SABD - 04 - NoSQL I
1 Informazioni lezione
Data:
Slides di riferimento: SABD - 2 - Storage_NoSQL.pdf, 1-38
Nello stack di riferimento ci troviamo nel livello di "Data Storage".
In questa lezione vedremo le caratteristiche principali dei tradizionali datastore relazionali, e come i nuovi datastore di tipo NoSQL si differenziano da questi ultimi.
La settimana prossima la lezione sarà tenuta da Fabiana Rossi con un focus su un laboratio per sistemi di storage e si andrà ad utilizzare l'HDFS e si vedrà REDIS come esempio di data store chiave valore in memory e mongoDB.
1.1 Per prossima lezione
Installare prima della lezione i diversi container ripotati per effettuare delle prove durante la lezione stessa e risolvere piccoli esercizi.
Links container: 031419_hands-on.txt
2 Relational DBMSs
I database relazioni memorizzano le informazioni utilizzando una struttura ben definita "a tabella" e sono molto utilizzati nel contesto delle web app e dalle applicazioni di business.
I database relazionali si basano sull'utilizzo del linguaggio SQL (Structured Query Language), che è un linguaggio molto ricco e ben definito.
I database relazionali sono inoltre caratterizzati dalla presenza di vari vincoli rispetto ai dati e dalla garanzia delle proprietà ACID.
2.1 Proprietà ACID
L'acronimo ACID serve per sintetizzare le seguenti importanti caratteristiche che un tipico DBMS relazionale deve offrire:
- Atomicity: Tutte le operazioni che fanno parte di una transazione vengono eseguite in modo atomico: o vengono eseguite tutte o nessuna. Le transazioni seguono quindi il principio del tutto o niente.
- Consistency: Il database relazione è in uno stato consistente sia prima che dopo l'esecuzione di una qualsiasi transazione.
- Isolation: Le transazioni non possono vedere dei cambiamenti di cui non è stato effettuato il commit all'interno del DB. Dunque il comportamento di transazioni concorrenti è ben definito e il risultati di transazioni che non vengono completate non sono visibili alle altre transazioni.
- Durability: I cambiamenti apportati da transazioni completate sono persistenti nel tempo e non vengono persi anche in situazioni critiche di crash di sistema o interruzione dell'alimentazione che potrebbero portare a glitch nella memoria RAM.
Question: L'atomicità include la consistenza?
Answer: No, l'atomicità non include la consistenza in quanto la consistenza è vista rispetto ai vari stati in cui il DB si può trovare, mentre l'atomicità è vista solamente rispetto alle operazioni che compongono la transazione.
2.2 Contraints
I vincoli che troviamo in un tipico DMBS relazionale sono i seguenti:
- Domain contraints: Permette di restringere il dominio dei possibili valori per un dato campo.
- Entity integrity contraints: Il valore della primary key non può essere nullo.
- Referential integrity contraints: I vincoli di integrità referenziali ci permettono di mantenere la consistenza tra tuple che appartengono a due relazioni differenti, imponendo che il valore che un determinato attributo ha in una relazione debba esistere come valore che un altro attributo ha in un'altra relazione.
- Foreign key: La foreign key è utilizzata per fare dei riferimenti incrociati tra relazioni differenti e si deve trovare in una relazione di matching con la chiave primaria di un'altra relazione.
2.3 Vantaggi
I vantaggi nell'utilizzo di un tipico DBMS relazionale derivano dal fatto che il modello di consistenza garantito è ben definito. In generale, dato che i database relazionali sono stati studiati per più tempo, si conoscono molto bene e si hanno delle solide basi teoriche che ne formalizzano la struttura e il comportamento.
In generale i DBMS relazionali sono molto suited per le applicazioni OLTP (OnLine Transaction Processing).
2.4 Svantaggi
Gli svantaggi nell'utilizzo di un DBMS sono i seguenti:
- La scalabilità risulta essere molto limitata. Tipicamente un DBMS non può scalare su un ambito geografico e abbiamo un numero minimo di repliche (2 o 3) per garantire la tolleranza ai guasti in un ambito geografico.
- Supporto limitato per strutture dati che possono variare in modo dinamico nel tempo.
- Integrazione di dati da differenti RDBMS può essere molto pesante e difficile.
2.5 Scalare un RDBMS
Per fare scalare un RDBMS abbiamo le seguenti due principali soluzioni:
- Replicazione: Abbiamo vari server ciascuno dei quali contiene
una porzione del DB. Questa soluzione richiede di risolvere il
problema di mantenere la consistenza dei dati tra i vari server.
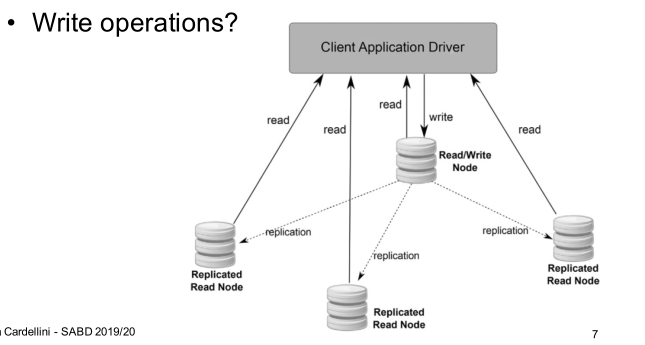
Il modello primary backup con l'architettura master/worker ci permette di avere un forte modello di consistenza.
Tramite la replicazione siamo in grado di eseguire operazioni di lettura in modo concorrente su tutte le repliche del DB, mentre le operazioni di scrittura sono effettuate solo dalla replica master, che si occupa poi di aggiornare le varie repliche workers.
La replicazione ci permette di scalare bene sulle operazioni di lettura, mentre le operazioni di scrittura rappresentano il collo di bottiglia.
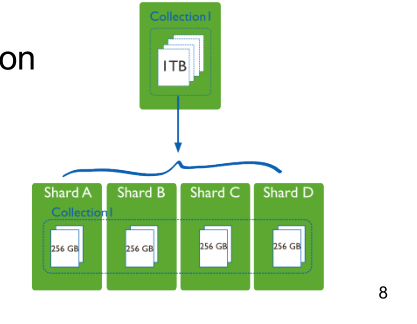
- Sharding: L'idea è quella di partizionare i dati tra differenti
server. È possibile poi distribuire richieste che fanno
riferimento a shard diversi su diversi server.
Il limite dello sharding è il fatto che non possiamo eseguire le transazioni che coinvolgono molteplici partizioni.
Una forma di sharding può essere ottenuta con il consistent hashing, che consiste nell'utilizzo di una hash function per hashare sia i dati che i nodi e mapparli nello stesso namespace.
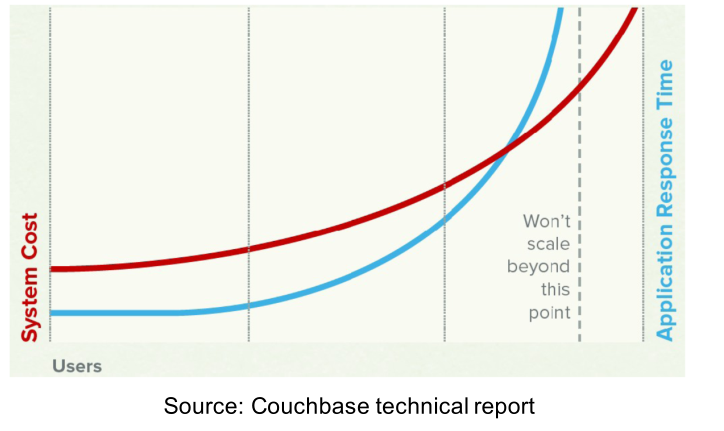
Notiamo in ogni caso che la scalabilità che si ottiene risulta essere molto costosa e inefficiente.
3 NoSQL
Dal problema della scalabilità dei DB relazioni nascono i datastore NoSQL.
Osservazione: Il termine NoSQL sta per "Not Only SQL", ed è stato coninato nel 2010 in una conferenza di sviluppatori di DBMS.
3.1 Caratteristiche
Le principali caratteristiche dei data stores NoSQL cercano di superare le limitazioni dei database relazioni, e sono:
- Scalabilità orizzontale: All'aumentare il numero di nodi che
compongono il sistema le prestazioni aumentano con un andamento
simile a quello lineare tramite uno sharding tra molteplici nodi.
Notiamo che il sharding nei datastore NoSQL non crea troppi problemi di performance in quanto tipicamente i datastore NoSQL hanno un supporto limitato per le transazioni.
- Supporto per dati flessibile: Gli schemi di dati utilizzati sono
molto più flessibili da quelli presenti nei database relazioni.
In particolare non richiediamo che tutti i valori di tutte le righe devono essere impostati con un table schema. Le righe della stessa entità possono infatti avere un numero differente di colonne.
- Disponibilità elevata: I datastore NoSQL forniscono una disponibilità elevata, in quanto i dati possono essere presenti in vari nodi, o come nel caso di Cassandra possono essere distribuiti in modo geografico.
- Architettura shared-nothing
Osservazione: Una eccezione a questo è neo4j, che è un database a grafo, che però presenta delle limitazione rispetto alla scalabilità.
- No operazioni SQL complesse: Eliminazione delle operazioni SQL più complesse, come l'operazione di JOIN.
- Modelli di consistenza deboli: Nei datastore NoSQL spesso si
compromette la reliability per la performance. Il modello di
consistenza garantito è infatti un modello di consistenza debole
(eventually consistent).
Osservazione: Il CAP Theorem ci dice che un sistema di database distribuito può avere solamente due caratteristiche tra le seguenti tre: consistency, availability e partition tolerance. I datastore NoSQL dunque, scegliendo l'availability e la partition tolerance, non possono ottenere anche la consistency.
3.2 Proprietà BASE
Le proprietà BASE sono una versione più rilassata delle proprietà ACID. Infatti, mentre le proprietà ACID si basano su una visione pessimistica, le proprietà BASE si basano su una visione ottimista in cui è ammessa l'occorrenza di conflitti che vengono risolti tramite opportune politiche.
L'acronimo BASE sta per:
- Basically Avaiable: L'intero sistema è disponibile la maggior parte del tempo, anche se potrebbe esistere un sottosistema temporaneamente non disponibile.
- Soft state: Contrapposto alla durability (D in ACID), significa che non vi è la stessa persistenza garantita come nell'approccio ACID.
- Eventual Consistency: Modello di consistenza finale ci garantisce che le diverse copie presenti nel sistema convergeranno ad uno stato consistente all'interno di una finestra temporale. All'interno di questa finestra temporale però utenti diversi potrebbero vedere valori diversi per lo stesso dato.
Le politiche utilizzate per risolvere i conflitti possono andare dall'aggiornamento condizionale (controllo del valore prima di aggiornare) all'utilizzo di timestamp basato su clock vettoriale per capire la scrittura più recente (last write wins).
3.3 Consistenza
Il cambiamento nella gestione della consistenza è stato uno dei più grandi cambiamenti dal mondo dei datbase tradizionali, che hanno sempre offerto un forte modello di consistenza.
La maggior parte (non tutti) dei sistemi NoSQL sono sistemi di tipo AP (ovvero che scelgono l'availability e la partition tollerance del teorema di CAP), in cui il modello di consistenza offerto è rilassato (eventual consistent).
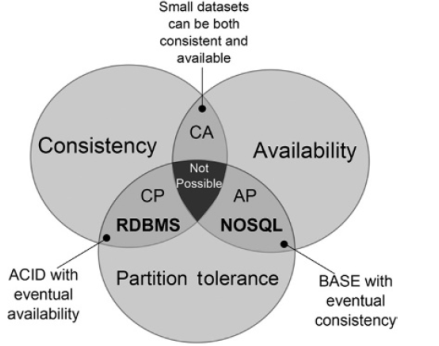
Osservazione: Alcuni sistemi NoSQL, come Cassandra, ci permettono di controlare il protocollo utilizzato per implementare il modello di consistenza utilizzato.
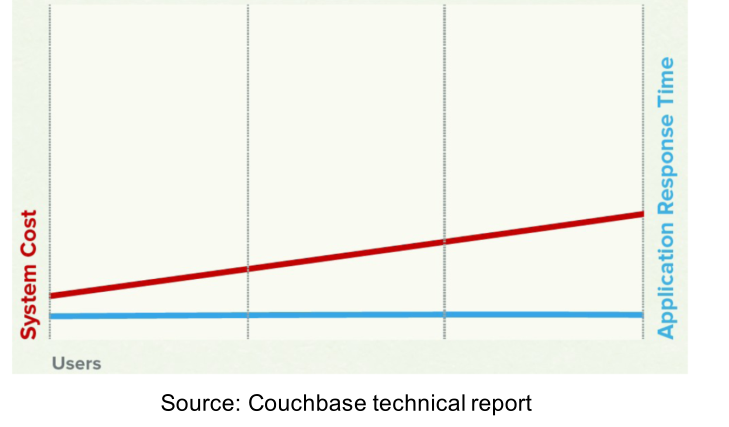
3.4 Performance
I datastore NoSQL riescono quindi a scalare rispetto al numero di utenti.
3.5 Vantaggi
Alcuni vantaggi nell'utilizzo di datastore NoSQL sono:
- Scalabilità
- Disponibilità e tolleranza ai guasti.
- Presenza di molti prodotti open-source, che portano a dei costi di gestione ridotti.
- Notevole incremento di flessibilià.
3.6 Svantaggi
Alcuni svantaggi nell'utilizzo di datastore NoSQL sono:
- La maggior parte dei datastore NoSQL non offre garanzie di tipo ACID. Questo comporta che i datastore NoSQL sono meno adatti per le applicazioni di tipo OLTP.
- Mancanza di modello di dati unico e mancanza di modello di storage unico.
- Mancanza di standardizzazione, in quanto manca u linguaggio unico come SQL e ogni applicazione ha il proprio linguaggio.
- Supporto limitato per operazioni di aggregazione.
3.7 Data models
Un modello di dati è un insieme di costrutti che vengono utilizzati per rappresentare le informazioni di interesse. Ad esempio, il modello relazionale rapresenta le informazioni utilizzando tabelle, che sono formate da colonne e righe.
Un modello di storage invece è il modo in cui il sistema che si occupa della gestione del data store memorizza e manipola i dati internamente.
Tipicamente un modello di dati è indipendente dal modello di storage utilizzato per implementarlo.
Andiamo adesso a vedere i vari modelli dei dati NoSQL che sono stati definiti negli ultimi dieci anni. Volendoli ordinare in base alla complessità, troviamo la seguente struttura:
- Aggregate-oriented models:
- Key-value
- Document
- Column-family
- Graph-based models
Per aggregato si intende il fatto che le unità prese in considerazione possono avere delle strutture complesse e ricorsive.
Si basa sulla aggregate pattern nel Domain-Driven Design.
L'aggregato viene visto come una unità rispetto alle operazioni di manipolazione dei dati e la gestione della consistenza.
Notiamo che il supporto delle transazioni ACID è garantito solo all'interno di un singolo aggregato, e non sono quindi garantite per transazioni che coinvolgono più aggregati.
I modelli orientati ai grafi tipicamente supportano le proprietà ACID per le transazioni. Questo ha un costo sulle performance.
3.7.1 Key-value model
Modello estremamente semplice con una completa assenza di schema. I dati sono rappresentati come un blob al quale viene associato una chiave.
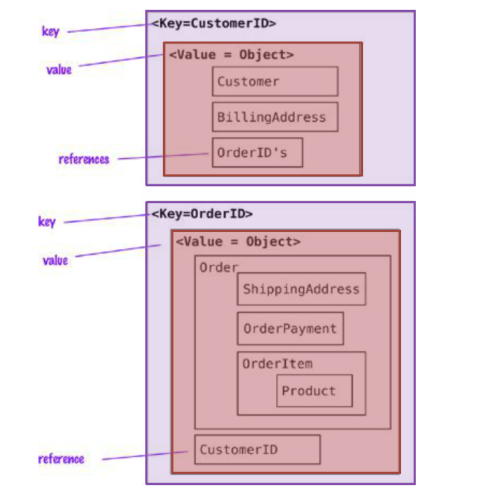
Il modello di dati fondamentali è un array associativo (mappa o dizionario).
Ciascun aggregato è opaco al data store ed è visto come un blob, ovvero come una sequenza di bit di cui non è nota la struttura.
Le operazioni che possiamo effettuare su questo modello di dati sono la SET e la GET. La GET viene realizzata andando ad effettuare una ricerca sulla chiave.
A seguire una possibile implementazione di un datastore NoSQL key-value utilizzando tool tipici di UNIX
#!/bin/bash # key-value.sh script db_set() { echo "$1, $2" >> datastore } db_get () { # La tail ci permette di estrarre l'ultima riga contenuta # all'interno del nostro datastore. grep "^$1," datastore | sed -e "s/^$1,//" | tail -n 1 } db_set 12345 '{"name":"London", "attractions":["Bing len", "London Eye"]}' db_set 42 '{"name":"San Francisco", "attractons":["Golden Gate Bridge"]}' db_get 42 db_set '{"name":"San Francisco", "attractons":["Explororium"]}' db_get 42
Per utilizzare il seguente DB possiamo procedere come seguente
./key-value.sh
Notiamo che alcuni datastore key-value possono supportare l'operazione di ordinamento rispetto al valore delle chiavi.
A seconda di dove avviene la memorizzazione dei dati poi possiamo avere vari data store con diversi modelli di consistenza. In particolare Redis è un esempio di database key-value in-memory.
I modelli di consistenza dei datastore key-value possono variare molto, andando da un modello di consistenza debole (eventually consistent), arrivando alla serializzabilità.
Osservazione: La serializzabilità viene considerato il gold-standard nella comunità dei database e permette di ottenere la I di Isolation dell'acronimo ACID. Infatti la serializzabilità è definita su un insieme di transazioni e ci garantisce che l'esecuzione delle transazioni è equivalente ad una esecuzione linearizzata delle transazioni, e quindi che abbiamo una relazione di ordinamento totale tra le differenti transazioni.
Alcuni esempi di datastore key-value, con il relativo modello di consistenza fornito (CAP) sono:
- AP: Dynamo, Riak KV, Voldemort
- CP: Redis, Berkley DB; Scalaris
Osservazione: DynamoDB è nato come datastore di tipo key-value e poi ha subito delle evoluzioni permettendo ad esempio la costruzione di indici.
Le query (GET) possono essere eseguite solamente utilizzando la chiave, e quindi la scelta della chiave è quindi molto importante.
Se non conosciamo la chiave è possibile integrate il sistema con una search engine che permette una full-text search (esempio: Apache Solr).
I possibili casi di utilizzo per il key-value data stores sono tutti quei casi in cui abbiamo un id facilmente identificabile e i dati associati all'id sono dinamici e possono cambiare con il tempo. In particolare troviamo:
- Memorizzazione delle informazioni sulla sessione nelle applicazioni web.
- Profili utente e configurazioni.
- Dati nel carrello di shopping.
3.7.2 Document model
In questo caso le API per la parte del query/update è basata sulla struttura interna dei documenti, e dunque non è opaca come nel caso dei key-value data models.
La caratteristicha che contraddistingue i document data model è che i valori presenti nei documenti possono avere una struttura molto complessa.
Il modello dei dati è quindi definita da un insieme di coppie <key, document>, dove il documento è una istanza aggregata di vari dati la cui struttura è visibile.
Il formato e la codifica utilizzata può variare molto a seconda dei vari prodotti e delle varie tecnologie, tra cui troviamo: XML, YAML, JSON, BSON.
Esempio di JSON object:
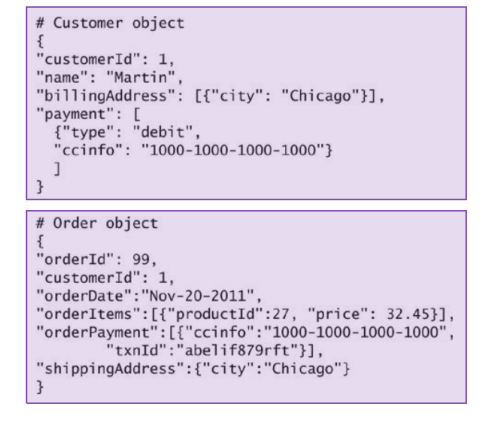
Notiamo che rispetto ad una tabella SQL, il documento ci permette di avere una maggior flessibilità, e ci permette di descrivere sia la struttura dei dati e sia i dati veri e propri.
La differenza fondamentale sta infatti nel fatto che le varie istanze nel document store model possono presentare campi diversi, mente nelle tabelle SQL tutte le istanze (righe) devono avere gli stessi campi.
Il document data model ci permette di effettuare le tipiche operazioni CRUD, che sono:
- Creation (insertion)
- Retrieval
- Update
- Deletion
Notiamo che le operazion di ricerca (retrieval) nel document data model non si basano solamente sul valore delle chiavi, ma possono utilizzare i campi del documento, in quanto il documento non è opaco ma è visibile al datastore manager.
Esempi di document stores sono:
- MongoDB
- CouchDB
- Couchbase
- RethinkDB
- RavenDB
Abbiamo anche un buon numero di servizi cloud per document store. Tra questi troviamo:
- Amazon DocumentDB
- Azure Cosmos DB: Cerca di offrire un datastore multi-model, ovvero che è in grado di supportare molteplici modelli di dati.
- Google Cloud Datastore
- Google Cloud Firestore: Ha la caratteristica di essere un document store serverless, ovvero il pagamento è per singolo utilizzo (invocazione).
A differenza del key-value store, il document store ci offre molte più opportunità di differenziare le operazioni di accesso (GET) in base ai diversi campi del documento e ci permette di avere degli indici sul contenuto dell'aggregato.
Il document data model è molto utilizzato per mantenere grandi quantità di dati semi-strutturati con un numero variabili di campi, come nel caso dei logs o dei commenti in blogs.
Non conviene utilizzato un document data model quando abbiamo transazioni complesse che coinvolgono molteplici documenti oppure quando la struttura dell'aggregato è molto dinamica e cambia nel tempo.
Osservazione: Le ultime versioni di MongoDB permettono transazioni complesse che coinvolgono molteplici documenti, ma c'è un forte impatto sulle prestazioni.
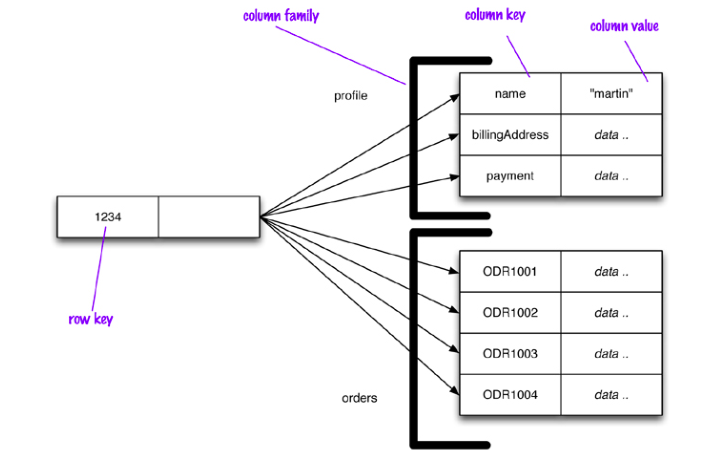
3.7.3 Column family model
Modello sempre basato sul concetto di aggreggato in cui ciascun aggregato ha una sua chiave.
Il column data model si trova in mezzo tra il key-value data model e il document model, in quanto il valore associato ad una chiave può avere una strutturazione maggior del key-value ma minore del document oriented, in quanto il valore può avere molteplici attributi (columns).
Il modello dei dati è quindi una struttura di tipo mappa a due livelli:
- Un insieme di coppie <row-key, aggregate>.
- Ciascun aggregato è un gruppo di coppie <column-key, value>.
- Ciascuna colonna contiene un particolare tipo di dato.
Le colonne possono essere organizzate in famiglie. Il criterio tipicamente utilizzato per definire una famiglia di colonne è il fatto che quei dati verranno acceduti assieme.
A seguire un esempio di column-family data model