AOS - 09 - KERNEL PROGRAMMING BASICS II
1 Lecture Info
Data:
Sito corso: link
Progresso unità: 2/6
Argomenti:
Selettori in x86
GDT entries in x86
Accessing GDT table
Introduzione: In questa lezione abbiamo visto come x86 implementa uno schema di memoria segmentata. La lezione è stata terminata introducendo il concetto di Thread Local Storage (TLS).
2 Segment Selectors in x86
Nella lezione precedente avevamo descritto come in uno schema di memoria segmentata gli indirizzi venivano specificati con due informazioni: l'id del segmento a cui volevamo accedere e l'offset all'interno di quel segmento.
Nell'architettura x86 però, al posto di specificare direttamente l'id del segmento che si vuole utilizzare, si specifica invece il nome del registro che contiene l'id del segmento. I registri che contengono gli identificativi dei segmenti utilizzati sono chiamati segment selectors, o selettori di segmento. Quando scriviamo codice utilizzando l'ISA di x86 quindi per accedere ad un dato in memoria dobbiamo specificare la seguente coppia
\[ \langle \text{segment-selector-register}, \text{displacment} \rangle\]
dove eventualmente il nome del selettore può essere utilizzato implicitamente dall'hardware.
I selettori offerti da x86 sono sei, e sono i seguenti:
Singolarmente un selettore di segmento ha la seguente forma
I vari campi sono,
TI (Table Indicator): Specifica la tabella in cui sono memorizzate le informazioni associato a quel segmento, e può assumere due valori: un valore per indicare la GDT e uno per indicare la LDT.
RPL (Requestor Privilege Level): Contiene le informazioni di protezione del segmento e viene utilizzato durante un cross-segment jump per capire se si può accedere al nuovo segmento.
Solo per il segmento CS, il campo RPL viene chiamato CPL, che sta per Current Privilege Level. Il selettore CS inoltre non può mai essere modificato dal programmatore, nemmeno con chiamate di sistema, e può essere modificato solo tramite le variazioni di flusso del codice attraverso le regole menzionate prima.
I selettori che vengono implicitamente utilizzati dal sistema sono: CS, SS, DS e ES. Il segmento ES viene utilizzato in modo implicito per una classe specifica di istruzioni macchina, tra cui le istruzioni che processano le stringhe come stos e movs. I selettori FS e GS invece vengono mai utilizzati in modo implicito dal sistema, e hanno un ruolo fondamentale nella programmazione di sistema.
3 x86 GDT Entries
Dato che la tabella LDT non viene più utilizzata, tutti i selettori di segmento puntano ad una entry della tabella GDT.
Lavorando in protected mode le entries della tabella GDT il seguente formato
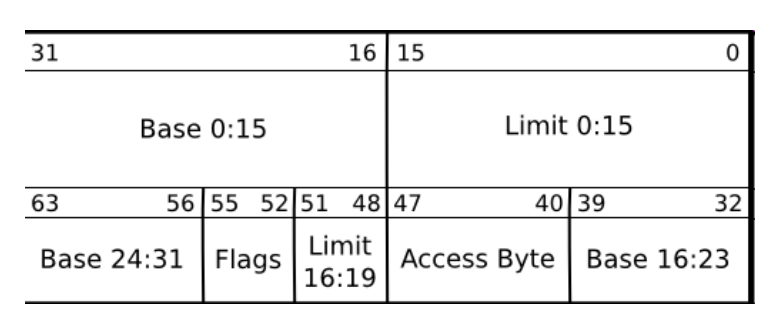
dove i campi sono così descritti
A seconda del valore del campo FLAGS il campo LIMIT può essere espresso a granularità diverse. Ad esempio se il granularity bit presente in FLAGS è 0, allora LIMIT è espresso in blocchi di 1 Byte (byte granularity), invece se il bit è 1 allora LIMIT è espresso a blocchi di 4KB (page granularity).
Il campo Access Byte invece contiene le seguenti informazioni:
Presence bit (PR), deve essere 1 per tutti i segmenti validi.
Privilege bits, i due bit di privilegio che contengono il ring level necessario per accedere al segmento.
Ex, executable bit, deve essere 1 se il segmento può essere eseguito.
Nella modalità long-mode invece la entry della GDT è leggermente diversa. In particolare ci sono più bit sper specificare l'indirizzo di base del segmento.
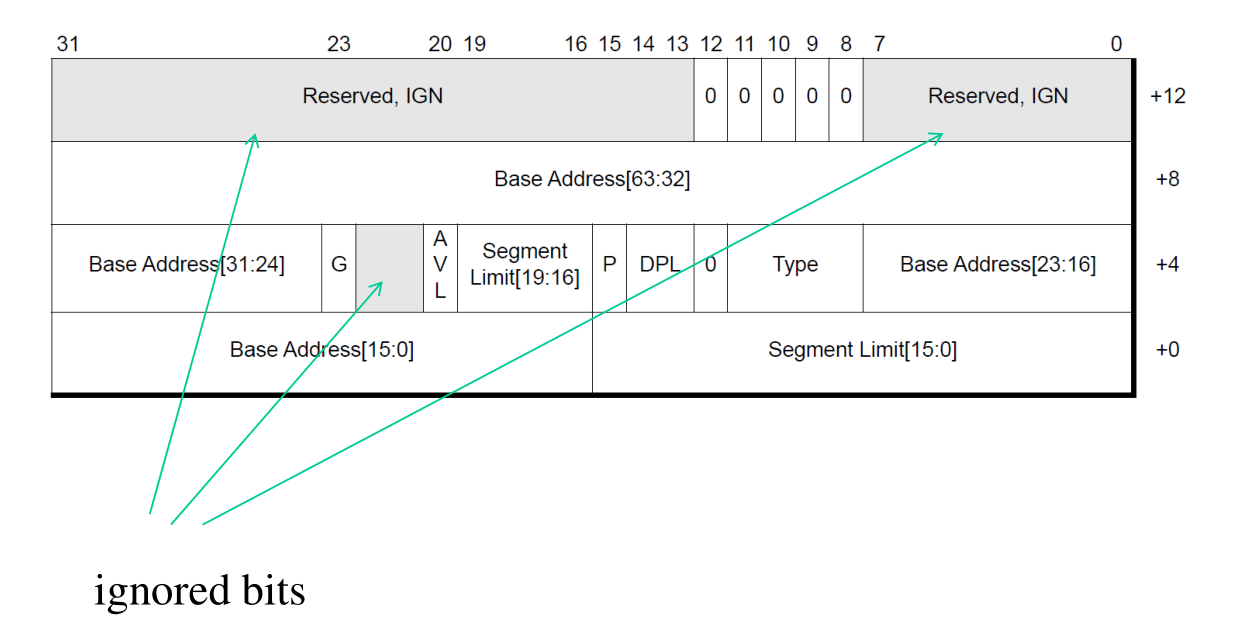
3.1 Accessing GDT entries
La tabella GDT è caricata in memoria durante la fase di
inizializzazione del sistema e viene poi puntata dal registro
gdtr . Il registro gdtr contiene quindi l'indirizzo in memoria della
tabella GDT. Più precisamente il registro gdtr è una packed
structure che contiene non solo l'indirizzo in memoria della
tabella GDT, ma anche la grandezza della tabella.
// struct view of gdtr register struct desc_ptr { unsigned short size; unsigned long address; } __attribute__((packed)) ;
Al fine di calcolare la posizione di una particolare entry della tabella bisogna tenere a mente che i selettori di segmento contengono solamente l'indice di una entry della GDT, e non l'indirizzo di dove si trova la particolare entry. Detto questo, sapendo l'indirizzo di base della GDT, e utilizzando il fatto che ciascuna entry occupa 8 bytes, possiamo accedere alla \(i\) esima entry della GDT lavorando in protected mode utilizzando il seguente indirizzo
\[\text{addr of i-th entry of GDT} = \text{GDT_base_addr} + 8 \cdot i\]
Infine, è importante notare che il size della tabella GDT può essere espresso con al massimo 2 byte di memoria. Questo significa che le tabelle GDT non possono essere troppo grandi.
Esempio: Se la GDT è memorizzata a partire dall'indirizzo
0x00020000 , allora l'indirizzo della entry con indice \(2\) è dato da
\[\text{0x00020000} + 2 \cdot 8 = \text{0x00020010}\]
Se invece lavoriamo in x86 long-mode, allora il registro gdtr
contiene l'indirizzo della tabella espresso nella forma canonica in
64-bit assieme ai soliti 16 bit utilizzati per specificare la
grandezza della tabella.
3.2 GDT-AND-SEGMENTS/gdt.c
Tramite l'istruzione SGDT offerta dall'ISA x86 siamo in grado di
leggere il contenuto del registro gdtr. Il seguente codice non fa
altro che definire una struttura dati packed in modo da evitare
l'eventuale inserimento di padding da parte del compilatore,
utilizzare l'istruzione sgdt per caricare nella struttura definita
prima il valore del registro gdtr, e poi andarlo a leggere tramite
una printf().
#include <stdio.h> #include <stdlib.h> // do not insert padding in the structure. struct desc_ptr { unsigned short size; unsigned long address; } __attribute__((packed)) ; // store the contents of the gdtr register #define store_gdt(ptr) asm volatile("sgdt %0":"=m"(*ptr)) int main(void) { struct desc_ptr gdtptr; store_gdt(&gdtptr); printf("GDTR is at %p - size is %d\n", gdtptr.address, gdtptr.size); return 0; }
Tramite l'utility taskset siamo poi in grado di eseguire lo stesso
programma su CPU diverse. Un esempio di esecuzione ha riportato i
seguenti risultati
# taskset 0x1 ./a.out GDTR is at 0xfffffe0000001000 - size is 127 # taskset 0x2 ./a.out GDTR is at 0xfffffe000002c000 - size is 127
Notiamo che a seconda della CPU otteniamo indirizzi diversi. Questo vuol dire che ogni CPU core ha la propria GDT. Il fatto che ogni CPU core ha la propria GDT è collegato al fatto che la segmentazione ha un ruolo fondamentale nella programmazione di sistema multi-core.
3.3 Linux GDT on x86
La GDT utilizzata da LINUX nelle architetture x86 ha la seguente forma
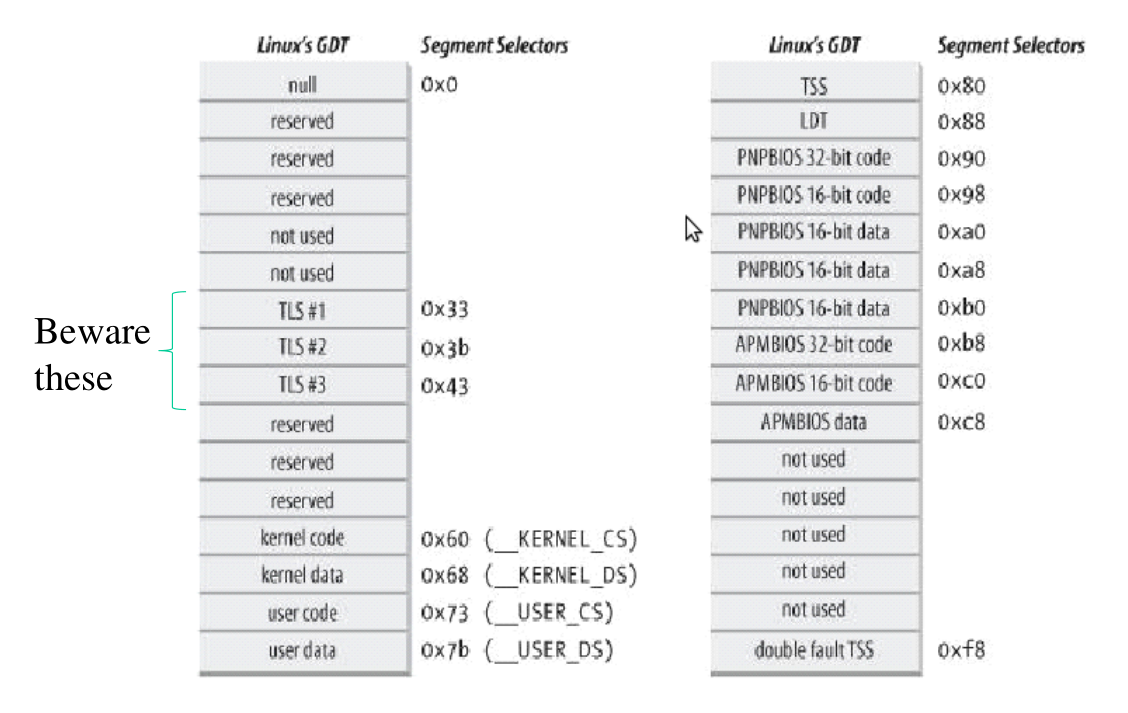
Alcune entry importanti della GDT presente in linux in x86 sono le seguenti
Quando entriamo all'interno di un GATE il codice presente nel GATE dovrà occuparsi di aggiornare le entry della GDT con dei particolari valori per creare una determinata visione della memoria.
Abbiamo dunque due livelli in cui possiamo effettuare delle modifiche:
Possiamo modificare i selettori per farli puntare a diverse entry della GDT. Ad esempio se stiamo eseguendo un programma applicativo il selettore CS punterà all'entry 0x73 della GDT, ovvero al segmento user code (__USER_CS). Se durante l'esecuzione andiamo a chiamare una system call, il kernel prima di iniziare la sua esecuzione dovrà cambiare il valore del selettore CS per puntarlo a una diversa entry della GDT, in particolare la entry kernel code (__KERNEL_CS).
Possiamo modificare i valori della tabella stessa. In questo modo possiamo anche lasciare invariato il selettore utilizzato per ottenere comunque accessi alla memoria diversi. Infatti scrivere una nuova base per una entry della GDT ci permette di accedere a locazioni di memoria diverse utilizzando lo stesso codice.
4 Access Scheme
Dato un indirizzo \(\langle \text{selettore}, \text{offset} \rangle\) lo schema per l'accesso alla memoria base è il seguente:
Dal selettore si tirano fuori le informazioni relative alla tabella da utilizzare. In particolare si capisce se bisogna utilizzare la GDT o la LDT, e si capisce quale entry si vuole leggere.
L'indice di accesso alla GDT viene moltiplicato per 8 e aggiunto all'indirizzo base che ci viene dato dall'istruzione
gdtroldtr, a seconda del valore di TIDalla GDT si ottiene il descrittore del segmento in cui è contenuto l'indirizzo base del segmento.
L'indirizzo base del segmento viene sommato con l'offset per ottenere l'indirizzo lineare.
Graficamente troviamo
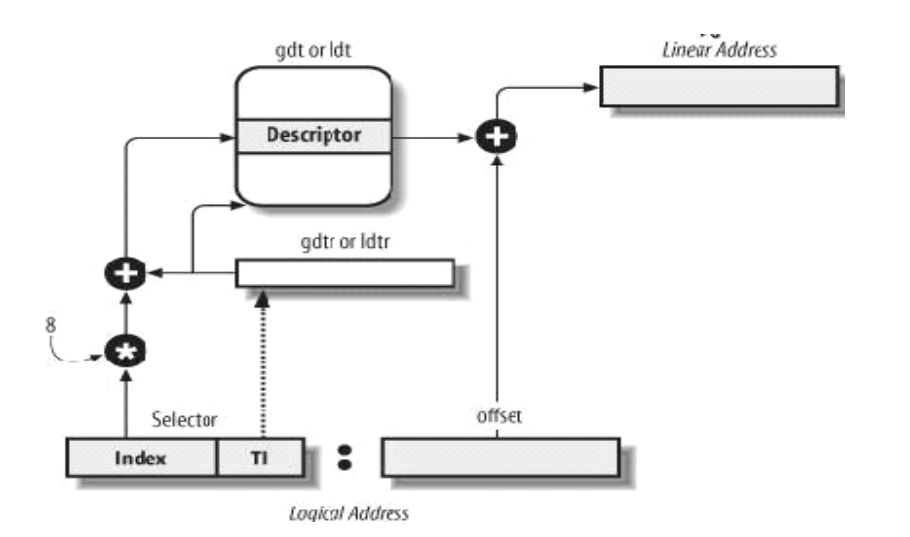
Notiamo che non sempre viene utilizzato questo schema, in quanto altrimenti ogni accesso alla memoria ne implicherebbe un altro (quello per leggere la relativa entry della GDT).
L'idea è quindi quella di utilizzare dei registri non-programmabili della CPU per salvare di volta in volta gli indirizzi base dei segmenti presenti nei selettori. Appena viene cambiato il valore di un selettore quindi l'architettura si va a leggere il nuovo valore di base dalla GDT per metterlo in un registro non-programmabile della CPU. I registri che contengono l'indirizzo di base del segmento non sono flushabili o controllabili in qualsiasi modo dal programmatore.
Graficamente troviamo quindi la seguente situazione
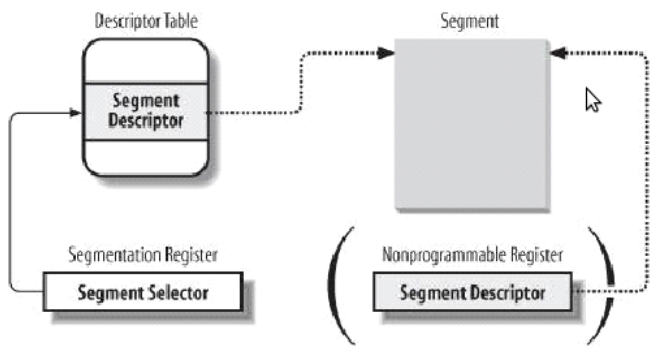
4.1 GDT-AND-SEGMENTS/segments.c
Andiamo adesso a vedere come utilizzare i segmenti in modo esplicito durante la programmazione. A tale define definiamo le seguenti macro che ci permettono di utilizzare i selettori di segmento in modo esplicito
#include <stdio.h> // uses the offset ptr explicitly with the segment DS (data segment) // to access a location in memory and loads the content into variable // var. #define load(ptr, var) volatile asm("mov %%ds:(%0), %%rax ": "=a" (var) :"a"(ptr)) // load the values val into register RAX, and then stores this value // into the memory location obtained by combining the base of selector // DS (data segment) with offset ptr. #define store(val, ptr) volatile asm("mov %0, %%ds:(%1)":: "a" (val), "b" (ptr))
L'utilizzo di queste macro è piuttosto intuitivo.
int main(int argc, char **argv) { unsigned long x = 16; unsigned long y; load(&x, y); printf("variable y has value %u\n", y); store(y+1, &x); printf("variable x has value %u\n", x); return 0; }
Notiamo che se cambiamo l'esecuzione cambiando il selettore e
utilizzando CS e GS , otteniamo lo stesso risultato. Se però
utilizziamo il selettore FS otteniamo un segmentation fault. Questo
comportamento segue dal fatto che i selettori CS , DS e GS hanno
tutti la stessa base, ovvero 0x0 . Invece il selettore FS non è
valido di default e quindi non è mappato nella GDT. Quando
utilizziamo un selettore non mappato nella GDT otteniamo un
segmentation fault.
4.2 Segment Selectors Update Rules
Esistono istruzioni macchina per cambiare il contenuto di ogni selettore di segmento tranne che per il selettore di segmento CS. Il selettore CS infatti gioca un ruolo centrale nel ring-model, in quanto mantiene il CPL (Current Privilege Level). Per questa ragione il selettore CS viene implicitamente aggiornato dal firmware durante le variazioni di flusso.
Tutti gli altri selettori possono invece essere aggiornati da determinate istruzioni se e solo se il DPL del nuovo segmento è tale che DPL >= CPL, ovvero se e solo se il nuovo segmento a cui vogliamo accedere ha un livello di privilegio più alto. In particolare il kernel linux offre delle system call per poter cambiare il descrittore di particolari segmenti.
Nel caso in cui lavoriamo a livello 0, ovvero CPL = 0, possiamo fare qualsiasi cosa nel sistema, e quindi possiamo aggiornare qualsiasi selettore.