Web Scraping con Python
Leonardo Tamiano
Created: 2021-06-21 lun 22:08
Table of Contents
What is Web Scraping?
Per "web scraping" si intende l'utilizzo di una serie di tecnologie al fine di estrarre dati dal web (tipicamente da pagine HTML) in modo da poterli poi processare come si vuole.
Un tipico esempio di web scraping consiste nell'estrarre dei dati di interesse da una pagina web per poi metterli in un'altra pagina web, andando però a cambiare lo stile utilizzato per mostrare i dati.
Document Object Model
I file scritti in HTML possono essere rappresentati tramite una struttura dati chiamata Document Object Model (DOM). Il DOM è una struttura alborea che contiene sia la struttura del documento e sia il contenuto del documento.
<!DOCTYPE html>
<head>
<title> Titolo Pagina </title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>
<div id="content">
<h1> Headline level 1 </h1>
<p> This is a paragraph! </p>
<div id="footer">
<p class="author"><b>Author</b>: Leonardo Tamiano</p>
</div>
</div>
</body>
</html>
Esempio file HTML

Esempio DOM generato con live-dom-viewer

Esempio DOM generato con Graphviz
Tipicamente le librerie utilizzate per fare web scraping funzionano in due passi:
- Si costruiscono il DOM rappresentante il documento da analizzare.
- Offrono una serie di APIs per muoversi all'interno del DOM e raccogliere solamente i dati di nostro interesse.
Beautiful Soup
Beautiful Soup è una libreria Python che ci permette di fare web scraping.
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
Source: Beautiful Soup
Installation
Per quanto riguarda l'installazione possiamo utilizzare pip, il packat manager per python.
pip install beautifulsoup4
Generating the DOM
Supponiamo di aver salvato il codice html fatto vedere prima nel file web_page_example.html. Per generare il DOM possiamo procedere come segue
#!/usr/bin/env python3
from bs4 import BeautifulSoup
# -- read file
f = open("./web_page_example.html", "r")
text = f.read()
# -- generate DOM structure
soup = BeautifulSoup(text, 'html.parser')
Navigating the DOM
Una volta che abbiamo generato la struttura DOM la possiamo navigare in vari modi:
Trovare tutti i tags di un certo tipo
# -- find all tags of the form <p> ... </p> paragraphs = soup.find_all("p")Trovare tutti i tags con un certo attributo
# -- find all tags of the form <div id="footer"> ... </div> footer_div = soup.find("div", {"id": "footer"})
A partire da un nodo del DOM possiamo ripetere la ricerca per trovare tutti i tags contenuti in quel particolare sotto-albero del DOM.
if footer_div: # -- find firsts <p>...</p> inside <div id="footer"> ... </div> author_p = footer_div.find("p")Possiamo anche esplorare il DOM utilizzando la notazione con il punto (.) come segue
author_p = footer_div.pCosì facendo però non siamo sicuri se l'elemento a cui stiamo tentando di accedere esiste davvero.
Extracting Data from the DOM
Una volta che abbiamo i tag di interesse possiamo accedere ai dati veri e propri come segue
# -- get all data
print(author_p.decode_contents()) # prints: <b>Author</b>: Leonardo Tamiano
# -- get only text data # prints: Author: Leonardo Tamiano
print(author_p.text)
Il codice esempio fatto vedere è disponibile al seguente link:
Real (Life) Example
Consideriamo la seguente pagina, che mostra gli orari delle lezioni.
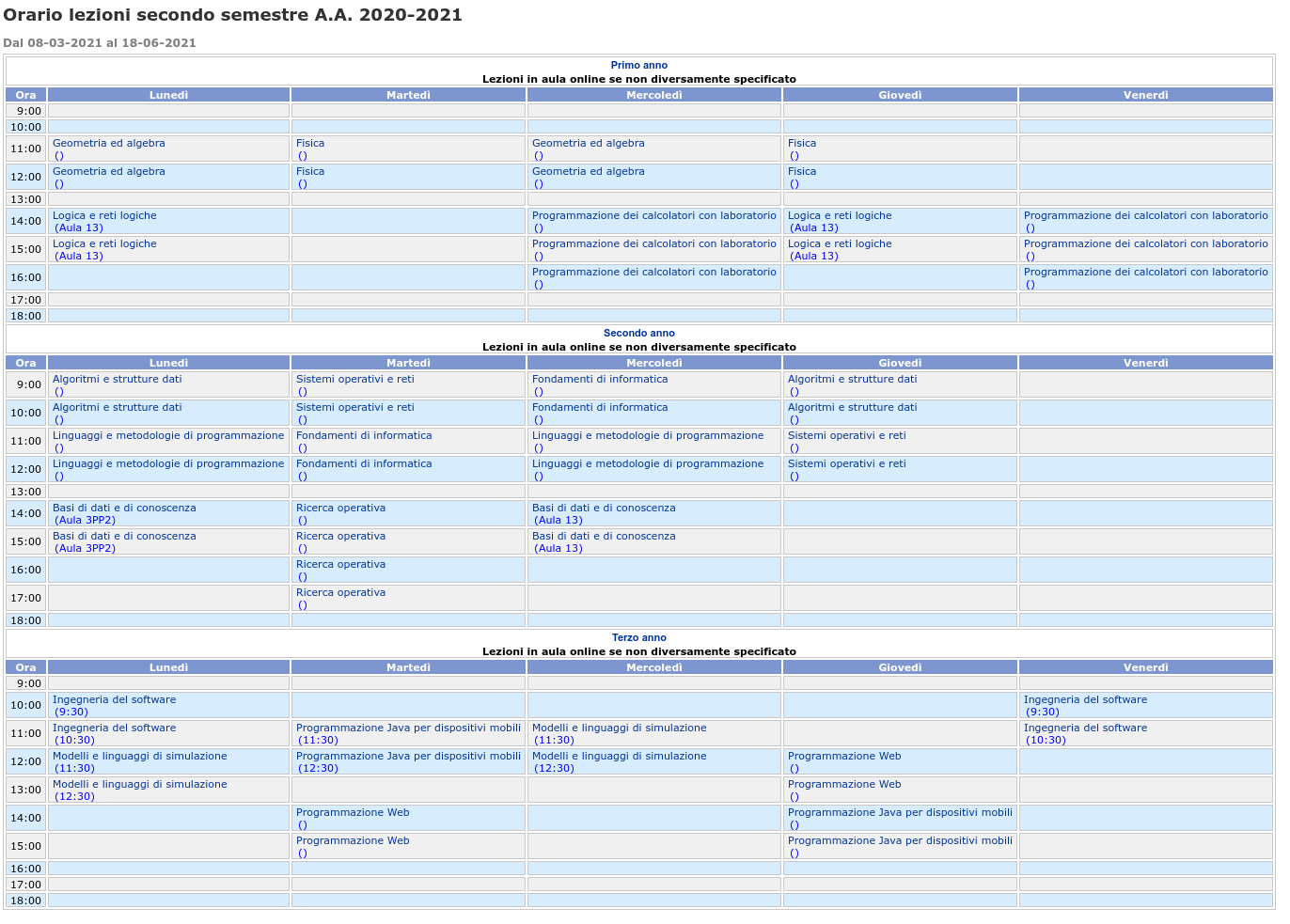
Ripreso da: http://www.informatica.uniroma2.it/
Il nostro obiettivo è scaricare il file .html contenente le informazioni degli orari e salvare i dati in un file .csv, in modo poi da poterli processare a nostro piacimento.
Lo script python che fa questo è disponibile al seguente link: