WMR 08 - Natural Language Processing I
Date:
Course Site: Web Mining e Retrieval (a.a. 2019/20)
Lecturer: Roberto Basili
Slides: ()
Table of Contents:
In questa lezione abbiamo introdotto i concetti fondamentali per il processamento dei linguaggi naturali.
Il linguaggio naturale è il veicolo principale dei significati. Tramite le parole e le strutture del linguaggio siamo in grado di esprimere concetti, attività, eventi, astrazioni e relazioni concettuali che possiamo poi utilizzare per condividere informazioni. La caption di una immagine ad esempio ci permette di descrivere il luogo, i personaggi, e l'azione raffigurata nell'immagine, anche se lascia comunque un certo livello di ambiguità.
Osservazione: Le lingue naturali esistono anche senza i calcolatori. Ma i calcolatori, senza lingue naturali, si dovrebbero limitare solamente al calcolo funzionale.
Fare web mining in generale significa imparare a leggere i dati, che si presentano in forma libera, dare ai dati letti una particolare interpretazione per trasferire il significato dei dati al calcolatore.
In un tipico documento troviamo:
La struttura documentale, ovvero i metadati.
Un layout, ovvero un modo per rappresentare paragrafi e sottoparagrafi e per dare spazio alle intestazioni.
Una struttura logica, formata da titolo e sottotitolo.
Il contenuto testuale vero e proprio.
Nei tempi moderni poi i documenti hanno anche una natura ipertestuale, e quindi non ci basta più guardare la struttura del layout di un documento in isolamento; dobbiamo prendere in considerazione anche i collegamenti tra i vari documenti. La scrittura infatti è continua citazione, e solo ogni tanto queste citazioni vengono esplicitate per descrivere meglio le intenzione dietro alla scrittura.
Q: Why we need syntactic analysis?
A: Senza capie la posizione del verbo e del soggetto non riusciamo ad estrarre le informazioni. Il significato di un oggetto si chiarifica nel suo uso. Nelle reti neurali è importante capire come modellare la sintassi con cui una rete neurale prende decisioni semantiche sulla frase.
Quando analizziamo il linguaggio eseguiamo una cascata di passi, che prendono il nome di NLP chain. Questa catena prende in input il suono di una parola o frase e vuole rispondere almeno alle seguenti domande:
Syntax: La frase è corretta da un punto di vista grammaticale della lingua di interesse? (What is grammatical?)
Semantics: Cosa significa la frase? (What does it mean?)
Pragmatics: Cosa vuole da me la frase? (What does it do?). Nella pragmatica ci cercano quindi di capire le intezioni di una frase.
Mentre il livello pragmatico dipende dalla particolare applicazione (application-specific), i livelli della sintassi e della semantica sono indipendenti dalla particolare applicazione.
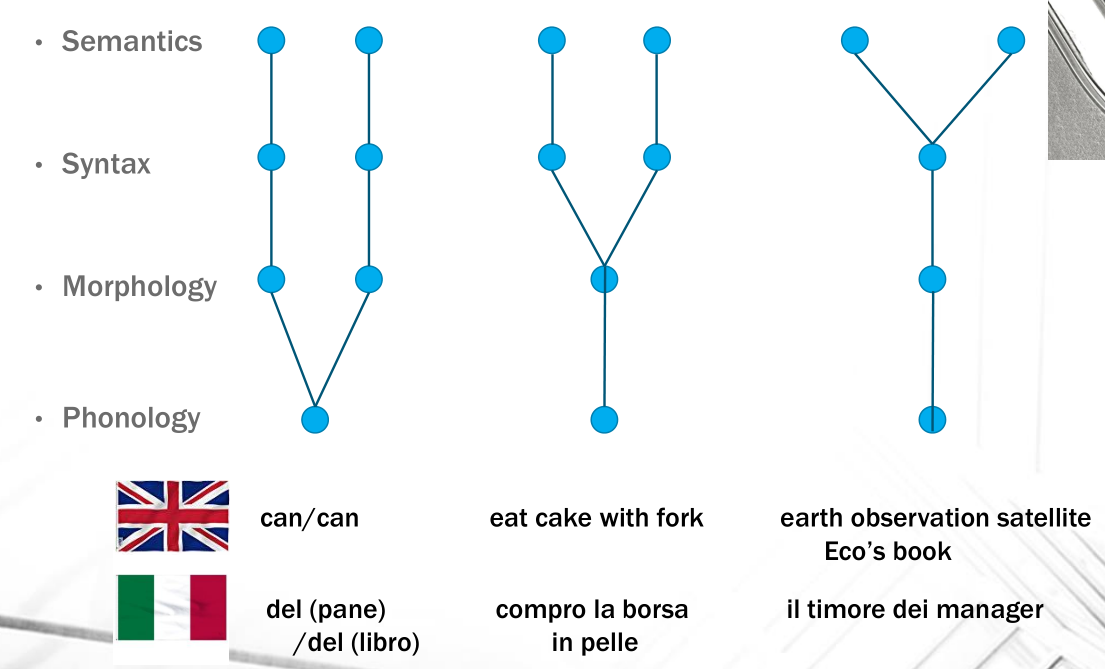
Notiamo come le ambiguità possono apparire nei diversi livelli di interpretazione del linguaggio

Dato che le ambiguità crescono in modo esponenziale, l'idea è quella di applicare dei meccanismi di apprendimento supervisionato e non-supervisionato per capire quali sono le scelte corrette da effettuare per disambiguare un testo tra le miriadi di scelte disponibili.
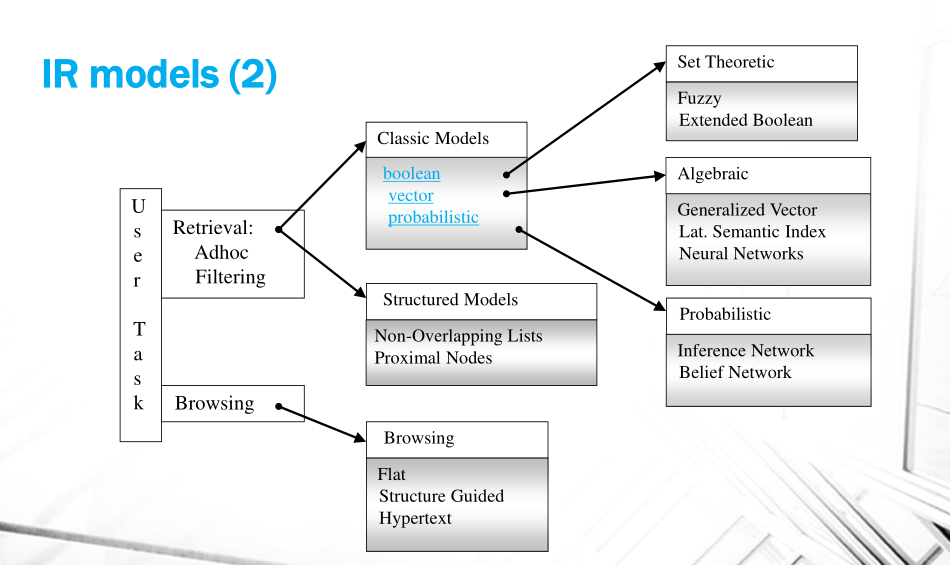
Nel web trattare documenti consiste come prima cosa nella modellazione di un processo di information retrieval (IR). Un modello di IR deve modellare (almeno) le seguenti entità:
I documenti della collezione da indicizzare.
Le query individuali a cui bisogna rispondere.
La funzione di retrieval per effettuare il ranking.
Nella storia si sono definiti vari modelli di IR, tra cui troviamo:
Boolean Models: Questo modello può essere esteso utilizzando i fussy sets, ovvero introducendo delle metriche che rilassano e rendolo graduale il concetto di "membership".
Standard Boolean
Extended Boolean
Vector Models: Utilizzano il prodotto scalare dell'algebra lineare come motore del concetto di rilevanza.
Generalized Vector Space
Latent Semantic Indexing
Neural Models
Probabilistic Models: Non vengono utilizzati per motivi di complessità computazionale, ma all'aumentare delle esigenze sulla rilevanza e all'aumentare del potere di calcolo i modelli probabilistici sono sempre molto potenti. Parte della teoria che riguarda i Belief Network è stata poi riportata nelle reti neurali.
Graficamente,
Ci sono poi altre dimensioni in cui si differenziano i vari modelli di IR in base a come modellano i vari documenti. Queste differenze in ogni caso sono molto specifiche alla particolare applicazione con cui abbiamo a che fare.
È anche importante sfruttare l'utente stesso del sistema per modificare il comportamento del sistema, andando a loggare ciò che l'utente fa e comportandosi di conseguenza.
Possiamo suddividere le tipologie di tasks compiuti da un sistema di IR nei seguenti tre:
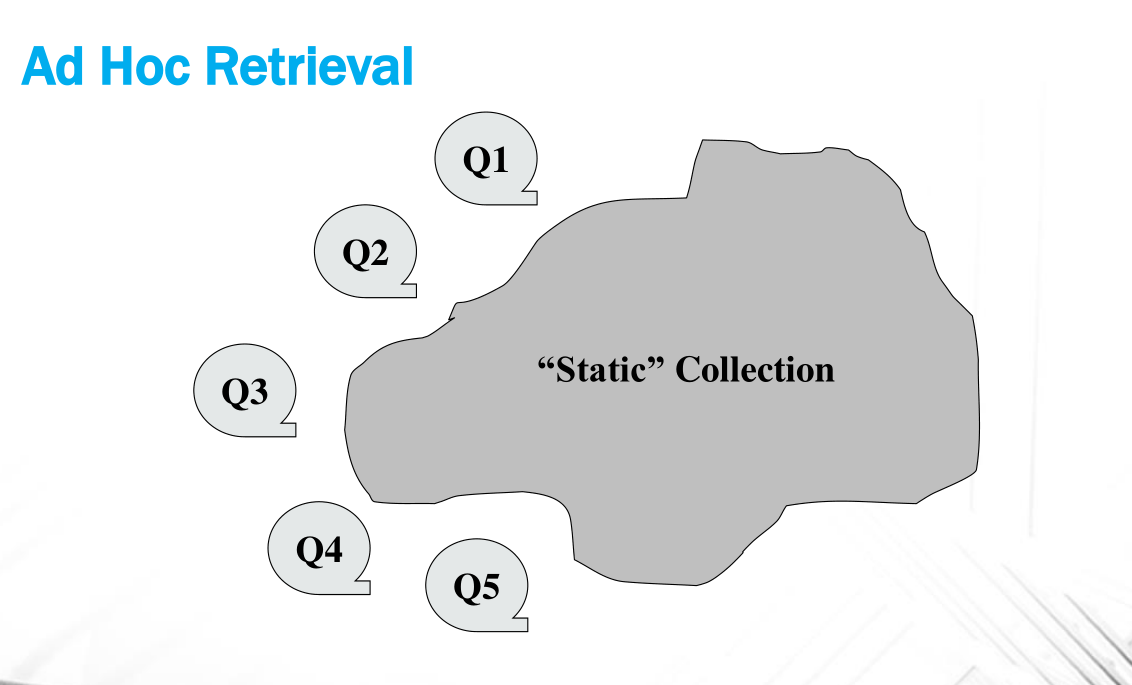
Ad-hoc retrieval: Collezione di documenti relativamente stabile e una quantità molto elevata di query da parte degli utenti.
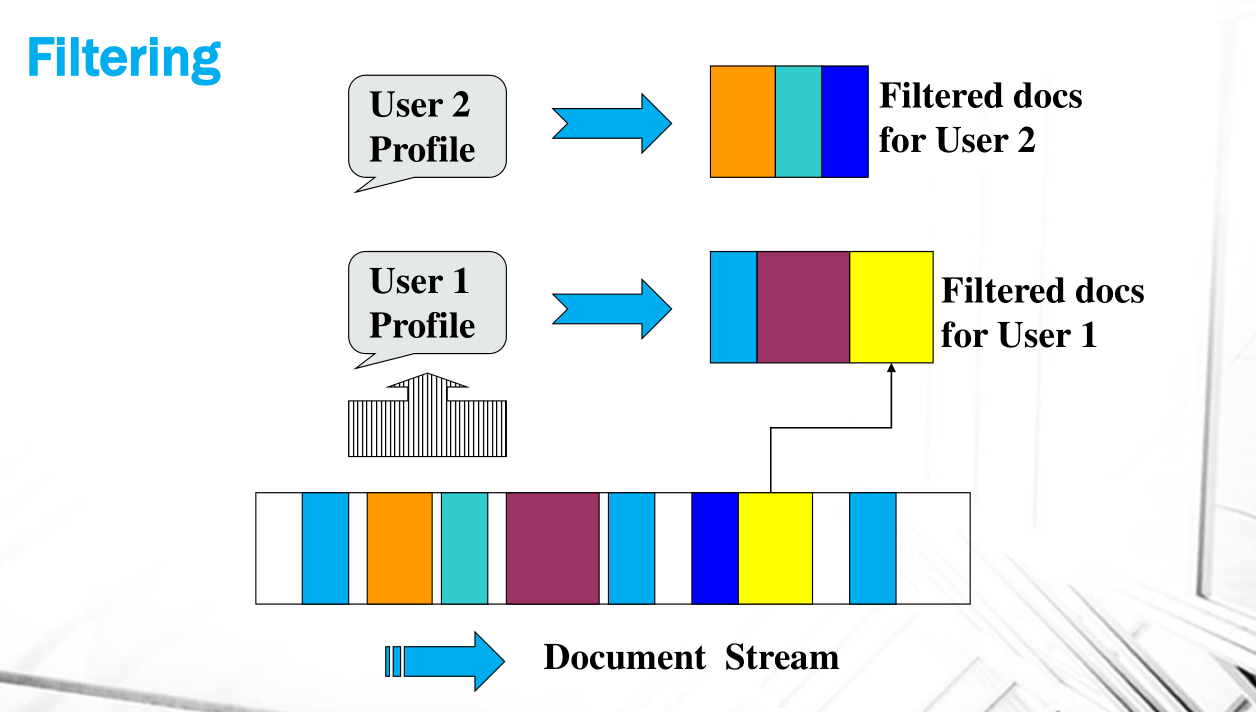
Information Filtering: Query fisse e continuo stream di documenti. Possiamo avere un filtro tipico per ogni utente, o categoriale che vale per una grande fetta di utenti. I filtri categoriali ci spingono verso la text classification. Queste funzioni di filtraggio possono essere binarie o continue.
Information Routing: Quando i filtri cambiano continuamente e sono dinamici.
I task di retrieval non possono essere risolti da funzione analitica, in quanto:
Sono task estremamente parametrici, sia rispetto all'utente, sia rispetto alla base documentali.
Data la mancanza di struttura nei dati da processare, devo affidarmi ad una nozione che mi dice come è fatto il contenuto di un certo dato.
L'idea quindi è quella di imparare una rappresentazione approssimata della natura del documento a partire dalle parole in esso contenute.
Questo processo di comprensione testuale è legato (almeno) ai seguenti processi:
Information Extraction: Capire un documento significa capire tutti i concetti e le relazioni che quella fonte testuale ci fornisce. In questo processo troviamo i seguenti tasks:
Entity Recognition and classification
Relation Extraction
Semantic Role Labeling, che consiste nel costruire una rappresentazione delle relazioni dei concetti presenti in un testo, permettendo così facendo di generare una forma logica che rappresenta le frasi.
Estimation of Text Similarity
Textual Entailment: Capire se una frase implica logicamente un'altra frase.
Sense disambiguation: Quanto verosimilmente una parola ambigua viene utilizzata con una particolare interpretazione all'interno di un testo.
Semantic Search, Question Classification, and Answer Ranking
Knowledge Acquisition
Social Network Analysis