WMR 11 - Natural Language Processing III
Lecture Info
Date:
Course Site: Web Mining e Retrieval (a.a. 2019/20)
Lecturer: Roberto Basili
Slides: ()
Table of Contents:
1 RevNLT
RevNLT: Parser sviluppato da Basili e Zanzotto scritto in Java.
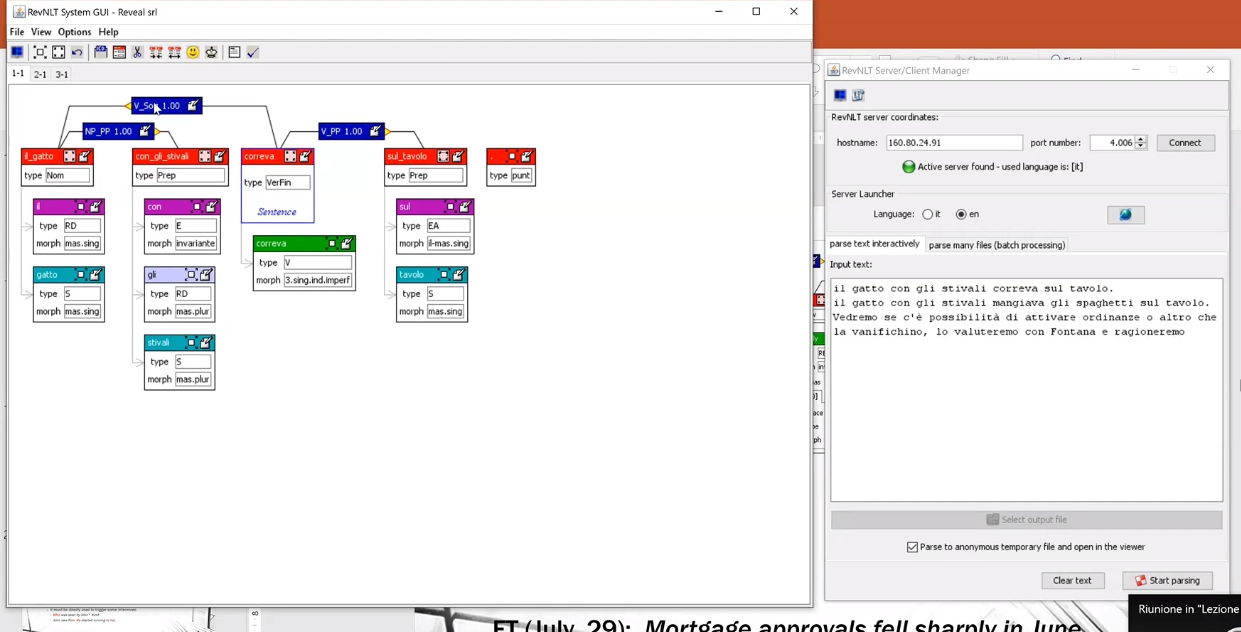
Esempio pratico di rappresentazioni sintattiche che combinano dipendenze e costituenti tramite un programma scritto in Java (RevNLT) che, data una stringa, costruisce il grafo con le informazioni sintattiche sulla fase per poter rispondere a domande del tipo:
Chi è il verbo principale?
Chi è il nome principale?
Quali sono i lemmi delle parole presenti nella frase?
2 Semantinc Analysis (cont.)
Avevamo visto al termine della precedente lezione che la semantica può essere espressa da una qualche forma logica che, se assumiamo di credere alla frase, determina un fatto vero del mondo e tale che, partendo da parafrasi della frase, otteniamo la stessa forma logica. È proprio a partire da questa forma logica che possiamo poi rispondere ad una serie di domande.
La forma logica è una riscrittura in un linguaggio machine readable del significato di una frase, dove per significato linguistico di una frase si può intendere la classe di equivalenza delle parafrasi, ovvero delle riscritture sintattiche della frase che però dicono la stessa cosa, ovvero che, se assunte vere, mi permettono di rispondere ad un determinato insieme di domande nello stesso modo.
2.1 Compositionality
Un modo per generare queste strutture semantiche è quello di andare dal basso verso l'alto andando a comporle e specializzarle. Consideriamo l'albero visto nella precedente lezione
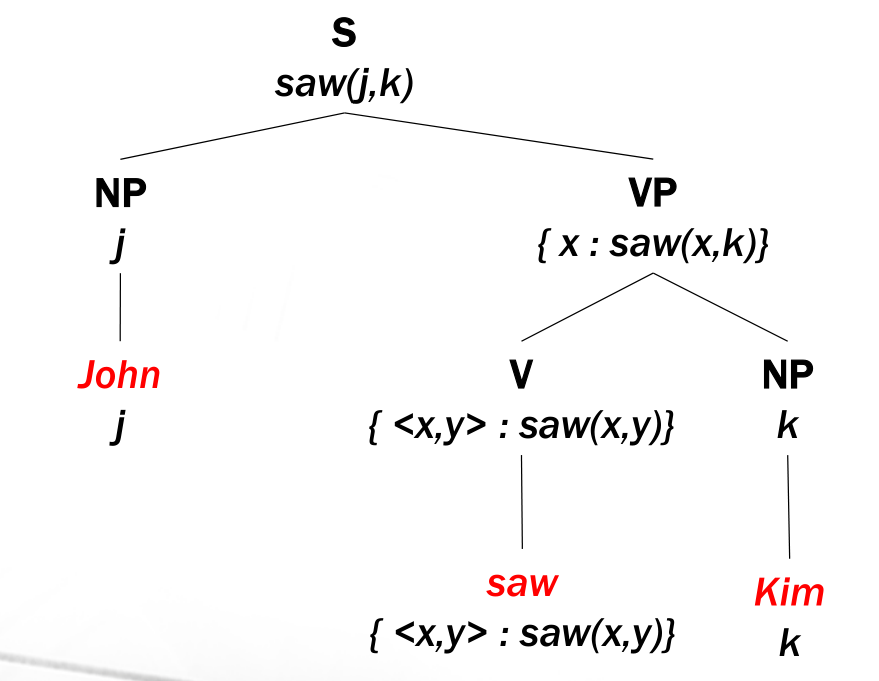
Nell'albero dell'esempio abbiamo specializzato la forma logica \(\text{saw}(x, y)\) andando a mettere \(\text{John}\) nello slot \(x\) e ottenendo la forma logica \(\text{saw}(\text{John}, y)\). Notiamo come quest'ultima situazione è molto più specifica di quella precedente, in quanto è vera in meno casi.
Questo procedimento di costruzione del significato si basa sul meccanismo della composizionalità: la funzione che rappresenta il significato del totale è una funzione che opera sulle funzioni che rappresentano il significato delle componenti.
Questo meccanismo necessita quindi di una procedura in grado di generare in modo automatico la rappresentazione in forma logica scelta. Il processo deve garantire che le inferenze che possiamo fare a partire dalla forma logica scelta (rappresentazione) devono essere le stesse che effettuerebbe un parlante della lingua a partire dalla frase originale.
2.2 Towards Lambda-Calculus
La forma logica a cui vogliamo arrivare deve essere simile alle forme presenti nella logica del primo ordine, come ad esempio le seguenti
\[\begin{split} &\text{Giuseppe runs} \\ \;\;\;\;\;\;\;\;\; &\rightarrow \text{run}(\text{Giuseppe}) \\ \\ &\text{Every student writes programs} \\ \;\;\;\;\;\;\;\;\; &\rightarrow \forall x: \,\, \text{student}(x) \implies \Big(\exists \; p: \,\, \text{program}(p) \land \,\, \text{write}(x, p) \Big) \\ \end{split}\]
Perché utilizziamo questo particolare linguaggio? Notiamo infatti che anche se concettualmente nulla impedirebbe ai matematici di utilizzare il linguaggio naturale, il linguaggio logico ha una serie di proprietà che lo rendono tremendamente utile. Tra queste troviamo:
È sintetico, ovvero mi dice solo quello che mi serve.
È non ambiguo, ovvero mi dice tutto quello che mi serve con un certo rigore, senza fraintendimenti.
Tipicamente nella traduzione da linguaggio naturale a linguaggio fisico abbiamo il seguente mapping: i verbi e i nomi comuni tipicamente mappano in predicati, mentre i nomi propri mappano in simboli atomici.
Ci sono delle frasi che non siamo in grado di tradurre nella logica del primo ordine in quanto non sono frasi predicative, ma sono frasi dubitative, e predicano sull'azione intrapresa dalle entità, e non sulle entità. Non basta quindi la logica del primo ordine. Nelle applicazioni del web però esiste sempre una mappatura del contenuto semantico dei dati in una rappresentazione del primo ordine semplice.
Le forme logiche corrispondenti ai VP sono delle funzioni che prendono delle entità e le mettono come argomenti al fine di generare delle proposizioni completamente predicative.
2.3 Lambda-Calculus
Al posto di utilizzare la scrittura funzionale solita andiamo ad utilizzare l'astrazione lambda per ottenere
\[f(x) = x + 1 \longrightarrow \lambda x . x + 1\]
Questa struttura sintattica mi permette di introdurre le funzioni senza dover introdurre dei simboli per dare il nome alle funzioni.
Nel nostro esempio particolare l'utilizzo del lambda calcolo ci permette di ottenere le seguenti astrazioni:
Astrazione dei soggetti che corrono.
\[\lambda x . \text{run}(x)\]
Astrazione dei soggetti che vedono \(g\).
\[\lambda x . \text{see}(x, g)\]
Astrazione degli oggetti che m vede.
\[\lambda x . \text{see}(m, x)\]
Astrazione dell'azione di vedere
\[\lambda x . \lambda y . \text{see} (x, y)\]
A seconda di come effettuo la procedura di filling posso ottenere vari significati.
La rappresentazione offerta dal lambda calcolo mi permette di eseguire la stessa procedura per chiamare qualsiasi tipo di lambda espressione, senza dover specificare il nome della particolare lambda espressione. In particolare quindi per calcolare il significato di una espressione devo applicare la stessa procedura ricorsiva.
Così facendo sto fondendo assieme la sintassi e la semantica.
2.4 World Model
Il World Model è come il modello entità relazioni delle basi dati, ovvero mi permette di modellare le relazioni e le entità. In genere questo modello è anche chiamato ontologia.
Nel nostro lessico troviamo anche le lambda astrazioni che corrispondono alle singole parole da processare. Un pezzo del world model si esprime attraverso il lessico.
2.5 Meaning
È possibile distinguere almeno tre diversi livelli di interpretazione del significato, che sono:
Lexical semantics: il significato delle singole parole.
Formal semantics (o Compositional Semantics o anche Sentential Semantics): descrive il modo in cui i significati lessicali si combinano tra loro per ottenere il significato di una frase intera.
Discourse (o Pragmatics): Descrive lo scopo della mia comunicazione linguistica.
2.6 Lexical Semantic
Ci sono varie relazioni tra i significati delle parole. Alcune di queste sono:
omonimia: due segni con lo stesso significato.
polinomia: un segno con diversi significati.
sinominia: due segni hanno almeno un significato in comune.
antinomia: due segni rappresentano significati opposti.
iperonomia: un segno con un significato che più generale di un altro segno.
3 WordNet
I vari significati delle parole sono messi assieme in delle reti.
La rete per eccellenza più famosa in questo contesto è la rete WordNet, che è stata ideata da un insieme di lessicografi, che hanno preso i nomi della lingua inglese e hanno definito la rete andando ad organizzare i vari significati di una parola in synsets.
È possibile utilizzare wordnet utilizzando il seguente link. Andando a cercare la parola meaning troviamo il seguente risultato

Tramite WordNet possiamo ricondurre una paorla, come "meaning", a dei synsets, dove ciascun synset rappresenta un particolare significato della parola. L'insieme dei synsets rappresentano quindi tutti i significati che la parola può assumere.
4 Esercizi
Esistono due processori di nlp diversi, che sono stacy e standford nlp code chain. Fare qualche esperienza di analisi di piccoli testi utilizzando queste librerie, come ad esempio il dataset di Q/A che abbiamo utilizzato con Weka nel laboratorio precedente.
Leggere i seguenti capitoli del libro Speech and Language Processing di Jurasfky and J. H. Martin:
Syntax, 12.1-12.3, 15-1-15.2
Semantics: 16.1-16.2, 19.1-19.3
Word senses: 20.1-20.3
Framnet: 20.5
5 Semantic Parsing
Il semantic parsing è il processo di costruzione delle rappresentazioni semantiche delle nostre frasi. L'idea è quella di passare da un albero sintattico ad una forma logica tramite un mapping tra la stuttura semantica predicativa e la struttura sintattica.
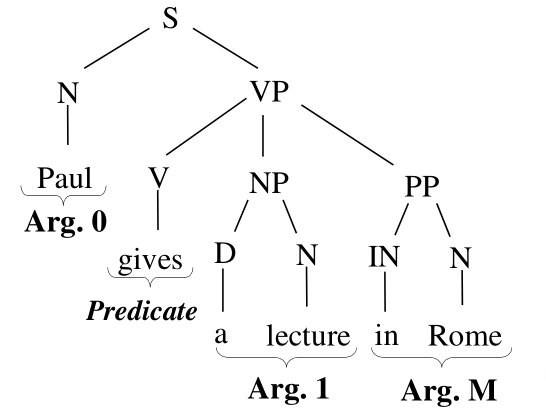
I verbi vengono mappati in predicati, mentre le entità in argomenti. Il problema è quindi quello di capire come gli argomenti sono relazionati ai predicati.
5.1 Frame Net
Noi utilizzeremo FrameNet per dare una struttura ai predicati e capire quali sono gli argomenti da inserire.
Rispetto alla frase di prima ad esempio la presenza della parola \(\text{arrested}\) attiva un particolare frame, ovvero una serie di aspettative rispetto al contesto della frase e rispetto agli argomenti del predicato. Nel nostro caso ad esempio gli argomenti sono tre, e descrivono rispettivamente:
Authority: L'autorità che esegue l'arresto.
Suspect: L'oggetto dell'arresto.
Offense: La causa dell'arresto.
Graficamente,
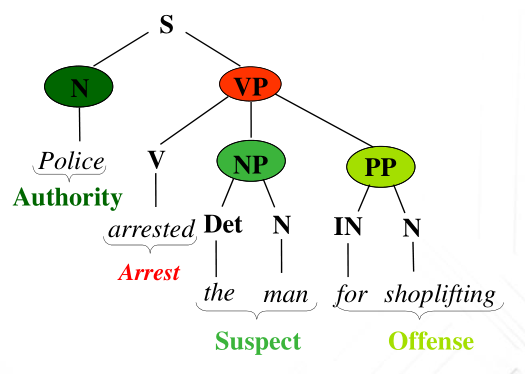
Utilizzando FrameNet il processo di semantic parsing può essere caratterizzato dai seguenti tre passi:
Decido il verbo.
Seleziono il frame che quel verbo può sostenere, e se c'è dell'ambiguità posso fare un passo di inferenza e scegliere un particolare frame.
Determino i diversi argomenti del frame scelto (argument detection)
Assegno ai singoli argomenti il tipo corrispondente.
Possiamo rappresentare la stessa situazione anche con la seguente tabella
\[\begin{array}{c | c | c} \textbf{Word} & \textbf{Predicate} & \textbf{Semantic role} \\ \hline \text{Police} & \text{-} & \text{Authority} \\ \text{arrested} & \text{Target} & \text{Arrest} \\ \text{the} & \text{-} & \text{Suspect} \\ \text{man} & \text{-} & \text{Suspect} \\ \text{for} & \text{-} & \text{Offense} \\ \text{shoplifting} & \text{-} & \text{Offense} \\ \end{array}\]
Gli argomenti dei predicati giocano ruoli specifici, detti thematic roles, che dipendono dal predicato ma non dalla particolare struttura sintattica. I thematic roles che sono stati introdotti dagli anni 70 in poi nell'ambito della linguistica e sono
Agent: Deliberately performs the action described by the verb.
Theme(Patient): Undergoes the action of the verb or is in the state described by the verb.
Experiencer:
Instrument:
Location:
Goal:
Source:
Associative: Performs action with Agent.
Un frame è quindi una rappresentazione mentale di una situazione prototipica che ci permette di capire velocemente la situazione descritta. Un frame è composto da elementi chiamati frame elements ed è invocato dalla presenza di lexical units, ovvero di particolari parole nel testo.
Esempio: Il seguente frame mostra la prototipica situazione di un omicidio.
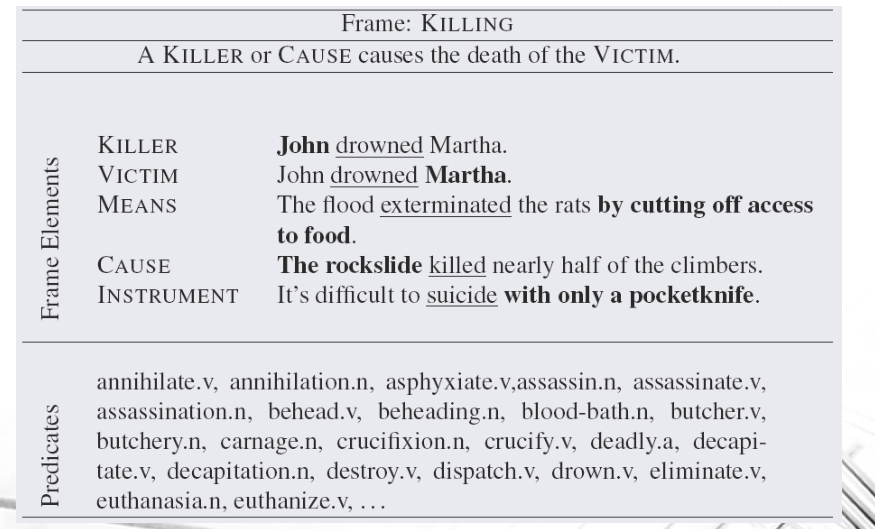
Effettuare semantic parsing significa quindi prendere tutti i frames e tutti i frame elements. Esistono poi dei frame elements che non sono necessari per descrivere un frame, ma sono solo opzionali.
Example: Output del tool Babel per andare ad effettuare semantic parsing.

5.2 SRL Pipeline
FrameNet è stato sviluppato all'università di Berkeley e si è dotato di centinaia di Frames. Ad ogni Frames sono poi associate le parole che lo evocano, raggiungendo > 10.000 unità lessicali, e per ciascun frame abbiamo un corpus di > 135.000 frasi annoate.
Si è poi definito un processo, chiamato SRL Pipeline, che permette di passare dal parse tree sintattico per ottenere la forma logica finale per quella frase. Questo processo è composto da vari passi intermerdi di classificazione in cui il sistema porta avanti soluzioni multiple (problema di ricerca con bound).
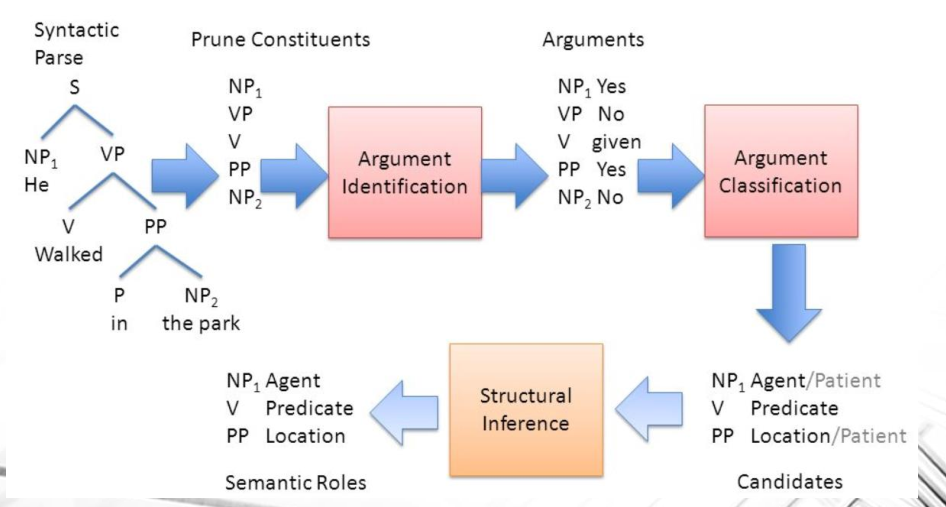
Pre-processing activities in Doocument-based IR
Per ottenere il vettore di proprietà per i documenti ci sono una serie di steps di pre-processing.
Non possiamo fare machine learning dei testi senza conoscerne la struttura interna, in quanto le proprietà che diamo in pasto ai nostri algoritmi di apprendimento non possono essere troppo significative se lasciamo stare le informazioni linguistiche.