AOS - 29 - TRAP/INTERRUPT ARCHITECTURE I
Lecture Info
Data:
Sito corso: link
Progresso unità: 1/2
Argomenti:
Single-Core Interrupts
Multi-Core Interrupts Issues
Inter Process Interrupts (IPIs)
APIC, LAPIC e I/O APIC
IDT
IDT Entries (i386 e x86-64)
Spurious Interrupts
Trap/Interrupts Handlers
Introduzione: Andiamo adesso a introdurre un nuovo argomento, quello dell'architettura trap/interrupt. In particolare vogliamo capire: da dove arrivano gli interrupts, come arrivano, e cosa rappresentano? Come dobbiamo scrivere il codice relativo agli interrupts?
1 Single-Core Concepts
Abbiamo sempre assunto che il CPU-core che riceve il trap o l'interrupt è l'unico coinvolto in questa attività di gestione della trap/interrupt. Questa visione è tipica di un sistema single-core. In questa visione del mondo abbiamo che,
La trap è un evento sincrono causato dal flusso di esecuzione del thread.
L'interrupt è un evento asincrono generato da un dispositivo esterno.
In entrambi i casi abbiamo sempre assunto che le attività eseguite per la gestione dell'evento sono definitivamente visibili all'interno di tutto il sistema. Nel caso in cui consideriamo le attività di una singola CPU, questa assunzione è verificata, sia nel caso degli interrupts e sia nel caso delle traps, in quanto cambiamenti dello stato dall'hardware per la gestione dell'interrupt sono visibili a tutti i thread che andranno nel futuro ad eseguire sullo stesso CPU-core.
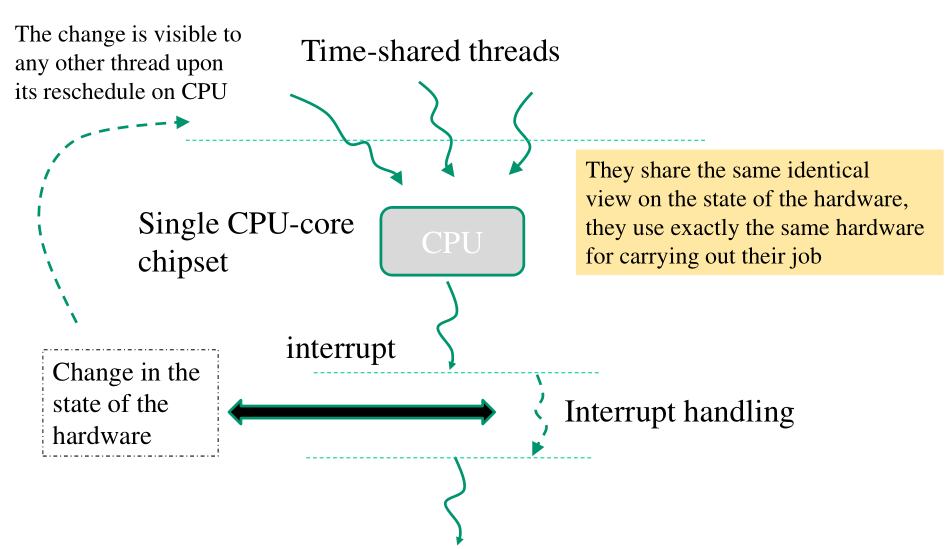
Questa ipotesi però non è più valida nel momento in cui ci troviamo
in sistemi multi-core. In sistemi multi-core ad esempio può
succedere che in una applicazione multi-threaded un thread, che gira
sul CPU core 0, esegue una mmap() per togliere delle porzioni di
memoria dalla page table, mentre un altro thread, che gira su un
altro CPU-core, non è in grado di vedere il cambiamento di stato
ottenuto dall'esecuzione della trap.

2 Issues with Multi-Core
Il problema fondamentale che dobbiamo risolvere è quindi quello di propagare i cambiamenti di stato di un CPU-core agli altri CPU-core. Solo in questo modo siamo in grado di supportare delle applicazioni multi-threaded i cui threads possono girare su più CPU-cores in modo concorrente. In altre parole, le attività associate agli interrupt devono essere in grado di propagarsi agli altri CPU-cores.
Possiamo propagare e gestire una trap/interrupt tra più CPU-cores in due modi:
A livello firmware, con regole deterministiche codificate nell'hardware; Tipicamente però questo supporto è offerto solamente per gestire le situazioni deterministiche più semplici.
A livello software, con regole codificate nel sistema operativo.
L'idea è che l'hardware mi permette di propagare un dato interrupt ai vari CPU-cores del sisteme, mentre il software si occupa di gestire le attività da scolgere per gestire gli interrupt propagati.
3 Inter Process Interrupt (IPI)
Il supporto minimale per propagare gli interrupts da un CPU-core ad un altro è dato dal supporto degli IPI, che sono un terzo tipo di eventi (dalle traps e interrupts), e che possono triggerare l'esecuzione di specifico software al livello del sistema operativo in qualsiasi CPU-core.
Un IPI è un evento sincrono per il CPU-core che lo invia, ed è un evento asincrono per il CPU-core che lo rieve.
Le richieste IPI vengono utilizzate per implementare cross CPU-core activities (request/reply protocol cross-cpu) oppure per portare un cambiamento alla porzione hardware visibile solamente da altri CPU-core (flush della TLB, flush della cache L1).
Anche se gli IPIs sono generati a livello firmware, il loro processamento viene eseguito a livello software. É dunque possibile implementare dei livelli di priorità per i vari IPIs. Tipicamente abbiamo due livelli di priorità:
High: Per gli eventi IPIs in cui il request/reply protocol è sincrono. Questi IPIs vengono processati immediatamente da chi li riceve. In un dato istante ci può essere un solo request/reply protocol associato ad un IPI con priorità high.
Low: Per scenari meno critici, ovvero per gli eventi IPIs che vengono processati in modo asincrono.
4 Advanced Programmable Interrupt Controller (APIC)
Nell'architettura x86, il supporto firmware di base per la gestione degli interrupt è chiamato APIC, che sta per Advanced Programmable Interrupt Controller.
Questo supporto offre ad ogni CPU-core una istanza locale del controller, che prende il nome di LAPIC (Local APIC). Il supporto LAPIC offre un timer programmabile a livello di CPU-core, che prende il nome di LAPIC-T che abbiamo già incontrato nella discussione del time-sharing. La CPU può parlare con il proprio controller LAPIC scrivendo su determinati pseudo-registri per inviare delle richieste IPI che girano all'interno di un bus specifico per il sistema APIC.
Oltre ai vari LAPIC, uno per ogni CPU-core, abbiamo poi il componente I/O APIC, che si occupa di ricevere gli interrupt dai dispositivi e di inviarli ai CPU-cores. Lo schema architetturale è quindi il seguente
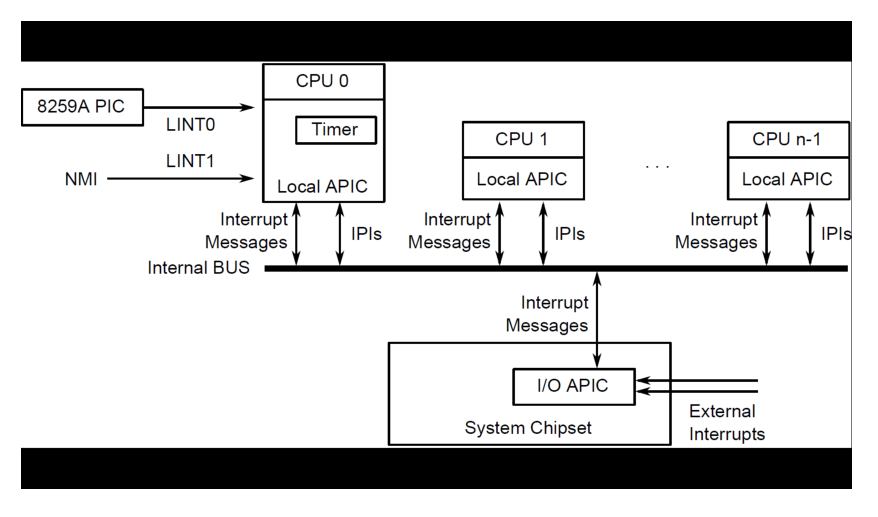
La comunicazione tra i vari LAPIC per la generazione di IPI avviene nel seguente modo:
Un CPU-core scrive in un model-specific register relativo al componente LAPIC a lui associato.q
Il componente LAPIC legge i registri, prende il controllo del bus, e invia l'IPI nel bus.
L'IPI è contenuto in un frame che specifica varie cose, tra cui quali CPU-core devono ricevere l'evento. I vari LAPIC leggono questo frame e decidono se propagarlo o meno al proprio CPU-core.
Per gestire gli interrupt da dispositivi esterni possiamo programmare l'I/O APIC su come gestire i vari interrupts.
Per gestire gli interrupt da dispositivi esterni possiamo programmare l'I/O APIC su come gestire i vari interrupts.
4.1 IRQ vs INT
Il dispositivo esterno I/O APIC ci permette di distinguere fino a \(255\) linee differenti di richieste di interrupts. Alcune di queste linee non sono programmabili a piacere ma sono associate a specifici device. Per fare un esempio, la linea IRQ 1 è associata alla keyboard.
Andiamo adesso ad introdorre una differenza di notazione molto importante:
Con IRQ (Interrut Request) intendiamo il codice associato alla richiesta di interrupt visibile dall'I/O APIC, e quindi che dipende dalla configurazione dell'hardware.
Con INT (Interrupt Line) invece intendiamo il codice dell'interrupt, o della trap, per come è visto dal software del kernel del sistema operativo.
Tra INT e IRQ c'è una relazione del tipo INT = F(IRQ), dove la
funzione F() è determinata dalle specifiche dell'hardware. Per i
processori x86 troviamo
\[\text{INT} = \text{IRQ} + 32\]
Le prime \(32\) linee di interrupt visibili dal software sono quindi riservate per le traps predefinite dall'architetture dell'hardware.
4.2 I/O APIC
Il dispositivo I/O APIC tiene conto di quante CPU sono presenti nel chipset e permette di inviare interrupts in modo selettivo ai diversi CPU-cores. Per identificare i CPU-cores utilizza il concetto di local APIC-ID.
Il dispositivo supporta due tipi di operazioni:
Fixed/physical operations: consistono nell'invio di interrupts da un certo device ad un singolo, predefinito, CPU-core.
Logical/low priority operations: consistono dell'invio di interrupts da determinati device a multipli CPU-cores in modalità round robin.
Il numero di CPU targettabili possono essere al più \(8\), e questo limite è riconducibile all'hardware.
Per terminare, l'interfaccia APIC può essere vista utilizzando lo pseudo file system: dai seguenti file
/proc/interrupts /proc/irq/<IRQ#>/smp_affinity
Il setup del dispositivo I/O APIC è hardcoded nelle regole di boot
del kernel ed è generalmente visibile tramite dmesg .
5 Interrupt Descriptor Table (IDT)
In x86 protected-mode la IDT può avere al massimo \(256\) entries, ovvero \(256\) interrupt handlers. Il size delle singole entry dipende dalla versione dell'architetture: su x86 protected-mode ogni entry è formata da \(32\) bits, mentre su x86-long ogni entry ha più bit.
Per ottenere l'indirizzo e il size della IDT è possibile utilizzare il registro \(idtr\) (interrupt descriptor table register), che memorizza una packed structure contenente le seguenti informazioni:
L'indirizzo virtuale della IDT (espresso con al più 6 bytes, ovvero 48 bits).
Il numero di entry attualmente presenti nella IDT (espresso con al più 2 bytes, ovvero 16 bits).
Per manipolare questa packed structure possiamo utilizzate le
istruzioni offerte dall'ISA di x86 lidt (load IDT) e sidt (store
IDT).
5.1 IDT Entries Usage in Linux
In genere su linux le entry della tabella IDT vengono utilizzate nel seguente modo
Le prime \(32\) entries vengono utilizzate per gestire le execeptions (software traps). Alcune di queste entry sono riservate al firmware, e non vengono toccate dal software.
A partire dalla \(32\) fino alla \(127\) possiamo installare descrittori di handler che permettono al sistema operativo di gestire il particolare evento generato da dispositivi esterni.
Verso la parte finale della tabella abbiamo i gestori degli inter-processor-interrupts.
Segue una tabella più completa di quanto appena descritto, osservando che al cambiare della versione del KERNEL cambia anche il particolare modo in cui questa tabella è suddivisa.
5.2 Spurious Interrupts
Indipendentemente se un evento è gestito o meno, ogni entry vuota ha comunque un gestore di default, che non fa altro che ritornare il controllo. Questo gestore è fondamentale, in quanto permette al SO di sapere cosa fare anche nel caso in cui quel particolare interrupt, per qualche ragione, come ad esempio a causa di un bit flip, si manifesta.
Abbiamo quindi la possibilità di avere degli spurious interrupts. Le entry associate agli spurious interrupts sono entry libere.
5.3 IDT Entries
A seconda della versione abbiamo delle entry diverse.
5.3.1 x86 protected mode
Su x86 protected mode le entries della IDT sono rappresentate da
una struttura dati contenente 32 bit di informazioni. Questa
struttura dati è formata da due bitmask di tipo unsigned long , ed
è definita nel file include/asm-i386/desc.h
struct dest_struct { unsigned long a, b; }
Segue la struttura dettagliata delle informazioni contenute nelle due bitmasks:
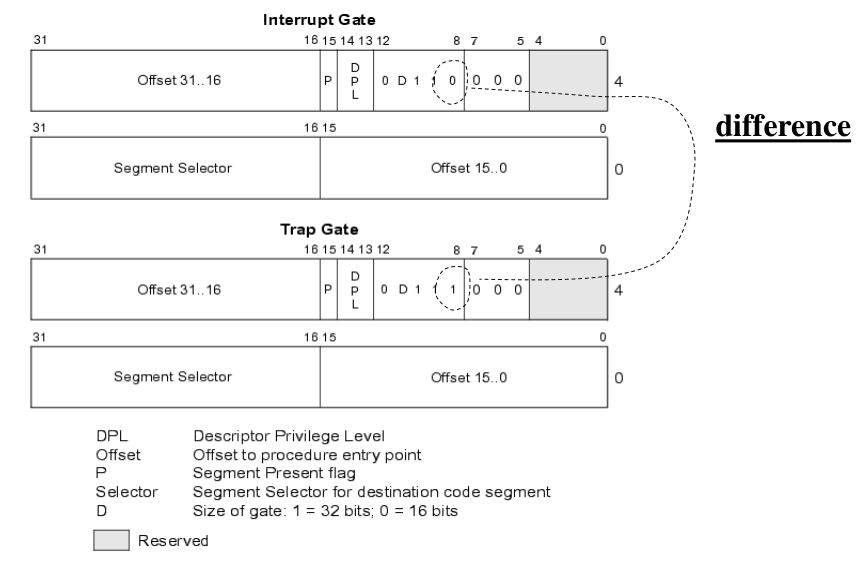
Dove i vari campi sono così descritti
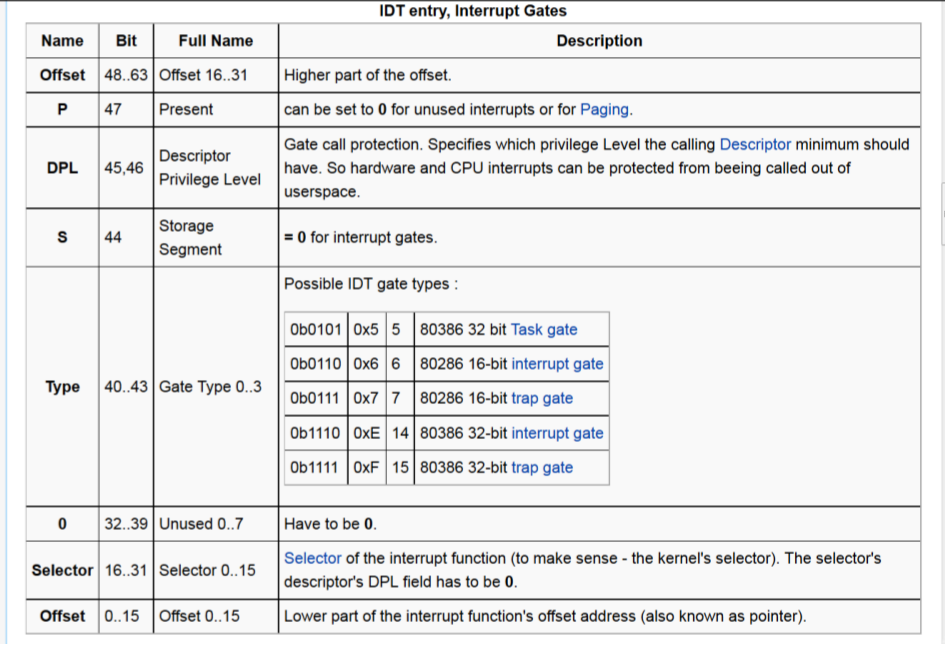
Notiamo come l'ottavo bit viene utilizzato per indicare al firmware che il CPU-core deve eseguire l'handler in modo interrompibile, o non interrompibile: se il firmware trova 0, l'handler girerà in modo interrompibile, e viceversa.
Osservazione: Dato che in linux la maggior parte dei segmenti sono mappati partendo da 0, l'offset memorizzato nella IDT entry è uguale all'indirizzo logico della funzione nello spazio di indirizzamento lineare. Dunque, è possibile utilizzare l'operatore &, che utilizza un displacement a partire da 0x0 per impostare l'offset nel GATE.
5.3.2 x86-64
In modalità long mode le entry della IDT sono più grandi, in quanto gli offset per specificare gli handlers sono inevitabilmente più grandi. Alcune entry della tabella sono poi reserved per sviluppi future, mentre altre sono nuove rispetto a quelle presenti nella versione a 32 bit.
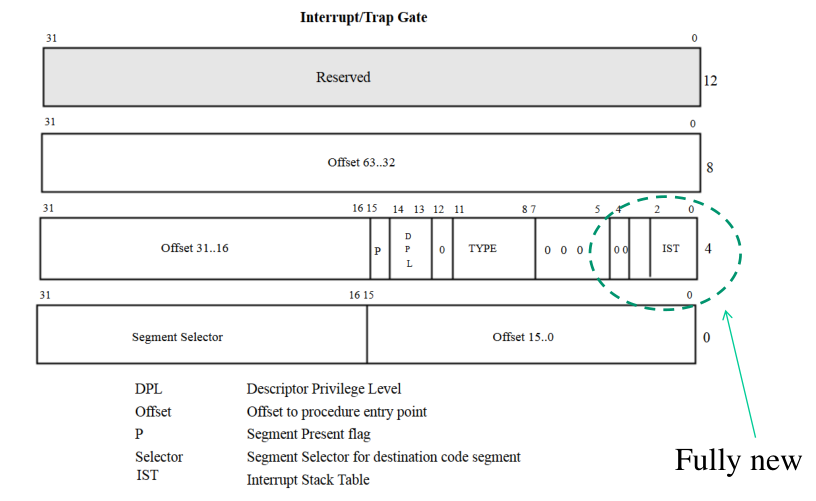
Nelle entry della IDT su x86 protected mode non avevamo nessun tipo di informazione sullo stack da utilizzare per gestire l'interrupt. Per capire su quale stack eseguire l'interrupt si utilizzava la regola di default, che faceva a sua volta utilizzo del TSS per ottenere le informazioni sullo stack pointer a seconda del livello di privilegio in cui stiamo eseguendo.
In modalità long-mode si è pensato di aggiungere questo tipo di informazioni introducendo il concetto di IST (Interrupt Stack Table). La IST è una tabella memorizzata nel TSS che contiene una serie di puntatori a degli stack di sistema che possono essere utilizzati per iniziare l'esecuzione del gestore dei trap/interrupt. Nelle IDT entry in modalità long-mode possiamo programmare l'indice da utilizzare nella IST per prendere il relativo stack. La IST in particolare permette di specificare 7 puntatori a stack diversi. Molto spesso gli stack identificati tramite la IST sono stack temporanei.
Questo meccanismo, che prende il nome di stack de-routing, è stato introdotto per avere una maggiore flessibilità nella gestione dei trap/interrupts. Permette inoltre di avere una maggiore separazione tra gli stack utilizzati per eseguire i threads e quelli utilizzati per eseguire gli handler degli interrupts.
Per accedere all'indirizzo del GATE di una IDT entry in long mode possiamo utilizzare le seguenti software facilities che compattano in modo specifico le informazioni contenute nelle entry.
#define HML_To_ADDR(h, m, l) \ ((unsigned long) (l) | ((unsigned long) (m) << 16) | \ ((unsigned long) (h) << 32)) // ------------------------------------------------- // using gate descriptor structure // ------------------------------------------------- gate_desc *gate_ptr; // gate_ptr = ...; HML_TO_ADDR(gate_ptr->offset_high, gate_ptr->offset_middle, gate-ptr->offset_low);
5.4 IDT APIs
Per andare a settare il contenuto delle entry della IDT possiamo utilizzare delle facilities offerte dal kernel. Queste cambiano a seconda se lavoriamo x86-protected mode o x86-long mode. Notiamo in ogni caso che oltre alle entry riservate dal firmware stesso, tutte le altre possono essere modificate liberamente dal kernel.
Per x86 protected mode abbiamo le seguenti APIs. In tutte queste
APIs abbiamo che displacement rappresenta la target entry della
IDT, mentre &symbol_name identifica l'indirizzo logico del modulo
software che dovrà essere invocato per gestire la trap/interrupt.
set_trap_gate(): sets privilege level 0 for accessing the GATE via software.
set_trap_gate(displacement, &symbol_name);set_intr_gate(): similar to set_trap_gate() however the handler activation relies on interrupt making, and therefore it cannot be interrupted during its execution.
set_intr_gate(displacement, &symbol_name);set_system_gate(): similar to set_trap_gate(), but defines the value 3 as the level of privilege admitted for accessing the GATE.
set_system_gate(displacement, &symbol_name);
Per quanto riguarda x86 long mode, abbiamo le seguenti APIs:
set_system_intr_gate():
static inline void set_system_intr_gate(unsigned int n, void *addr) { BUG_ON((unsigned)n > 0xFF); _set_gate(n, GATE_INTERRUPT, addr, 0x3, 0, __KERNEL_CS); }
set_system_trap_gate():
static inline void set_system_trap_gate(unsigned int n, void *addr) { BUG_ON((unsigned)n > 0xFF); _set_gate(n, GATE_TRAP, addr, 0x3, 0, __KERNEL_CS); }
set_trap_gate():
static inline void set_trap_gate(unsigned int n, void *addr) { BUG_ON((unsigned)n > 0xFF); _set_gate(n, GATE_TRAP, addr, 0, 0, __KERNEL_CS); }
6 Trap/Interrupts Handlers
Per la gestione di alcune traps (codici da \(0\) a \(31\)), il firmware passa al gestore dell'interrupt un codice di errori per comunicare la causa che ha fatto scatenare l'interrupt. Un segmentation fault ad esempio può accadere per varie ragioni:
la memoria che volevamo accedere non era mappata;
era mappata ma i permessi non ci hanno permesso di leggerla;
Tutte queste informazioni devono essere passate dal firmware al gestore della trap tramite l'utilizzo dello stack.
Il passaggio degli errori-codes non è deterministico, in quanto, per le entries non-reserved, il firmware non genera nessun tipo di error-code. Il gestore dell'interrupt deve quindi essere aware se il firmware gli passerà anche un error-code. Questo crea un problema di stack allignment. Per gestire questo problema si attua una politica di allignment della stack andando ad introdurre a livello software, per tutti i casi in cui il firmware non passa un error-code, una dummy value.
Quando arriva una trap quindi l'handler si deve porre le seguenti domande:
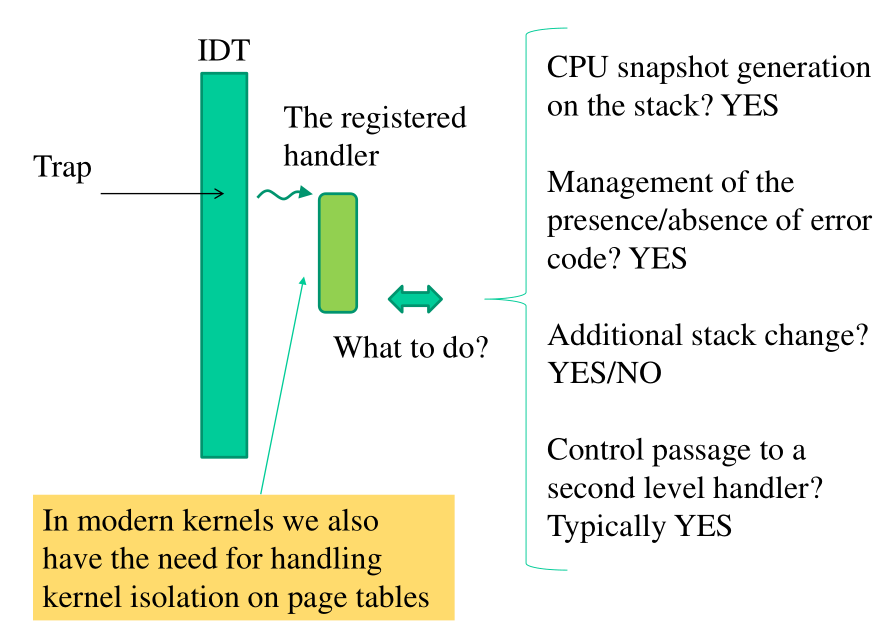
Il passaggio ad un handler di secondo livello viene svolto per motivi di portabilità. Infatti, dato che le operazioni iniziali eseguite dallo handler sono architecture-dependant, una volta eseguite si vuole passare il controllo ad un blocco di codice scritto in tecnologia C e quindi indipendente dalla particolare architettura che stiamo utilizzando. Questo permette una maggiore flessibilità nella scrittura del codice di gestione della trap/interrupt.
6.1 Page Table Isolation
Per vie delle recenti vulnerabilità Spectre e Meltdown, quando entriamo in modo kernel per gestire un interrupt dobbiamo anche cambiare la page table utilizzata per utilizzare la page table del kernel. Quindi l'handler intermedio che poi porta all'esecuzione dell'handler effettivo per la gestione dell'interrupt si deve pure occupare di cambiare la page table.
Per poter essere eseguiti, questi handler fanno parte della porzione di kernel che è visibile anche tramite la page table lato user. Questo è inevitabile, in quanto per cambiare la page table necessitiamo di eseguire quel pezzo di codice.
Notiamo che questo fatto ci crea dei problemi nel momento in cui
andiamo a scrivere un nuovo gestore per una trap o un interrupt
utilizzando la tecnologia dei moduli linux. Infatti, utilizzando la
tecnologia dei moduli, quando andiamo a montare il modulo nella
memoria del kernel, il kernel tipicamente utilizza funzioni come
vmalloc() . Questo vuol dire che la memoria associata all'handler non
è visibile in modalità user, ma solo in modalità kernel.
6.2 Top-Level Interrupts Handlers
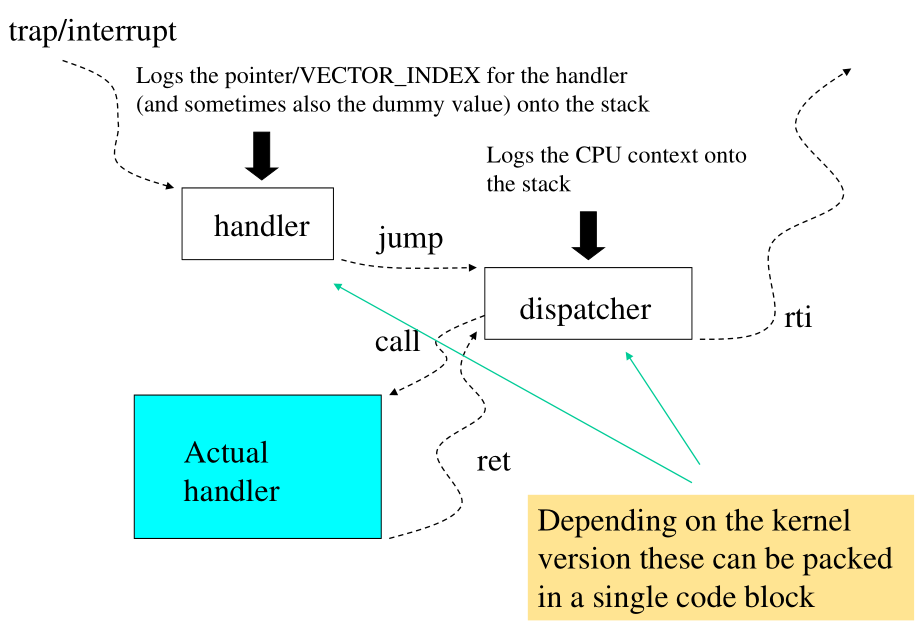
Come abbiamo menzionato prima, l'architettura per la gestione dei traps/interrupts si basa sul fatto che, tra tutte le operazioni da fare, alcune sono machine-dependent e altre no.
L'idea è quindi quella di avere un dispatching modulare delle attività da eseguire, e si basa sul definire un primo pre-handler che esegue le attività a scelta (YES/NO), e un secondo pre-handler, chiamato dispatcher, che esegue sempre una serie di attività machine-dependent. Alla fine il dispatcher chiama l'handler effettivo da eseguire, che può essere scritto in tecnologia C.
Il codice machine-dependent in cui sono definiti i primi
pre-handlers si trova nel file arch/i386/kernel/entry.S . Le azioni
eseguite dagli handlers sono le seguenti:
In case no error-code is generated, log a dummy-value into the stack to correctly allign the stack.
Logs the address of the actual handler-function. In more recent versions in this step the handler logs a VECTOR_INDEX for access to the vector of function pointers.
Una volta che sono state eseguite queste azioni, viene attivato un modulo assembly di default, il dispatcher, che esegue le seguenti azioni:
Logs the CPU context into the stack.
Gives control to the actual handler via conventional call.
Notiamo che dato che i parametri di input sono passati tramite lo stack, la funzione per la gestione dell'handler deve essere compilata con la keyword asmlinkage. Lo schema logico appena descritto è così visualizzato