai dati si inferisce un modello (che essenzialmente è un algoritmo) che ci permette di effettuare delle predizioni (hypotheses). Una volta ottenuto il modello possiamo testarlo sui dati per vedere come si comporta. Se si comporta male possiamo migliorarlo in modo iterativo fino a raggiunge un determinato grado di qualità.
Quando si parla di machine learning è importante tenere a mente le varie tipologie di problemi affrontati da questa materia. Tra questi troviamo:
L'apprendimento supervisionato, in inglese supervised learning, è quando abbiamo a disposizione i valori per un insieme di features di un oggetto \(x\), e vogliamo inferire il valore di un'ulteriore feature dell'item \(x\), che molto spesso viene chiamata target.
L'apprendimento supervisionato può essere ulteriormente specializzato a seconda delle caratteristiche del valore che vogliamo predirre:
Classificazione: quando il dominio del target da inferire è un insieme discreto \(\{1, \ldots, K\}\).
Regressione: quando il dominio del target da inferire è un insieme continuo come \(\mathbb{R}\).
Example: Abbiamo a disposizione un insieme di dati per degli appartamenti di roma, dove ogni appartamento è descritto da un insieme di features, formalmente \(x_i = \{x_{i1}, \ldots, x_{im}\}\), e vogliamo fare una predizione sul valore di mercato dell'appartamento.
La relazione tra feature e target che andiamo a derivare a partire dai dati in input, ovvero il modello che costruiamo, può essere di due tipi:
Funzionale: Quando abbiamo una funzione \(y(\cdot)\) che, per ogni oggetto \(x\), ritorna il valore \(y(x)\) come una approssimazione per il vero valore \(t\) del target di \(x\).
Probabilistica: In questo caso abbiamo una distribuzione di probabilità per ogni possibile valore del target, associando così facendo ad ogni possibile valore \(\bar{y}\) la probabilità \(P(y = \bar{y} \,\, | \,\, x)\).
L'apprendimento non supervisionato è meno caratterizzato di quello supervisionato e accomuna una serie di situazioni in cui abbiamo un dataset \(X = \{x_1, \ldots, x_n\}\), ma, a differenza di prima, questa volta non abbiamo un target associato ad ogni item.
Da questo dataset si vuole poi estrarre dell'informazione, che dipende a seconda dello specifico problema affrontato:
Clustering: quando vogliamo partizionare il dataset \(X\) in sottoinsiemi di elementi che in qualche modo sono "simili" tra loro, dove il concetto di "simile" dovrà essere formalizzato ogni volta a seconda del modello.
Density estimation: quando vogliamo capire come sono distribuiti gli elementi nel loro dominio. Una volta che ho stimato la distribuzione degli elementi posso poi affrontare ulteriori problemi, ad esempio quello dell'outlier detection, ovvero di capire se ci sono elementi che sono "strani" rispetto alla media.
Feature selection/extraction: quando vogliamo eliminare le features meno significative del dataset, ovvero quando vogliamo caratterizzare il dataset utilizzando meno informazioni possibili.
In quest'ultimo caso vogliamo insegnare ad un soggetto/entità che esegue determinate azioni qual è la strategia migliore per affrontare particolari situazioni.
Esempi di modelli costruiti tramite del reinforcement learning (apprendimento rinforzat) sono la Google car, oppure i modelli che giocano a scacchi.
In questo caso assumiamo che ci sia un environment (ambiente) che dia dei feedback, siano essi positivi o negativi, al soggetto quando quest'ultimo esegue le sue azioni. Ricevendo il feedback il soggetto cambia comportamento e iterando questo processo è idealmente in grado di imparare la strategia migliore. Il concetto di rinforzo sta nel fatto che si cerca di costruire un ambiente in cui le mosse "positive" sono premiate, mentre quelle "negative" sono punite.
L'apprendimento con rinforzo si pone quindi a metà strada tra apprendimento supervisionato e apprendimento non-supervisionato.