AOS - 10 - KERNEL PROGRAMMING BASICS III
Lecture Info
Data:
Sito corso: link
Progresso unità: 3/6
Argomenti:
TSS
GDT Replication
Per-CPU memory
TLS
x86-64 control registers
Control flow in x86
IDT
Trap-based on-demand kernel access
1 Task State Segment (TSS)
Il segmento TSS (Task State Segment) viene utilizzato per mantenere delle informazioni in memoria riguardanti l'utilizzo del modello ring. Inizialmente il TSS è stato introdotto per permettere all'hardware di eseguire i context-switch. Questo supporto però non è stato mai implementato, e attualmente la zona TSS serve solamente per reperire informazioni funzionali al thread in esecuzione.
Quando passiamo da ring \(3\) a ring \(0\) (o viceversa), potremmo scegliere di cambiare non solo i selettori di segmento, ma anche altre cose, come ad esempio la stack area utilizzata, in modo da avere una stack privilegiata utilizzata dai program flow in ring 0 e un'altra utilizzata dai program flow in ring 3. Nasce quindi il problema di ricordarci ogni volta dove si trovata il puntatore in cima alla stack. Il TSS permette di mantenere questa informazione per ogni ogni thread.
Le informazioni contenute nel TSS sono utilizzate dal firmware ma sono anche aggiornate dal software. Ad ogni context-switch infatti la zona TSS cambia. Il TSS ha la seguente forma
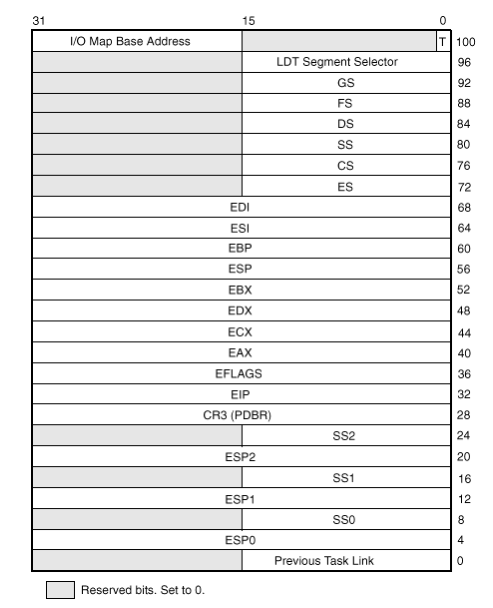
Nella long-mode (x86-64) è stato poi sacrificato lo spazio utilizzato per i general purpose registers al fine di inserire le informazioni sugli stack pointer a 64 bit.
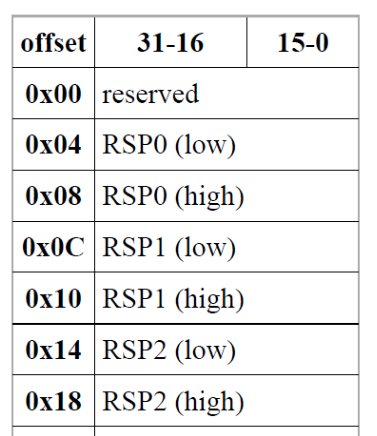
L'istruzione che legge le informazioni dal TSS è l'istruzione
privilegiata LTR (Load Task Register) che può essere eseguita solo
quando ci troviamo a rinng 0 (CPL=0).
2 GDT Replication
Nei moderni sistemi multi-core/multi-processor, la Gobal Descriptor Table (GDT) introdotta in una lezione precedente è replicata su ogni processore.
La replicazione della GDT offre due principali vantaggi:
Ogni processore è in grado di manipolare la propria GDT, e quindi è in grado di modificare la propria vista della memoria senza toccare quella degli altri processori.
Lavorando con architetture moderne di tipo NUMA in cui le latenze di accesso alla memoria sono non-omogenee, avere una GDT per processore ci permette di memorizzare ogni GDT vicino al rispetto processore, e questo ci permette di migliorare le performance.
3 Per-CPU Memory
Un ulteriore beneficio derivante dalla replicazione della GDT è la possibilità di avere una memoria specifica per ogni processore con un accesso trasparente. Con "accesso trasparente" intendiamo il fatto che, utilizzando la stessa combinazione offset+selettore, due processi diversi possono accedere a due zone di memoria diverse, in quanto la base del segmento associata al selettore a cui accedono è diverso. Siamo quindi in grado di accedere a due locazioni diverse di memoria utilizzando le stesse operazioni. Questo concetto prende il nome di per-CPU memory.
La possibilità di avere una per-CPU memory ci permette di migliorare di molto le performance del sistema, in quanto permette di leggere e scrivere informazioni specifiche per un CPU-core senza dovere seguire l'istruzione $\text{CPUID}, che ricordiamo causa la linearizzazione delle operazioni tramite uno squash della pipeline, andando quindi a rallentare il sistema.
In Linux la per-CPU memory è implementata utilizzando il selettore GS. In particolare abbiamo le seguenti macro per definire delle variabili all'interno dello spazio di memoria privato per un processore.
// Definisce una variabile all'interno della per-CPU memory area DEFINE_PER_CPU(int, x); // Leggi la variabile x dalla per-CPU memory area int z; z = this_cpu_read(x); // mov ax, gs: [x] // Ritorna l'indirizzo del dato nella per-CPU memory area y = this_cpu_ptr(&x);
4 Thread Local Storage (TLS)
Il Thread Local Storage (TLS) è un modo per avere una memoria locale ad ogni singolo thread. L'implementazione di questo supporto utilizza la segmentazione della memoria. L'idea infatti è che se i selettori di segmento puntano a segmenti con indirizzi di base diversi, allora anche con lo stesso offset siamo comunque in grado di accedere a due locazioni di memoria diverse.
Al fine di offrire questo meccanismo di TLS all'interno della GDT ci sono delle entry che possono essere modificate a livello user. In particolare è possibile cambiare parte della memory view del thread in esecuzione utilizzando delle particolari system call, che vanno a modificare i descrittori di segmento associati ai selettori FS e GS.
Ogni volta che un thread viene messo in esecuzione su una CPU il software del kernel si preoccupa di ripristinare il corretto valore per i descrittori di segmento relativi ai segmenti \(\text{TLS #1}\), \(\text{TLS #2}\) e \(\text{TLS #3}\) all'interno della GDT del processore.
La systam call che ci permette di modificare questi descrittori di segmento è la
arch_prctl(int code, unsigned long *addr)
Questa chiamata può essere di due tipi:
Transazione: consiste nello scrivere un nuovo valore di base all'interno del relativo descrittore di segmento
Query: legge le informazioni del descrittore.
I possibili codici sono i seguenti
ARCH_SET_FS: Modifica l'indirizzo base del descrittore di segmento associato a FS.
ARCH_GET_GS: Modifica l'indirizzo base del descrittore di segmento associato a GS.
ARCH_GET_FS: Leggi la base associata al segmento associato a FS.
ARCH_SET_GS: Leggi la base associata al segmento associato a GS.
4.1 GDT-AND-SEGMENTS/thread-segment-management.c
Questo particolare esempio mostra come il selettore FS viene
utilizzato da gcc per implementare un meccanismo di TLS. In
particolare se il compilatore vede che c'è utilizzo di TLS (ovvero
variabili definite con __thread), allora la funzione pthread_create
gestisce la creazione del TLS tramite le chiamate di sistema
arch_prcrl() .
La prima cosa che fanno i due threads che vengono creati è leggeere
l'indirizzo della propria zona TLS tramite la system call
arch_prctl() .
arch_prctl(ARCH_GET_FS, &my_TLS_zone); printf("(%d) my array V is at %p - " "my array V1 is at %p - " "my TLS zone is at %p\n", me, v, v1, my_TLS_zone);
Il thread con id = 1 ad un certo punto cambia la sua TLS zone con la TLS zone dell'altro thread e comincia a scrivere il valore 77 nell'array v.
if(me == 0){ // Tell the other thread the location of the thread's TLS zone. other_TLS = my_TLS_zone; } else{ memset(v, (int)77, 8); sleep(1); arch_prctl(ARCH_SET_FS, other_TLS); }
Eseguendo più volte il loop il thread con id = 1 non solo scrive nel proprio array v il valore 77, ma scrive lo stesso valore anche nell'array dell'altro thread.
5 x86-64 Control Registers
In x86 abbiamo dei registri chiamati registri di controllo che dicono al firmware come comportarsi a seconda degli eventi. In particulare abbiamo 5 registri di controllo, da CR0 a CR4.
Il registro CR0 è il registro di controllo baseline, ovvero quello che contiene le informazioni di base sulla modalità operativa del processore. Tra le altre cose che vengono specificate in CR0 troviamo anche la modalità utilizzata per indirizzare la memoria, che può essere real, protected o long. A seconda del valore di CR0 gli altri registri di controllo possono assumere determinati valori. In particolare i vari valori contenuti in CR0 sono
Un bit importante da tenere a mente è il bit WP, che sta per Write Protect. Quando andremo a fare hacking sul codice del kernel infatti sarà necessario disabilitarlo temporaneamente.
Altri registri di controllo utili sono:
Il registro CR2: mantiene l'indirizzo lineare dell'ultimo fault di memoria per il CPU-core corrente. Questo registro viene scritto dal firmware quando non ci sono le condizioni corrette per accedere alla memoria.
Il registro CR3: contiene l'indirizzo nella memoria fisica della page table, ed è utilizzato se in CR0 abbiamo specificato che stiamo lavorando in modalità paginata. Questo registro è anche chiamato il page table pointer.
6 Interrupts and Traps
Gli interrupts e le traps sono così descritti:
Gli interrupts sono eventi asincroni, richiesti non dal software ma dall'hardware, accettato dal firmware e processati via software.
Le traps, o le eccezioni, sono eventi sincroni, e accadono perché il software sta facendo qualche cosa si strano, come quando si prova a dividere per \(0\). Le traps vengono quindi generate e processate direttamente dal software. L'architettura x86 offre una istruzione software che genera una trap.
Storicamente le traps sono state utilizzate come meccanismo di on demand access alla modalità kernel al fine di eseguire le system calls.
Al fine di gestire correttamente traps e interrupts, il kernel
mantiene una tabella in cui sono presenti dei GATE descriptor, che
contengono informazioni riguardanti l'indirizzo associato al gate
(in forma segmentata
Osservazione: La trap/interrupt table viene scritta dal sistema operativo durante il processo di start-up. Può succedere che un dato gate sia descritto in entries multiple della trap/interrupt table, ciascuna delle quali con un diverso livello di protezione.
6.1 x86 Control Flow Variations
Abbiamo tre classi di control flow variations, che sono:
Intra-segment, (JMP
): Rappresenta un salto classico. Il firmware si occupa solo di verificare se il displacement richiesto si trova all'interno del segmento in cui si sta lavorando.
Cross-segment, (LJMP
, ) Il firmware in questo caso si occupa di verificare se il salto è valido confrontando la CPL con il DPL del segmento a cui vogliamo accedere. Una volta fatto quello il firmware controlla se il displacement è valido rispetto al limite del segmento.
Cross-segment via GATEs, (INT
)
Il firmware controlla se è possibile eseguire il salto confrontando il CPL con il livello di protezione associato al target GATE specificato all'interno della trap/interrupt table.
6.2 GATE Details for x86
La tabella dei trap/interrupt in x86 è chiamata Interrupt Descriptor Table (IDT). Ogni entry della IDT, grande dagli 8 ai 16 bytes, a seconda se stiamo lavorando in protected-mode or long-mode, contiene delle informazioni relative ai GATE, tra cui
L'ID del segmento target e il displacement all'interno del segmento (i.e. l'indirizzo segmentato associato al GATE).
Il livello massimo da cui è possibile accedere al GATE.
Se il codice attivabile dal GATE può essere interrotto o meno.
La tabella IDT è accessibile tramite il registro idtr, che può essere letto con l'istruzione LIDT e che contiene una packed structure con
L'indirizzo lineare della tabella IDT
La taglia della tabella.
7 Trap-Based On-Demand Kernel Access
Quando si parla di on-demand kernel access si sta intendendo l'abilità di passare dal ring 3 al ring 0 al fine di eseguire delle particolari porzioni del kernel, che sono state approvate e controllate.
7.1 Conventional Method
Storicamente per i sistemi operativi LINUX/Windows l'accesso tramite GATE al ring 0 è sempre stato unico, nel senso che è sempre esistita una sola entry all'interno della tabella IDT associata all'on-demand access to the kernel.
Per le macchine i386, le software traps sono
INT 0x80, per linux (con backward compatibility in x86-64);
INT 0x2E, per Windows.
Tutti gli altri GATE vengono utilizzati per gestire run-time errors e interrupt generali.
Il modulo software associato con l'accesso on-demand al kernel implementa un dispatcher in grado di attivare l'esecuzione di una specifica system call che vuole essere eseguita dall'applicazione che gira in user-mode. Lo schema da tenere a mente è il seguente

7.2 System Call Table
La system call table viene utilizzata per associare ai vari numerical codes offerti dal kernel gli indirizzi delle reali implementazioni delle system calls. Questi indirizzi vengono utilizzati dal dispatcher al fine di eseguire una specifica system call.
Per capire a quale entry accedere, il dispatcher prende in input il numero (numerical code) associato alla system call che si vuole eseguire. Tipicamente questo input viene passato al dispatcher tramite un registro della CPU.
Il codice numerico identifica una entry della system call table. Leggendo la tabella il dispatcher è in grado di invocare la corretta system call tramite una jmp sub-routine (call instruction on x86).
La system call, una volta eseguita, produce il suo output all'interno di un CPU register, passa il controllo al dispatcher che nuovamente passa il controllo all'applicazione che lo aveva inizialmente chiamato.
7.3 Modificare la system call table
Per modificare la system call table dobbiamo
Capire dove si trova in memoria, anche nel caso in cui c'è la randomizzazione durante la fase di start-up delle strutture dati utilizzate dal kernel.
Capire se c'è una entry vuota nella tabella, ovvero capire se esiste un codice numerico disponibile a cui associare una nuova routine.
Notiamo che, tipicamente, la system call table non può essere ampliata in modo semplice, in quanto molto spesso la system call table viene memorizzata adiacente a qualche altra struttura dati utilizzata dal kernel.