WMR 10 - Natural Language Processing II
Lecture Info
Date:
Course Site: Web Mining e Retrieval (a.a. 2019/20)
Lecturer: Roberto Basili.
Slides: ()
Table of Contents:
In questa lezione abbiamo continuato ad introdurre le proprietà del linguaggio naturale.
1 Ambiguity
Riprendiamo il discorso sul linguaggio naturale notando che l'ambiguità si può presentare a livelli di interpretazione diversi, che sono
Phonology.
Morphology.
Syntax.
Semantics.
Ogni volta che incontriamo una ambiguità in un livello di interpretazione andiamo a biforcare i possibili significati associabili all'oggetto linguistico che ha generato l'ambiguità. Tipicamente il numero di interpretazioni cresce in modo esponenziale rispetto al numero di ambiguità.
Per poter gestire queste ambiguità devo quindi essere in grado di generare più rappresentazioni per un dato testo, ciascuna delle quali rappresenta una particolare interpretazione. Questo può essere fatto andando ad aggiungere ai dati delle features che a prima vista potrebbero sembrare ridodanti, ma che a lungo andare ci permettono di gestire le ambiguità.
Per evitare interpretazioni sbagliate l'idea è infatti quella di avere a disposizione tutte le interpretazioni possibili, per poi scegliere le \(k\) migliori. Se non facciamo questo potremmo prendere una decisione sbagliata inizialmente, e questo potrebbe aumentare l'errore in modo significativo.
2 The NLP Process
Andiamo adesso a vedere il processo per gestire il linguaggio naturale. Le fasi principali di un tipico processo di NLP sono descritte dal seguente diagramma
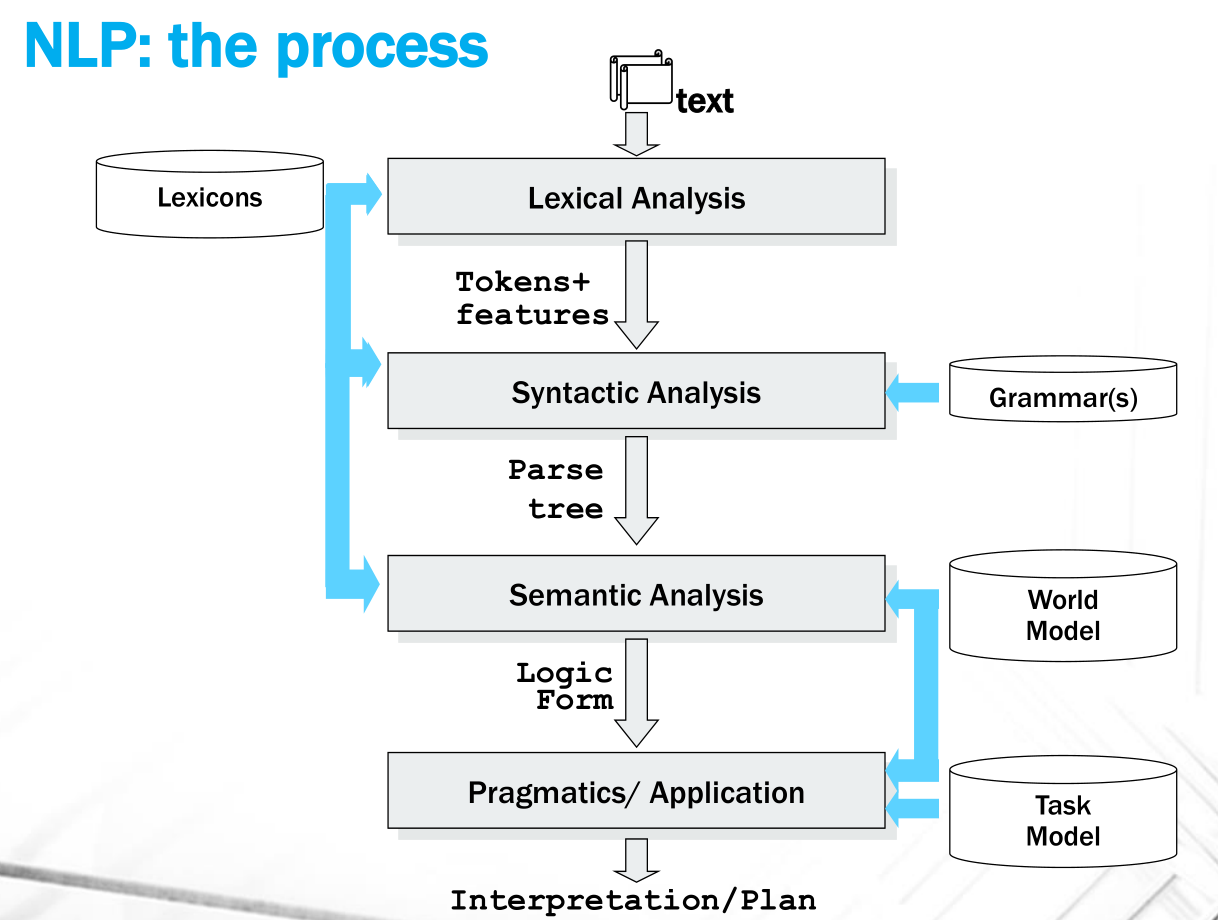
Le varie fasi sono così descritte:
Lexical Analysis: Si individuano le parole (tokens), e si associano ad ogni parola delle proprietà (features), come le informazioni morfologiche o il part of speech (POS-tagging). Per fare questo utilizzo le risorse disponibili per la determinata lingua in analisi, come ad esempio il dizionario.
Syntactic Analysis: Utilizzo di una grammatica che dato il lessico di una sequenza di token di una lingua è in grado di costruire il parse tree della sequenza di token per verificare se la sequenza dei token è stata effettivamente generata dalla grammatica della lingua in analisi.
Semantic Analysis: Permette di costruire, a partire dal parse tree, una forma logica della frase, che mi permette poi di applicare dei meccanismi di ragionamento automatico. Per costruire questa forma logica devo utilizzare un modello del mondo (world model), che mi permette di capire come sono descritti i concetti nel mondo in analisi.
Pragmatics/Application: Utilizzo di un task model per capire cosa fare a partire dalle forme logiche costruire prima.
Osservazione: Consideriamo il modello Naive Bayes trattato nelle precedenti lezioni. Possiamo affermare che tale modello effettua del word processing, in quanto con NB riducevamo la grammatica in cui ogni sequenza di parole è accettabile, mentre il lessico è l'insieme delle parole osservate dal testo. Quello che manca al NB è il concetto di linguaggio, in quanto il NB è trasparente alla particolare lingua utilizzata. È poi possibile estendere l'impostazione del setting bayesiano a casi più complessi in cui le features non sono necessariamente le parole presenti nel testo. Andando ad aumentare la complessità delle features siamo in grado di aumentare le performance ottenute dal modello.
2.1 Syntactic Analysis
La sintassi è la struttura delle regole che determinato e normano la struttura delle frasi valide per una data lingua.
2.1.1 Parse Tree
Il parse tree è la rappresentazione del processo di parsing, ed è una struttura che esprime l'organizzazione gerarchica dei costituenti, il loro ordine, e il loro tipo grammaticale.
Per costruire un parse tree dobbiamo avere una phrase structure grammar, ovvero grammatiche della seguente forma
S -> NP VP VP -> V NP NP -> Det N
Det, Noun, Verb sono dette categorie di base, o preterminali, in quanto "puntano" direttamente a delle particolari parole del linguaggio (terminali). I preterminali vengono poi combinati tra loro per ottenre dei non-terminali più generali.
Osservazione: Esperimenti in psico-linguistica hanno dimostrato in parte l'esistenza di queste strutture alboree nei fenomeni cognitivi che prendono luogo quando cerchiamo di interpretare il significato di una frase. Più ambiguo è l'albero che costruiamo leggendo una frase e più faremo difficoltà a comprendere il significato della frase.
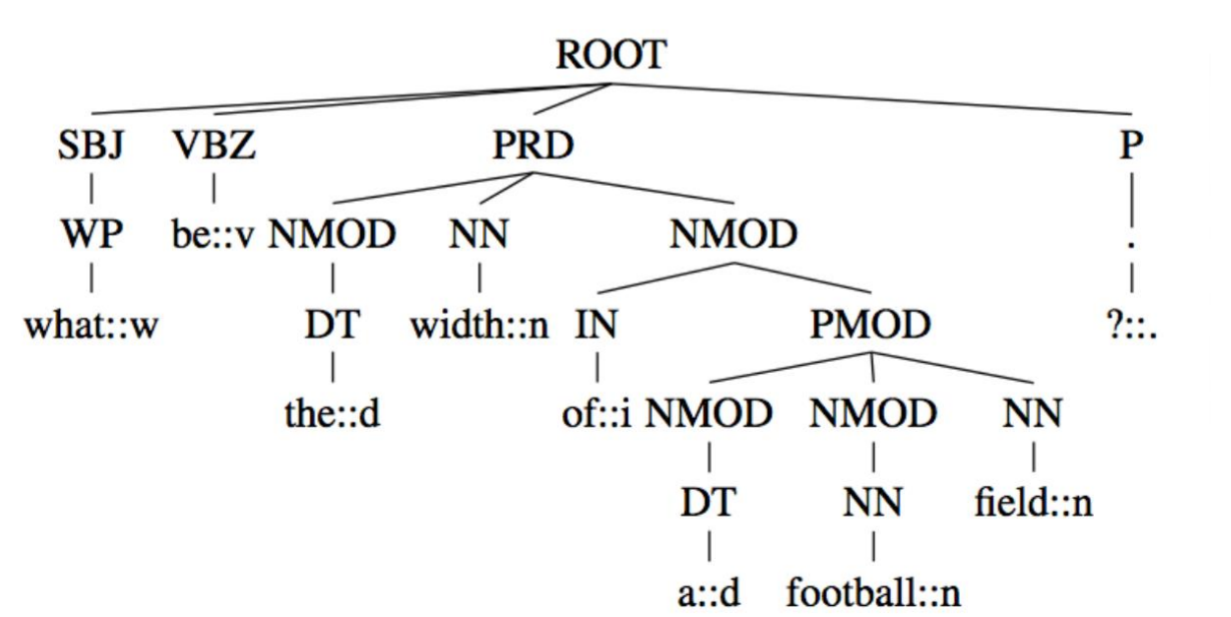
Esempio: La frase "The firm holds some stakes" può essere
rappresentata dal seguente parse tree
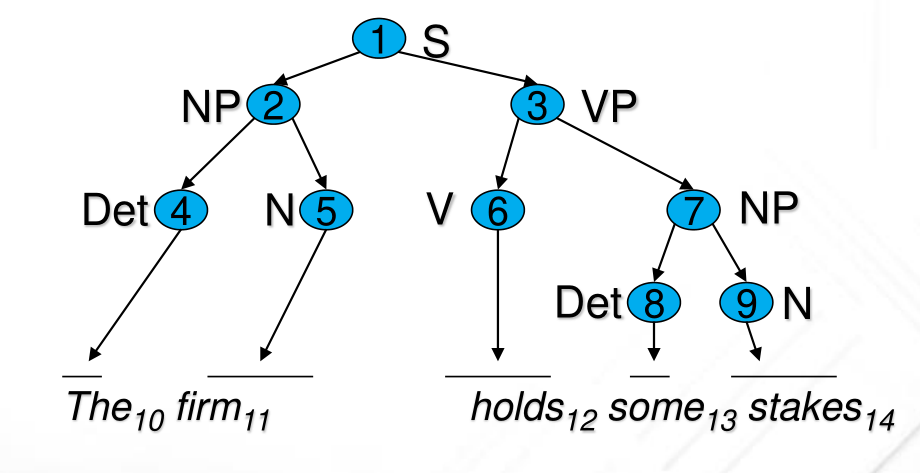
2.1.2 Dependency/Constituency Reations
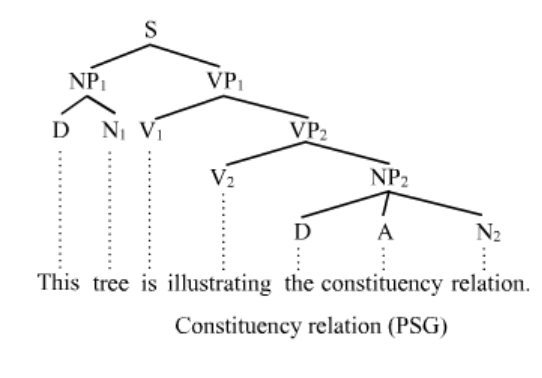
Abbiamo vari modi di rappresentare le informazioni sintattiche, che sono:
Strutture a costituenti:
Strutture a dipendenze:
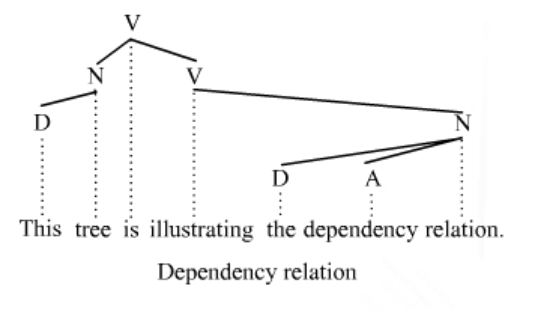
Anche se idealmente questi due modi di rappresentazione ci dovrebbero fornire la medesima interpretazione, a causa di determinati fenomeni linguistici questo non sempre avviene, e dunque in generale questi due metodi di rappresentazione non sono equivalenti l'uno con l'altro. In particolare la struttura a dipendenze può essere sia projective che non-projective: nel caso in cui è projective, allora esiste una corrispondente rappresentazione con i costituenti, ma nel caso in cui è non-projective questo non è più vero.
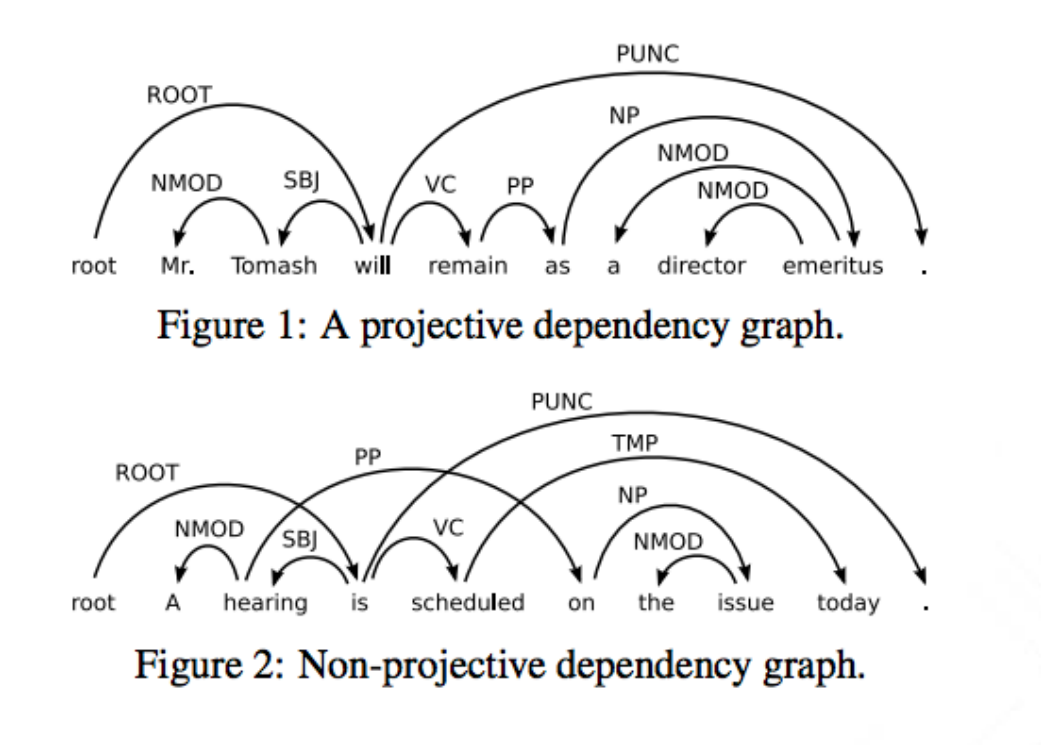
2.1.3 Dependency Parsing
Per effettuare il dependency parsing bisogna risolvere i seguenti task:
Name Entity Recognition: capire i frammenti di una frase che sono espressioni nominali di tipo nome proprio facente parte di una categoria semantica.

Coreference: capire a quale entità fanno riferimento i vari pronomi utilizzati in una frase.

Basic Dependencies: Si inseriscono i legami trovati prima come se fossero archi binari tra parole.
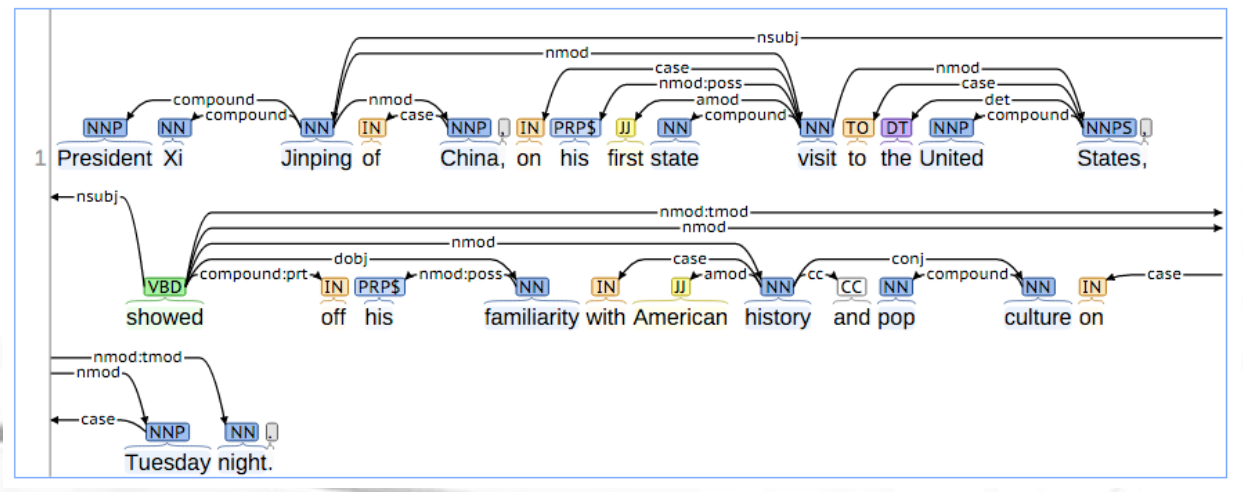
Nel corso vedremo un modello neurale che ci calcola queste basic dependencies.
A partire dalla rappresentazione alle dipendence possiamo generare un albero
2.1.4 Ambiguity in Syntactical Parsing
La frase
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo
sintatticamente è una frase corretta dell'inglese, e questo è il suo parse tree.
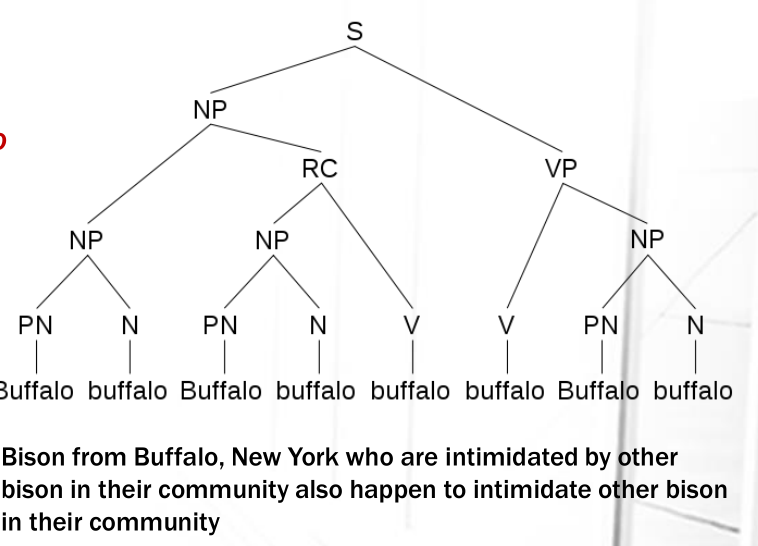
Questo significa che per eliminare le interpretazioni "errate" di una frase dobbiamo far riferimento anche alla semantica della frase, ovvero dobbiamo capire il significato delle parole nella frase.
2.1.5 Modern Parsers
I parsers moderni tendono a generare strutture della seguente forma
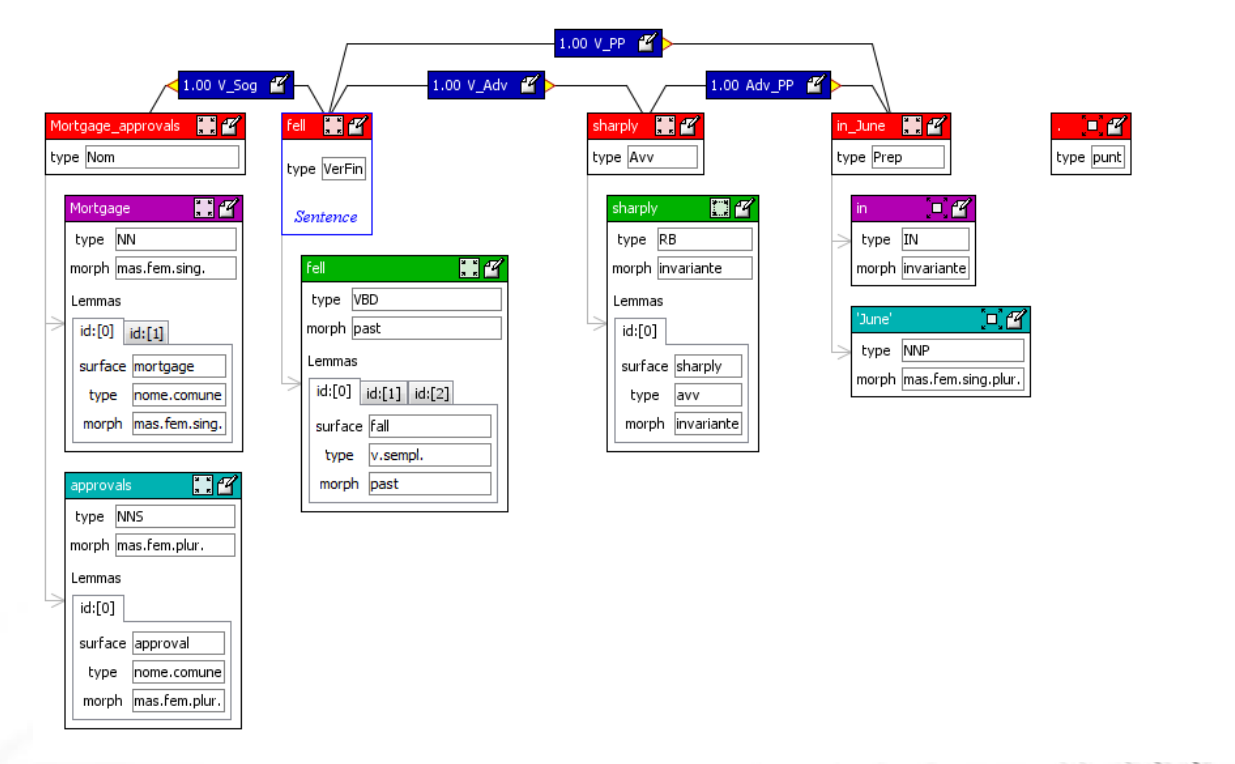
Data una parola chiamiamo le sue morphological features l'insieme delle caratteristiche linguistiche che quella parola possiede per poter poi essere associata alle altre.
I chunk rappresentano le categorie non terminali come le frasi verbali che il sistema racchiude come oggetti unici da relazionare con gli altri chunks.
2.2 Semantic Analysis
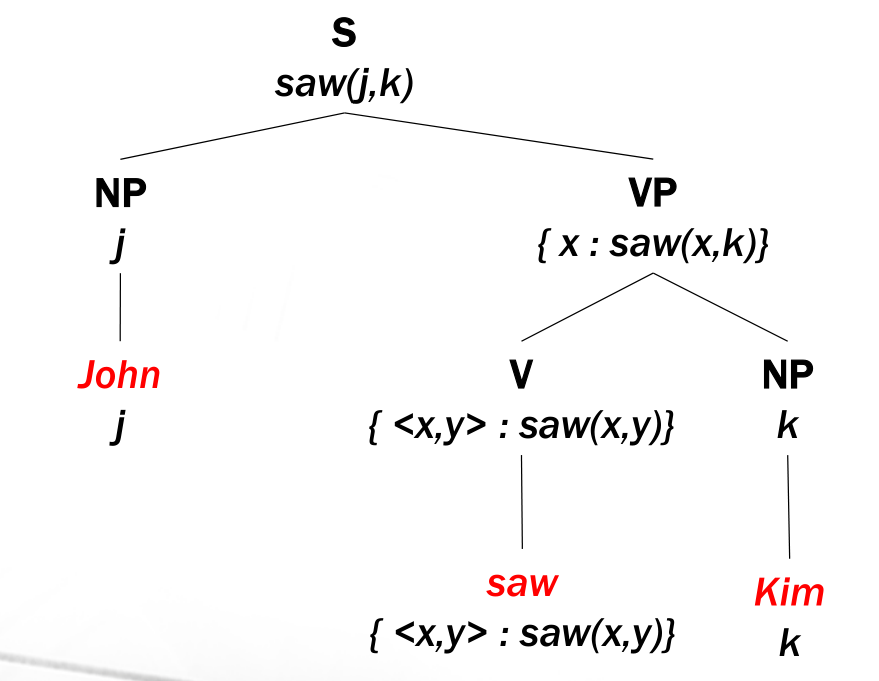
Cosa intendiamo per semantica? Cosa stabilisce il significato di una frase? Ad esempio qual è il significato della frase
John saw Kim
Notiamo che è molto difficile descrivere il significato di una frase, in quanto per farlo siamo costretti ad utilizzare il linguaggio stesso, cioé ciò che vogliamo descrivere.
Per farla breve diremmo di aver capito una frase se dopo aver letto la frase mi "metto in tasca" un oggetto informativo, che può essere una struttura dati nella memoria del mio calcolatore, che è stata ottenuta tramite una riscrittura della frase originale e che presenta determinate proprietà:
Prima di tutto tale struttura deve essere calcolabile a partire dalla frase.
Se poi cambio la frase mantenendo però lo stesso significato, allora anche la struttura che derivo deve rimanere sostanzialmente invariata, ovvero non cambia: il significato è la classe di equivalenza di tutte le forme di parafrasi del linguaggio.
Per dare un'idea di cosa si intende per "struttura dati" in questo contesto, consideriamo il seguente albero
In generale la semantica descrive il modo con cui il linguaggio fa riferimento al mondo fuori dal linguagio e viene utilizzata per far partire qualche tipo di ragionamento.
Il significato di una frase è in parte indipendente dalla specifica forma sintattica in cui la frase si mostra. Detto altrimenti, frasi con diverse rappresentazioni sintattiche potrebbero significare la stessa cosa.
Significato vero condizionale: assumo come vera una frase se il mondo è fatto in un certo modo.
Possiamo avere due alberi sintattici diversi che però portano alla stressa interpretazione semantica.