SABD - 03 - Distributed File Systems II
1 Informazioni lezione
Data:
Slides: SABD - 1 - Storage_DFS.pdf, 19
Tenuta su Microsoft Teams.
Lunedì della settimana prossima laboratorio con Fabiana.
Lezione scorsa: introduzione file system distribuiti con esempio di google file system.
Obiettivi lezione: completare analisi file system distribuiti, con analisi di Google file system, Hadoop file system, gluster file system.
2 Google file system (GFS)
Continuiamo quindi la trattazione del google file system (GFS) iniziata la scorsa lezione.
2.1 Architettura GFS
Il GFS implementa unaa architettura master, slave (o worker).
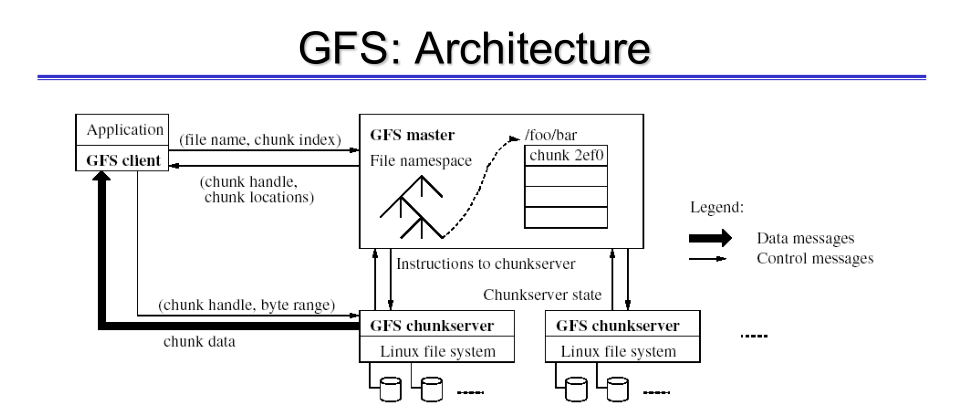
Il master ha il compito di gestisce i metadati e coordina i vari workers. I workers hanno il compito di gestire i dati.
I dati relativi ad un singolo file vengono memorizzati suddividendo il file in blocchi che prendono il nome di chunks.
La scelta progettuale fatta da google di avere un unica unità centralizzata porta ad una semplificazione dell'architettura. Detto questo ci sono anche delle limitazioni che derivano dall'utilizzo di un singolo master, e queste sono:
- Single point of failure.
- File che possono essere memorizzati
Per gestire queste problematiche sono state introdotto delle soluzioni da google, ma in ogni caso le soluzioni sono solo parziali, e non risolvono completamente le problematiche che derivano dall'utilizzo di un singolo nodo master.
I metadati sono gestiti dal master e sono memorizzati nella memoria RAM al fine di aumentare le performance. I chunks invece sono memorizzati dai workers, detti anche chunk servers.
Nella versione iniziale del GFS per garantire la fault-tollerance i chunks venivano memorizzati in modo replicato, con un fattore di replicazione tipicamente posto pari a 3. Attualmente le soluzioni offerte da google permettono anche di avere dei codici a correzione di errori.
Notiamo come nell'architettura del GFS il flusso di controllo (nella figura sono le linee meno tratteggiate in nero) e il flusso di dati (linee più tratteggiate in nero) sono completamente disaccoppiati. Il flusso di controllo coinvolge sia il master che i chunk servers, mentre il flusso dei dati coinvolge solamente i chunk servers.
La dimensione dei chunk è di 64 MB o 128 MB. Questo viene fatto perché i file gestiti dal google file system (GFS) hanno dimensioni molto grandi. Avere chunk di questa dimensione permette di diminuire:
- Interazioni client/server.
- Quantità di metadati da gestire.
2.2 Replicazione e fault-tollerance
Il master coordina la replicazione dei chunk su molteplici chunk severs. Tipicamente abbiamo almeno 3 repliche per ogni chunk. Per gestire la tolleranza ai guasti possiamo utilizzare un meccanismo di votazione non tollerante a guasti bizzantini ma tolleranti a guasti di tipo fail-stop (crash).
La replicazione avviene eleggendo un chunk server come primary server per la gestione di quel particolare chunk. Il primary server poi andrà a comunicare con altri 2 chunk servers per replicare il particolare chunk.
Il grado di replicazione per chunk associati a file molto spesso utilizzati può essere aumentato a discrezione dell'utente. Notiamo infatti che all'aumentare del grado di replicazione aumenta il parallelismo delle operazioni di lettura, in quanto lo stesso chunk può essere ottenuto da chunk server differenti; anche le operazioni di scrittura però aumentano, e tipicamente avere 3 copie permette di ottenere un buon equilibrio.
Per replicare questi chunks google utilizza contemporaneamente due seguenti approcci:
- Diverse macchine, stesso rack.
Permette di aumentare l'availability e la reliability.
- Diverse macchine, diverso rack.
Tipicamente infatti abbiamo 2 chunk su diversi chank servers appartenenti allo stesso rack e il terzo chunk su un chunk server appartenente ad un rack differente.
Ciascun chunk è diviso in blocchi di dimensione abbastanza piccola: 64KB. Per ciascun blocco viene calcolato e salvato in memoria un checksum, che permette di verificare l'integrità del blocco di dati. Ogni volta che si effettua una operazione sul blocco si fa il controllo del checksum per riconoscere eventuali errori dovuti alla corruzione dei dati.
2.3 Master operations
Il master è coinvolto in tutte le operazioni relative alla gestione dei metadati, tra cui:
- Gestione dello spazio dei nomi (namespace);
- Gestione della creazione, replicazione, bilanciamento e ridistribuzione dei chunk tra i vari chunk servers.
- Gestione della coordinazione necessaria per effettuare le operazioni di lettura, scrittura e cancellazione dei chunks.
Lo spazio dei nomi viene rappresentato come una tabella di look-up. Per gestire le operazioni sui blocchi il master prende un lock sul namespace. Questo lock fa in modo che i file e le cartelle non possono essere eliminate o rinominate durante lo svolgimento delle operazioni.
Il master deve inoltre controllare lo stato di salute dei diversi chunk server tramite degli heratbeat messages.
Il master si occupa anche della cancellazione dei file. Notiamo infatti che i file e i chunks in cui il file è diviso non vengono cancellati immediatamente, ma vengono cancellati in modo asincrono. In particolare il master, prima di cancellare il file, rinomina il file con un nome nascoto e assegna al file da eliminare un timestamp, allo scadere del quale il file verrà cancellato (meccanismo di "cestino"). Questo permette di avere una finestra di tempo in cui poter recuperare il file cancellato.
Il livello di consistenza offerto da GFS è una consistenza debole. Per evitare situazioni in cui la copia di un chunk in un chunk server sia vecchia si associa a ciascun chunk un numero di versione, detto chunk version number. Questo numero di versione viene incrementato ad ogni operazione di scrittura che viene effettuata su quel chunk. Quando il master si accorge che un chunk ha uno stale version number, lo rimuove dal chunk server e lo aggiorna con la nuova versione.
Notazione: Con la parola "mutations" si intendono le operazioni di scrittura che possono essere effettuate in qualunque punto del file o alla fine del file.
2.4 System interactions
Nel GFS i file sono organizzati in modo gerarchico attraverso l'utilizzo di cartelle. Notiamo inoltre che GFS non è POSIX compliant.
Le operazioni che il GFS ci mette a disposizione possono essere divise in due blocchi: nel primo troviamo le operazioni più tipiche per un file system, che sono:
- Create
- Delete
- Open
- Close
- Read
- Write
Abbiamo poi anche due operazioni speciali, che tipicamente non troviamo in un file system tradizionale. Queste sono:
- Record append
Permette di aggiungere dei dati alla fine del file. In particolare GFS supporta delle operazioni di append in modo concorrente: più client possono fare append sullo stesso file senza sovrascrivere tra loro il contenuto del file.
- Snapshop
Permette di fare una copia di un albero di directories. Operazione resa efficient utilizzando le tecniche di copy-on-write. Questo vuol dire che la copia viene effettuata solamente quando i dati vengono modificati.
2.4.1 Read operation
Il flusso delle operazioni per eseguire una lettura sono le seguenti può essere schematizzato come segue
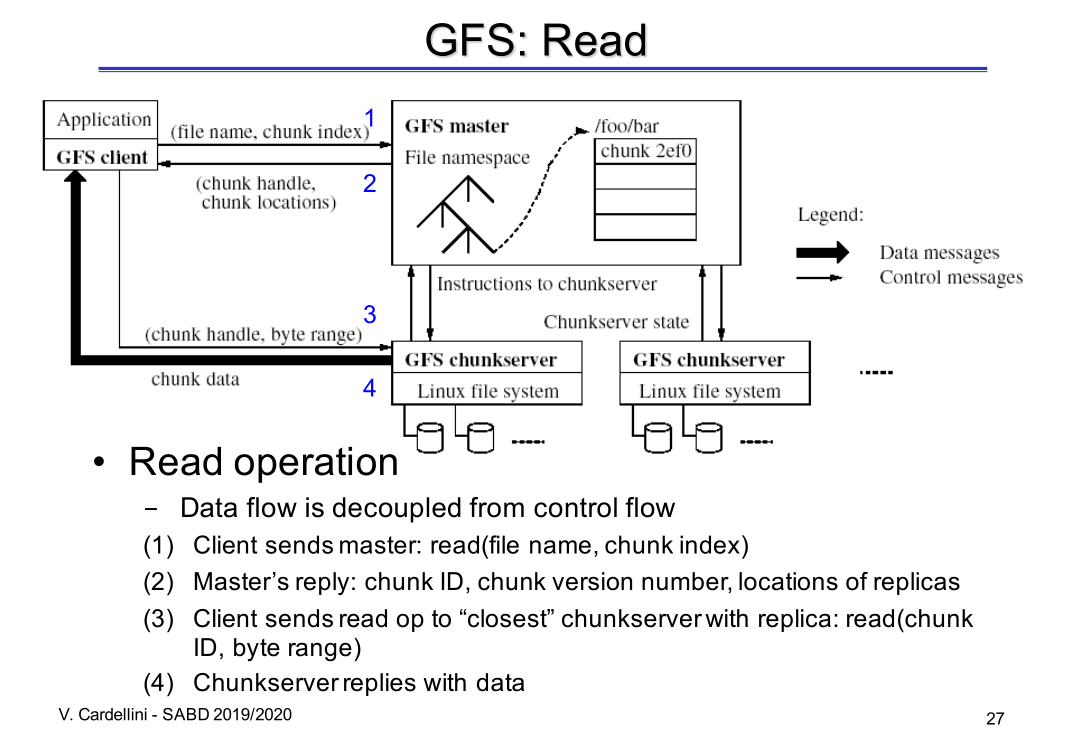
Volendo descrivere più dettagliatamente le varie operazioni troviamo,
- Il client interagisce con il master per indicare il nome del file da essere letto, indicando anche l'indice del chunk che deve essere letto: read(file name, chunk index).
- Il master utilizza i propri metadati per identificare i chunk
server che stanno gestendo le repliche del chunk richiesto e
risponde al client mandandogli:
- Chunk ID
- Chunk version number
- Locations of replicas
Osservazione: Il chunk version number viene continuamente comunicato al master tramite gli geartbeat messages. Così facendo il master ha una vista aggiornata rispetto all'ultima comunicazione avvenuta con i chunk server.
- Il client seleziona una delle repliche più vicine tra quelle
ricevuta dal master e gli invia la richiesta di lettura del
chunk.
Osservazione: Questa operazione viene delegata al client in modo da alleggerire il compito del master. Infatti, un eventuale algoritmo di scelta per capire a quale chunk server chiedere il chunk avrebbe comportato un ulteriore sforzo computazionale da parte del master.
- Il chunk server fornisce al client i dati relativi a quel chunk.
Osservazione: se il numero di versione ritornato dal chunk server non è quello che è stato fornito al client dal master, allora il client si occupa di contattare un altro chunk server.
Notiamo che il flusso dei dati riguarda solamente i chunk servers che possiedono i chunk del file che deve essere letto, e non il master.
Domanda: TODO
2.4.2 Mutations
Le operazioni di scrittura sono due: la write e la append, e vengono chiamate mutations. Le mutazioni vengono eseguite da tutte le repliche in modo da poter lavorare in modo concorrente sulle stesse porzioni di file.
Per evitare che il master diventi il collo di bottiglia durante la coordinazione delle operazioni di mutazione viene utilizzato un meccanismo di lease. In questo modo il master assegna l'incarico di supervisionare il corretto aggiornamento del chunk su tutte le replice al chunk primario associato alla gestione del particolare chunk.
La primary replica ha il compito di scegliere l'ordine corretto in cui eseguire le operazioni di scrittura. Questo viene fatto per permette di eseguire scritture concorrenti.
Il leasing viene periodicamente rinnovato utilizzando degli heartbet messages tra il master e i chunkservers.
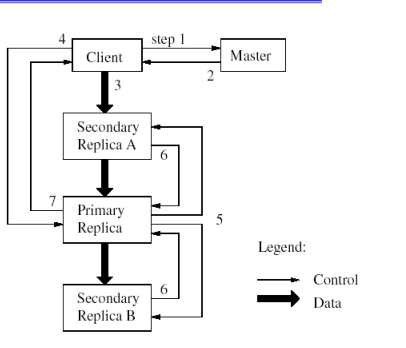
2.4.3 Atomic record appends
Ricordiamo che il GFS garantisce l'atomicità durante l'operazione di append. Volendo essere più precisi, il GFS garantisce che la scrittura verrà eseguita almeno una volta. Questo significa che la scrittura può avvenire anche più di una volta, e quindi che le applicazioni devono gestire il fatto che ci potrebbero essere delle possibili duplicazioni dei files.
Uno scenario in cui la duplicazione dei files può succedere è quando c'è un fallimento nella ricezione dell'ACK inviato dalla replica secondaria da parte della replica primaria, anche nel caso in cui la replica secondaria ha correttamente effettuato la scrittura.
Questa "debolezza" è dovuta principalmente al contesto di utilizzo, in quanto i file si trovano molto spesso nella situazione multiple-producers/single-consumer oppure può succedere di dover fare il merge dai risultati di vari clients (MapReduce scenario).
2.5 Consistency model
Il modello di consistenza utilizzando da GFS è "rilassato", in quanto offre solamente una eventual consistency, in quanto è semplice ed efficiente da implementare.
Nel modello di consistenza utilizzato da google vengono introdotte le seguenti due terminologie rispetto ad una data "file region":
- Consistent: Se tutte le replice hanno lo stesso valore per quella file region.
- Defined: Se dopo una operazione di scrittura (mutation), è consistente e tutti i clients vedono la mutazione nella sua interezza, ovvero ad una eventuale lettura tutte le copie restituiscono lo stesso valore, che è anche il più aggiornato.
Può succedere che delle operazioni possano portare porzioni del file ad essere consistent, ma non defined.
2.6 Performance
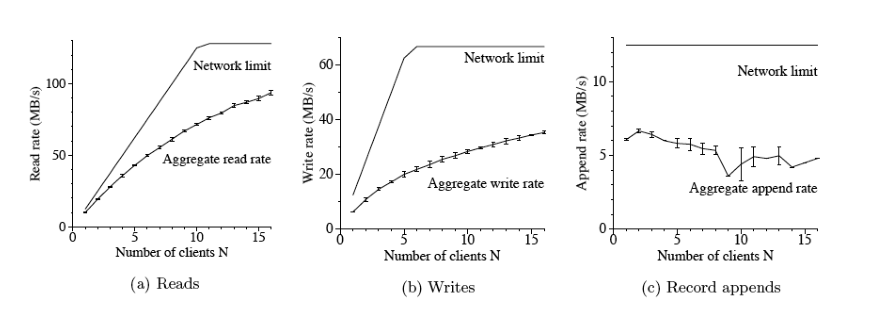
Le performance delle operazioni di lettura sono molto performanti e scalano bene rispetto al numero di clients.
Le performance delle operazioni di scrittura invece sono meno performanti. L'operazione append in particolare soffre di più di problemi di scalabilità.
2.7 Problems
I problemi del GFS derivano principalmente dalla scelta architetturale di utilizzare un solo master. Questo problema è stato affrontato sotto diversi punti di vista:
- Per gestire il single point of failure si è pensato di replicare il master con varie copie shadow. In caso di fallimento del master attivo i master "shadow" permettono di mantenere la sola lettura dei file memorizzati nel GFS.
- Per gestire la scalability bottleneck si è cercato di ridurre
al minimo l'interazione tra il master e i client tramite le
seguenti scelte:
- Il master gestiste solo i metadati, e non i dati.
- Il client può cachare i metadati.
- Il chunk size è abbastanza grande.
- Possibilità di fare chunk lease per gestire la coordinazione delle operazioni di mutazione.
Altrimenti problemi di GFS sono:
- Tutti metadati sono memorizzati in memoria, e questo pone un limite nel numero di dati che possono essere gestiti in un dato momento.
- La semantica di utilizzo non è non completamente trasparente alle applicazioni: garanzia durante la scrittura "at least once".
- Le prestazioni del GFS non sono adatte a tutte le applicazioni, in quanto il GFS è stato progettato con l'obiettivo di ottenere un throughput elevato per il processamento di tipo batch delle applicazioni e per gestire files di grandi dimensioni.
- In generale GFS ottimizza il throughput, ma non performa bene per quanto riguarda la latenza.
2.8 Colossus
Rilasciato nel 2010 e sviluppato specificatamente per i real-time services.
Si sa poco al riguardo.
I masters sono gestiti in modo distribuito.
Utilizzo di error-correcting codes per la fault tolerance al posto della replicazione: reed-solomon.
Su colossus sono poi stati progettati altri servizi, tra cui:
- Google Cloud Storage: Cloud Object store.
- Google BigQuery: Cloud data warehouse.
3 Hadoop DFS (HDFS)
HDFS sta per Hadoop Distributed File System, ed è un file system distribuito open-source, clone di GFS e scritto in Java. HDFS può girare completamente in user-space.
HDFS è diventato la storage solution standard per framework permette di effettuare del batch-processing sui dati come Hadoop, MapReduce, Spark, Hive e Pig.
Permette la gestione di large data sets: GBs o TBs in size.
Semplice modello di coherency: write-once, read-many-times.
3.1 Cons
3.2 File management
Analogo al GFS, ma con delle rinominazioni:
chunk <-> block master <-> NameNode chunk server <-> DataNode
3.3 Architecture
Architettura analoga al GFS.
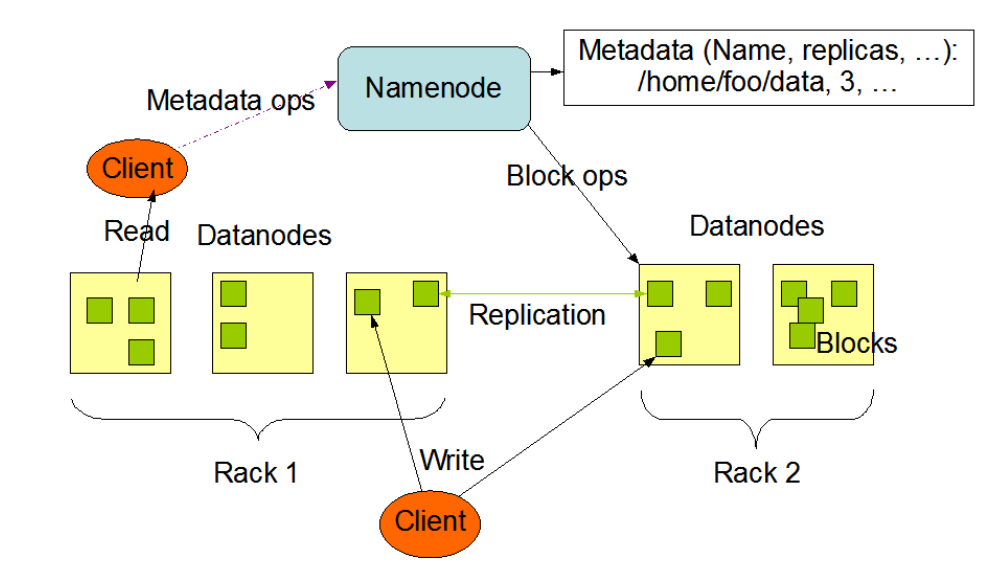
3.4 Block replication
La replicazione dei blocks viene effettuata sempre utilizzando degli heratbeat messages.
Ciascun DataNode scrive un blockreport e lo invia al NameNode. Il blockreport contiene tutte le informazioni relative ai blocchi contenuti nel DataNode.
3.5 Read and Write
L'operazione di scrittura è effettuata in modo analogo a quanto visto per il GFS.
Anche l'operazione di scrittura utilizza il meccanismo di leasing visto in GFS.
3.6 Enchanments in HDFS 3.x
Con la versione 3.x di HDFS sono state introdotti i seguenti potenziamenti:
- Possibilità di utilizzare i codici a correzione di errore al
posto della replicazione.
Osservazione: I codici a correzione di errore si basano su un sovracampionamento di un polinomio. Il valore dei punti calcolati per ogni polinomio viene trasmesso o memorizzato.
Utilizzando i codici a correzione di errore siamo in grado di diminuire l'overhead di storage dal 200% al 50% (x3 risparmio), ma ci aumenta l'overhead di rete e di tempo di processamento.
I codici utilizzati sono:
- XOR
- Reed-Solomon
- Possibilità di avere più di due NameNodes. Ad esempio è possibile avere 3 NameNodes, di cui uno è attivo e due sono "shadow".
4 GlusterFS
Gluster = "Linux + Cluster" è un file system open source basato su
LINUX e molto scalabile: dicono che permettono di gestire up to 72
prontobytes, che sono 1 Prontobyte = 10^27 or 2^90 bytes.
L'idea su cui si basa GlusterFS è quella di non avere un singolo server che gestisce i metadati. Si utilizza quindi un meccanismo di hashing chiamato consistent hashing per poter distribuire i metadati tra tutti i server che fanno parte del file system distribuito.
Ricapitolando, GlusterFS si basa su:
- Assenza server centralizzato per gestione metadati;
- Utilizzo di consistent hashing per gestire in modo distribuito
i metadati.
Il vantaggio nell'utilizzo del consistent hashing è l'abilità di associare, nello stesso spazio, un id univoco sia ai files che ai servers per poi mappare l'id di un file all'id del server che possiede quel file. Inoltre il consistent hashing è un algoritmo di hashing robusto, e permette quindi di gestire eventuali modifiche derivanti da operazioni di scrittura in modo semplice.
Osservazione: L'uso del consistent hashing non è simile all'uso classico nelle Distributed Hash Table, presente in Chord, ma è più simile all'utilizzo in Dynamo (da vedere successivamente nel corso), in cui non abbiamo delle tabelle di routing complesse, ma abbiamo un routing ad un singolo passo.
4.1 Architettura
Utilizzo di una nomemcaltura particolare,
- Bricks: unità di storage condiviso che viene messo a disposizione dal file system distribuito.
- Trusted Storage Pool: Insieme di risorse di storage fidato.
- Volumes: Insieme di bricks che hanno requisiti simili di ridondanza.
- Translators: Moduli messi a disposizione per effettuare delle conversioni di dati. Permettono di convertire le richieste dall'utente in richieste dello storage.
5 Alluxio
Alluxio può essere descritto come un "file system distribuito e virtuale" e deriva da un insieme di ricerche effettuate dall'università di Berkley. Alluxio è stato sviluppato dalle stesse persone che hanno lavorato al framework Spark come argomenti di tesi da parte di uno studente all'università di Barkley.
Tutti i file system visti prima memorizzano i file sui dischi. L'idea di Alluxio è quella di essere un file system distribuito in memory. Questo significa che i dati memorizzati da Alluxio sono completamente contenuti nella RAM, e non toccano mai il disco fisico.
La scelta di essere in memory permette ad Alluxio di avere sia un elevato throughput nelle operazioni di lettura e scrittura, e sia di una bassa latenza.
Il problema principale però è che la memoria RAM è una memoria volatile, e quindi non ci garantisce la persistenza. Per gestire questo problema si utilizza un meccanismo chiamato lineage, che consiste nel tenere traccia delle operazioni che sono state effettuate sullo storage.
Attualmente Alluxio può essere pensato come un "data orchestator for the cloud", ed è quindi utilizzato come un layer intermedio tra il layer di storage più tradizionali come HDFS e il layer di processamento con lo scopo di nascondere la latenza dei più tradizionali layer di storage utilizzando lo storage in memory.
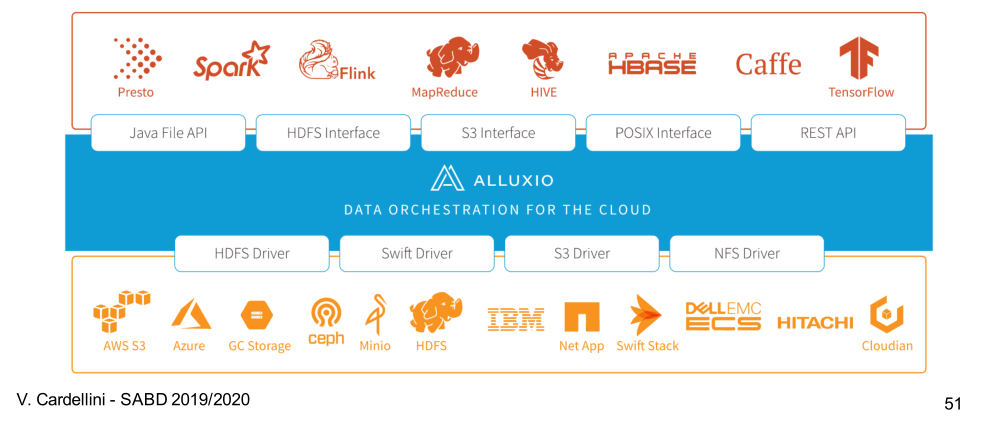
5.1 Architecture
Alluxio presenta una architettura master-worker con masters replicati (uno attivo, altri "shadow"), e vari workers.
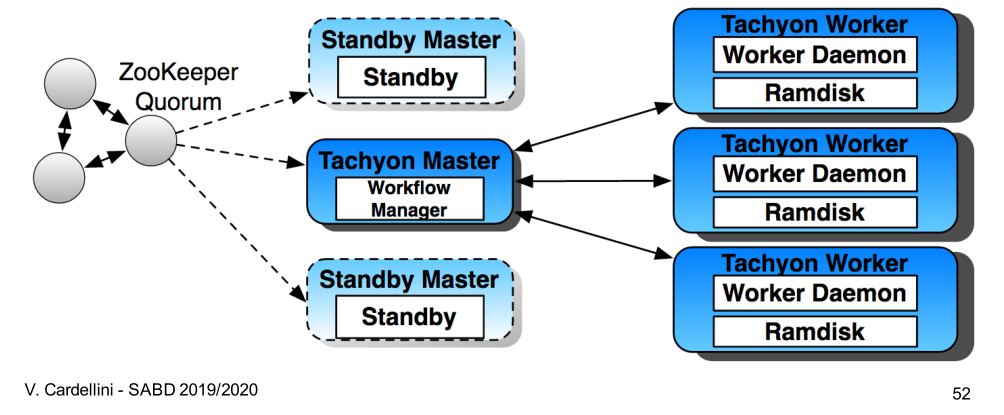
I metadati relativi ai mater vengono mantenuti da ZooKepper, che utilizza un algoritmo di consenso distribuito al fine di gestire i master. In caso di fallimento l'algoritmo di elezione di ZooKepper permette di scegiere il nuovo master.
Il master ha il compito di gestire la lineage.
I workers invece gestiscono le risorse locali a loro disposizione e comunicano periodicamente con il master tramite degli "heartbeat messages".
5.2 Lineage and persistence
Il meccanismo della lineage permette di tenere traccia della sequenza delle operazioni che vengono eseguite in modo da poterle computare in risposta ad un eventuale fallimento del sistema.
Dato che il solo meccanismo della lineage potrebbe non bastare, Alluxio aggiunge un meccanismo di persistence tramite l'utilizzo di checkpoints asincroni. Il modo in cui viene eseguito il checkpointing può essere legato alla "popolarità" dei files.
5.3 Evolution
In generale l'obiettivo di Alluxio è quello di portare i dati il più vicino possibile alle applicazioni riducendo la latenza.
Alluxio funziona anche come interfaccia comune per connettere vari sistemi di storage con i più comuni framework utilizzati per il processamento dati.